

Explaining Support Vector Machines: A Color Based Nomogram
- PMID: 27723811
- PMCID: PMC5056733
- DOI: 10.1371/journal.pone.0164568
Explaining Support Vector Machines: A Color Based Nomogram
Abstract
Problem setting: Support vector machines (SVMs) are very popular tools for classification, regression and other problems. Due to the large choice of kernels they can be applied with, a large variety of data can be analysed using these tools. Machine learning thanks its popularity to the good performance of the resulting models. However, interpreting the models is far from obvious, especially when non-linear kernels are used. Hence, the methods are used as black boxes. As a consequence, the use of SVMs is less supported in areas where interpretability is important and where people are held responsible for the decisions made by models.
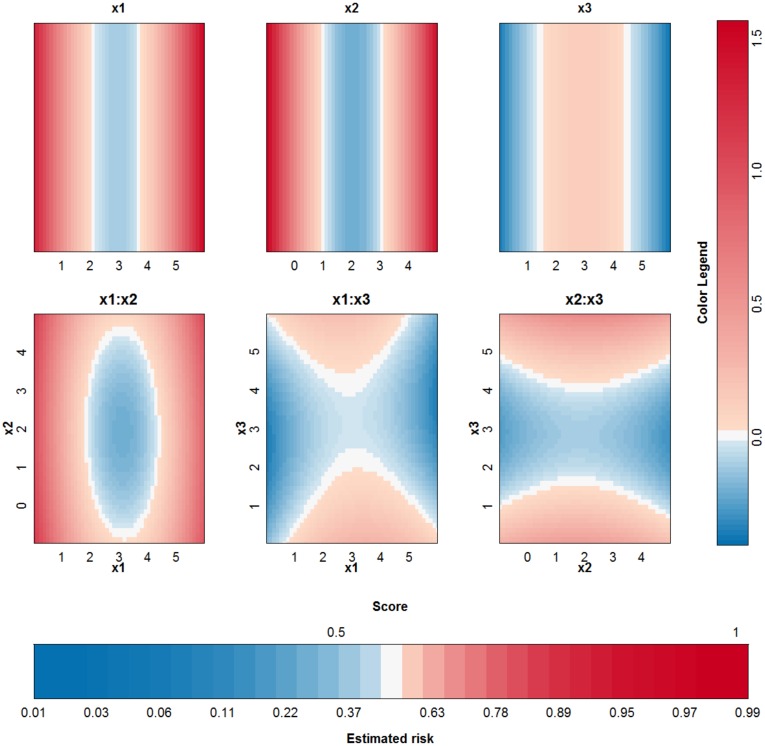
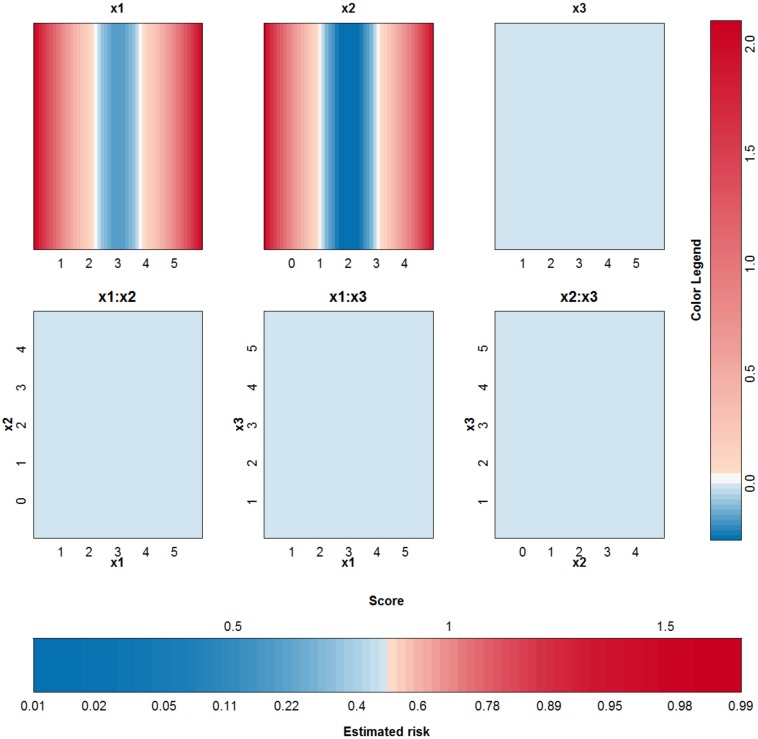
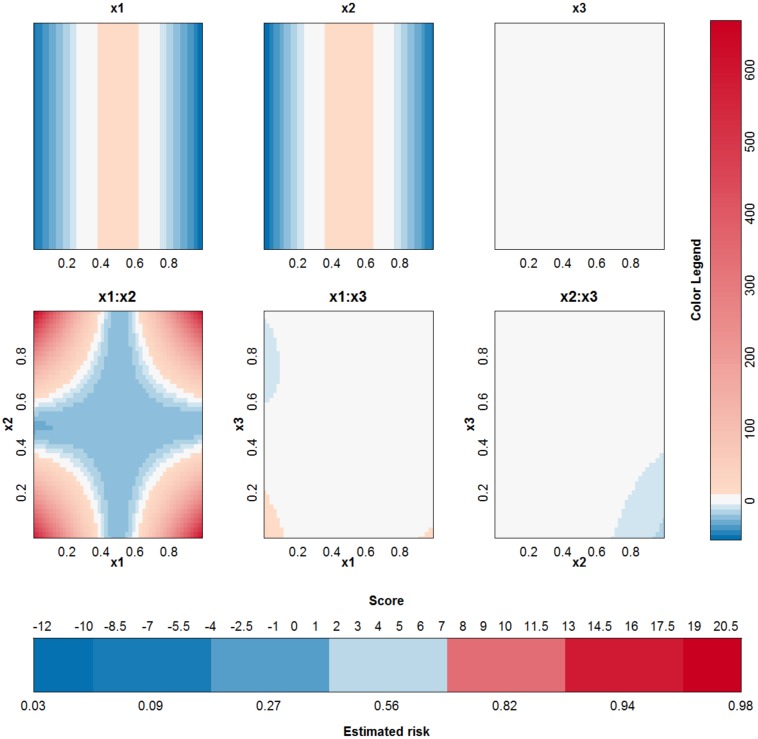
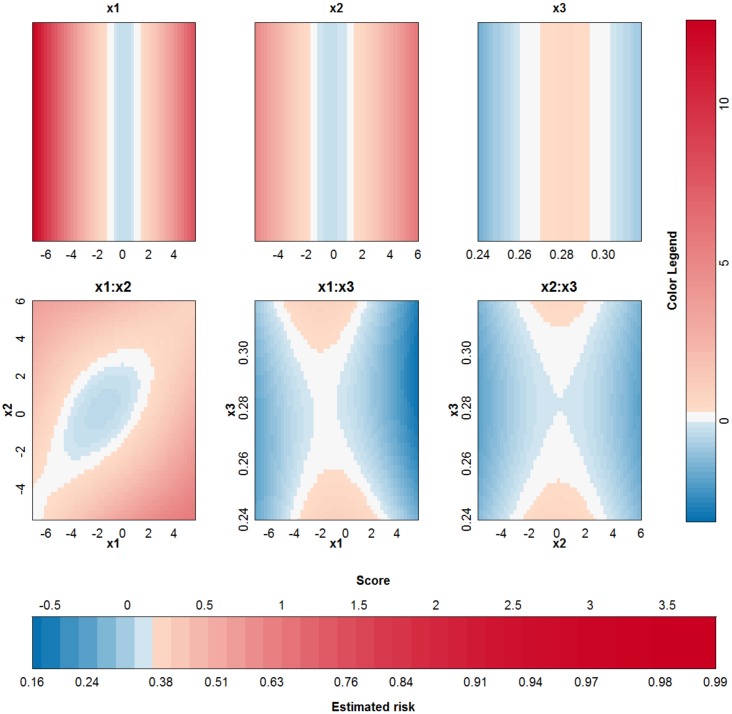
