

PubMedPortable: A Framework for Supporting the Development of Text Mining Applications
- PMID: 27706202
- PMCID: PMC5051953
- DOI: 10.1371/journal.pone.0163794
PubMedPortable: A Framework for Supporting the Development of Text Mining Applications
Abstract
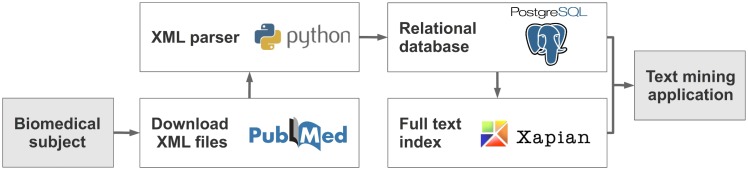
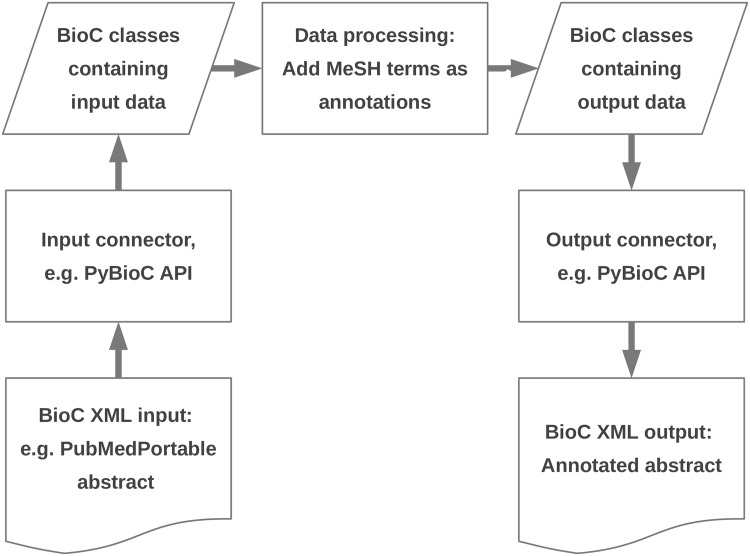
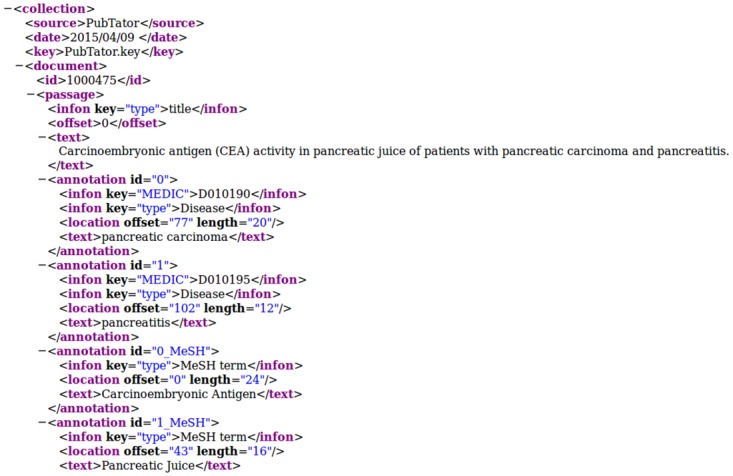
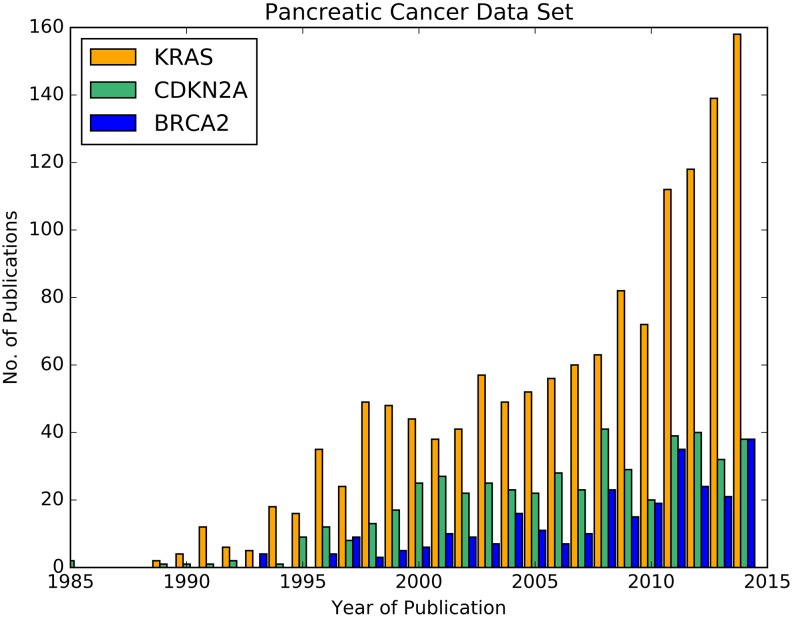
Information extraction from biomedical literature is continuously growing in scope and importance. Many tools exist that perform named entity recognition, e.g. of proteins, chemical compounds, and diseases. Furthermore, several approaches deal with the extraction of relations between identified entities. The BioCreative community supports these developments with yearly open challenges, which led to a standardised XML text annotation format called BioC. PubMed provides access to the largest open biomedical literature repository, but there is no unified way of connecting its data to natural language processing tools. Therefore, an appropriate data environment is needed as a basis to combine different software solutions and to develop customised text mining applications. PubMedPortable builds a relational database and a full text index on PubMed citations. It can be applied either to the complete PubMed data set or an arbitrary subset of downloaded PubMed XML files. The software provides the infrastructure to combine stand-alone applications by exporting different data formats, e.g. BioC. The presented workflows show how to use PubMedPortable to retrieve, store, and analyse a disease-specific data set. The provided use cases are well documented in the PubMedPortable wiki. The open-source software library is small, easy to use, and scalable to the user's system requirements. It is freely available for Linux on the web at https://github.com/KerstenDoering/PubMedPortable and for other operating systems as a virtual container. The approach was tested extensively and applied successfully in several projects.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures