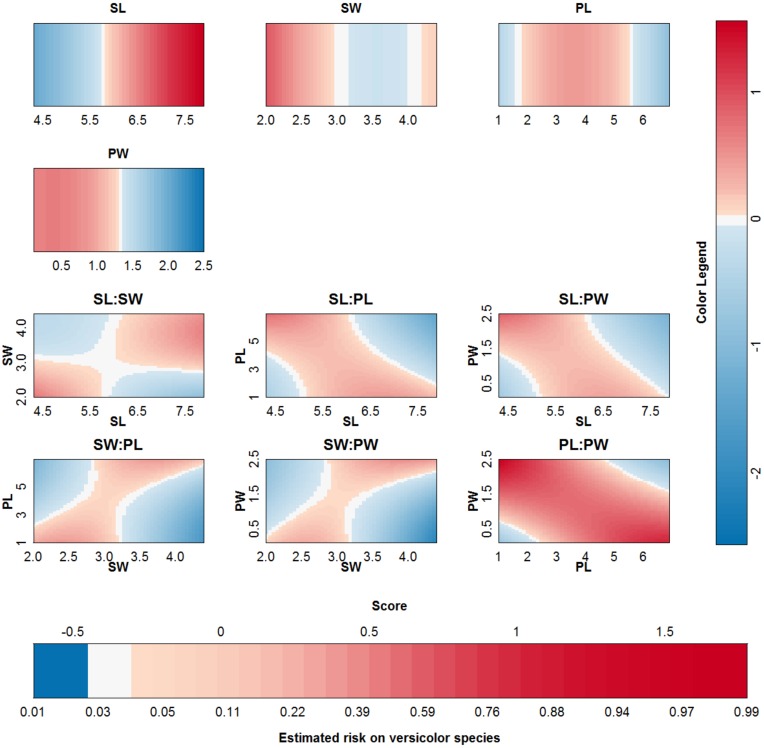
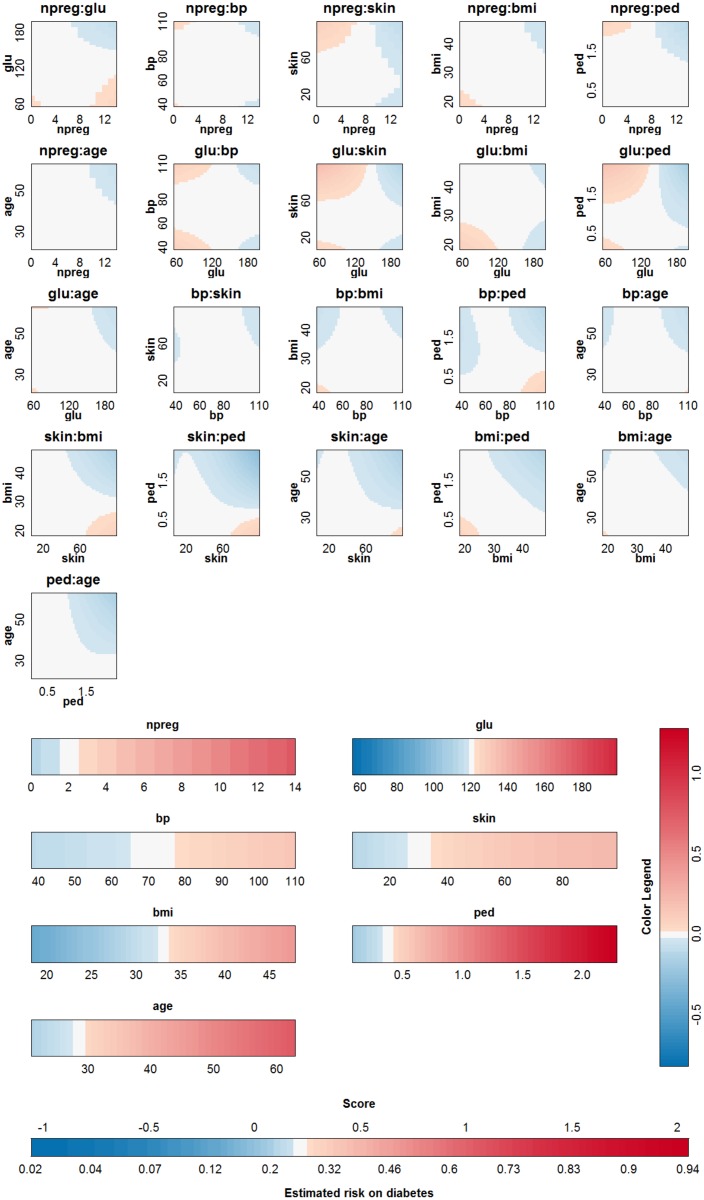
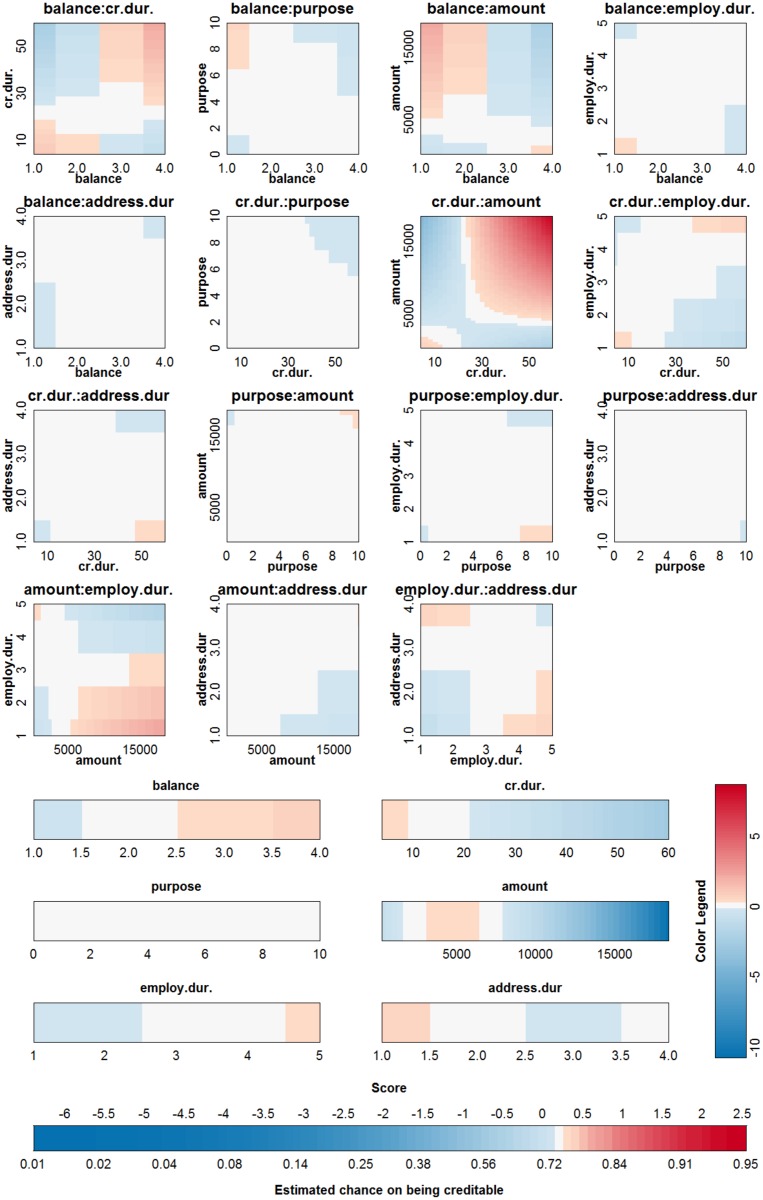
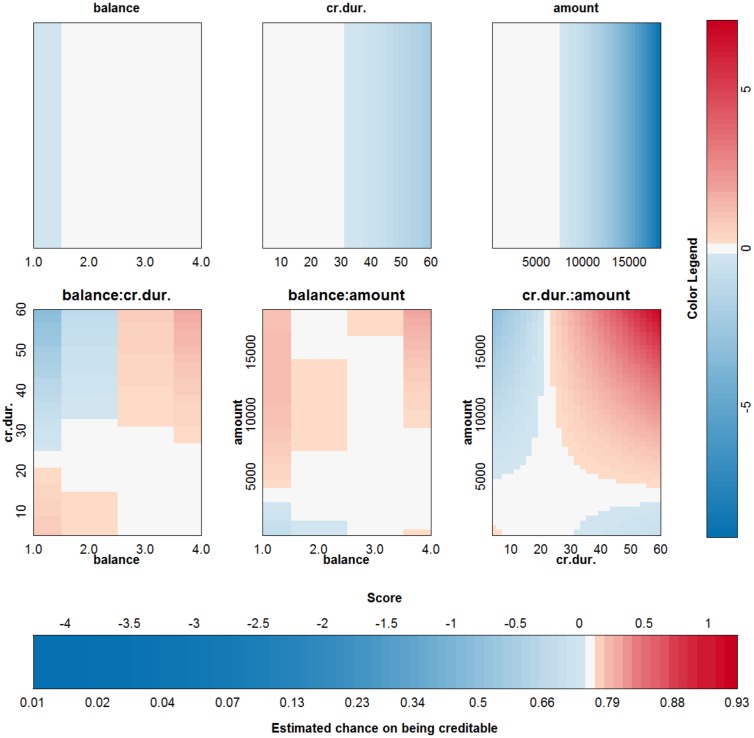
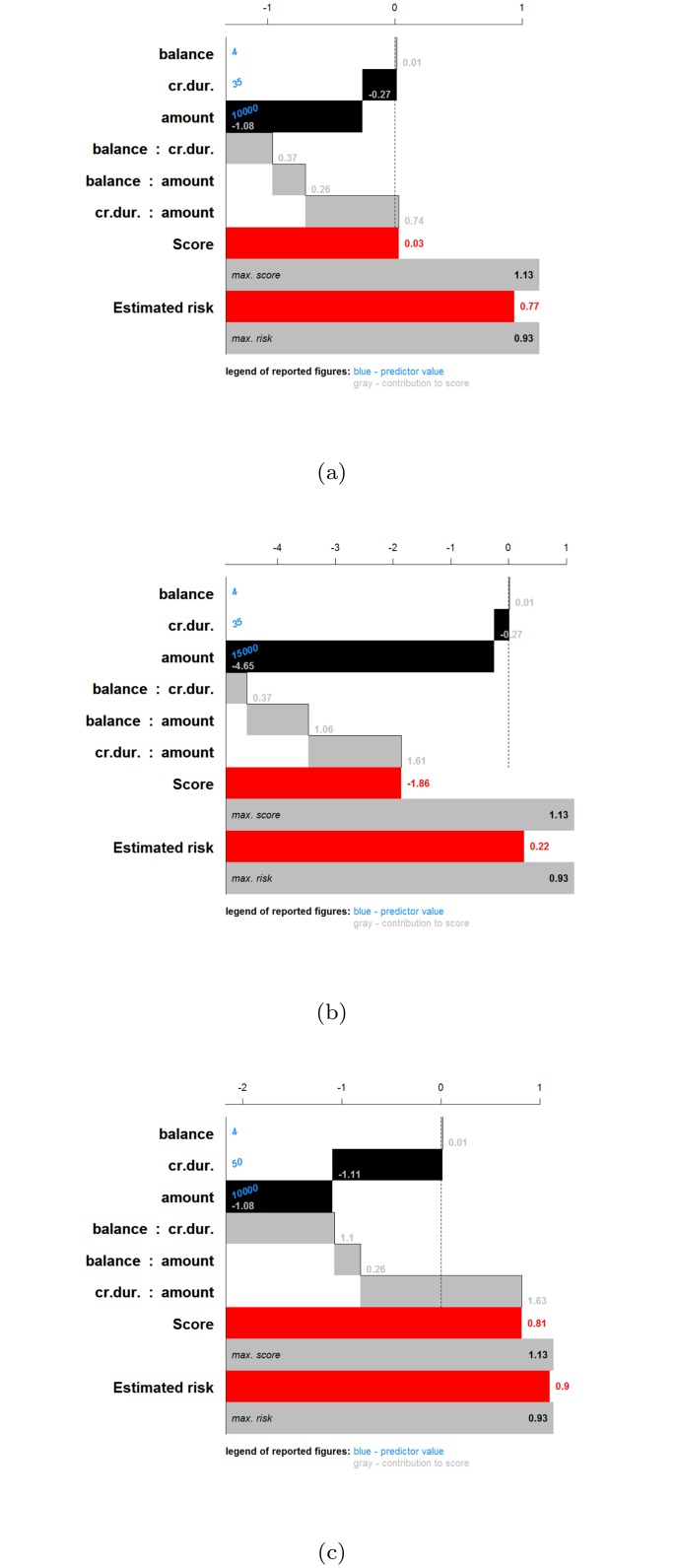
Objective: In this work, we investigate whether SVMs using linear, polynomial and RBF kernels can be explained such that interpretations for model-based decisions can be provided. We further indicate when SVMs can be explained and in which situations interpretation of SVMs is (hitherto) not possible. Here, explainability is defined as the ability to produce the final decision based on a sum of contributions which depend on one single or at most two input variables.