Similar articles
-
FamPlex: a resource for entity recognition and relationship resolution of human protein families and complexes in biomedical text mining.BMC Bioinformatics. 2018 Jun 28;19(1):248. doi: 10.1186/s12859-018-2211-5. BMC Bioinformatics. 2018. PMID: 29954318 Free PMC article.
-
tmBioC: improving interoperability of text-mining tools with BioC.Database (Oxford). 2014 Jul 25;2014:bau073. doi: 10.1093/database/bau073. Print 2014. Database (Oxford). 2014. PMID: 25062914 Free PMC article.
-
Beyond accuracy: creating interoperable and scalable text-mining web services.Bioinformatics. 2016 Jun 15;32(12):1907-10. doi: 10.1093/bioinformatics/btv760. Epub 2016 Feb 16. Bioinformatics. 2016. PMID: 26883486 Free PMC article.
-
BioC interoperability track overview.Database (Oxford). 2014 Jun 30;2014:bau053. doi: 10.1093/database/bau053. Print 2014. Database (Oxford). 2014. PMID: 24980129 Free PMC article. Review.
-
A survey on annotation tools for the biomedical literature.Brief Bioinform. 2014 Mar;15(2):327-40. doi: 10.1093/bib/bbs084. Epub 2012 Dec 18. Brief Bioinform. 2014. PMID: 23255168 Review.
Cited by
-
A semantic-based workflow for biomedical literature annotation.Database (Oxford). 2017 Jan 1;2017:bax088. doi: 10.1093/database/bax088. Database (Oxford). 2017. PMID: 29220478 Free PMC article.
-
Automated recognition of functional compound-protein relationships in literature.PLoS One. 2020 Mar 3;15(3):e0220925. doi: 10.1371/journal.pone.0220925. eCollection 2020. PLoS One. 2020. PMID: 32126064 Free PMC article.
References
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