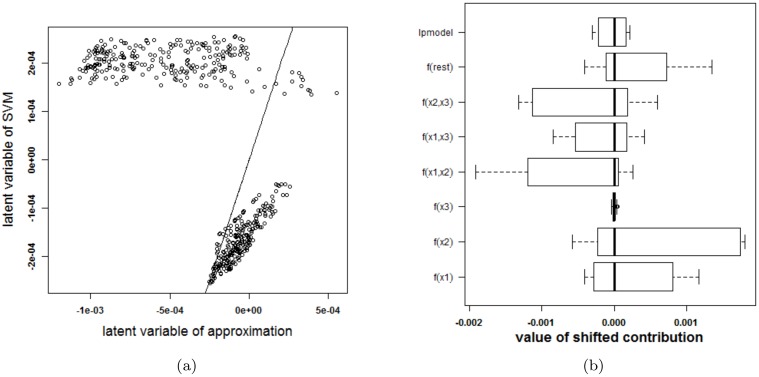
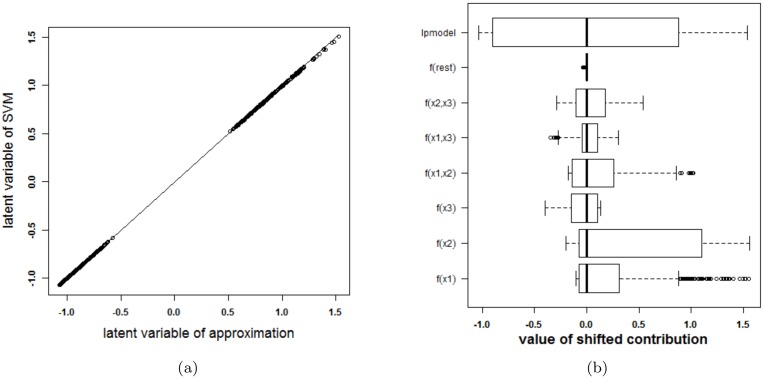
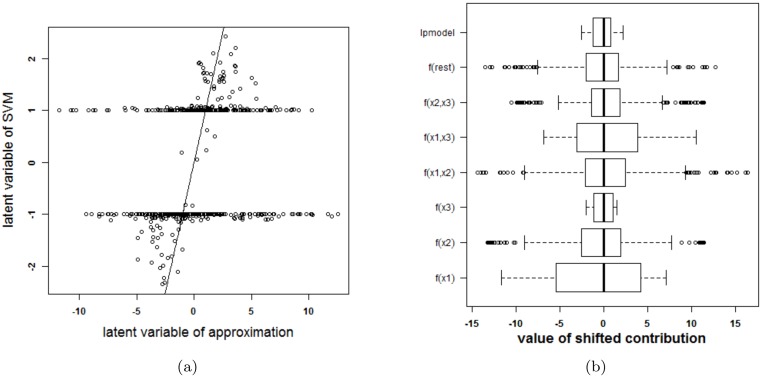
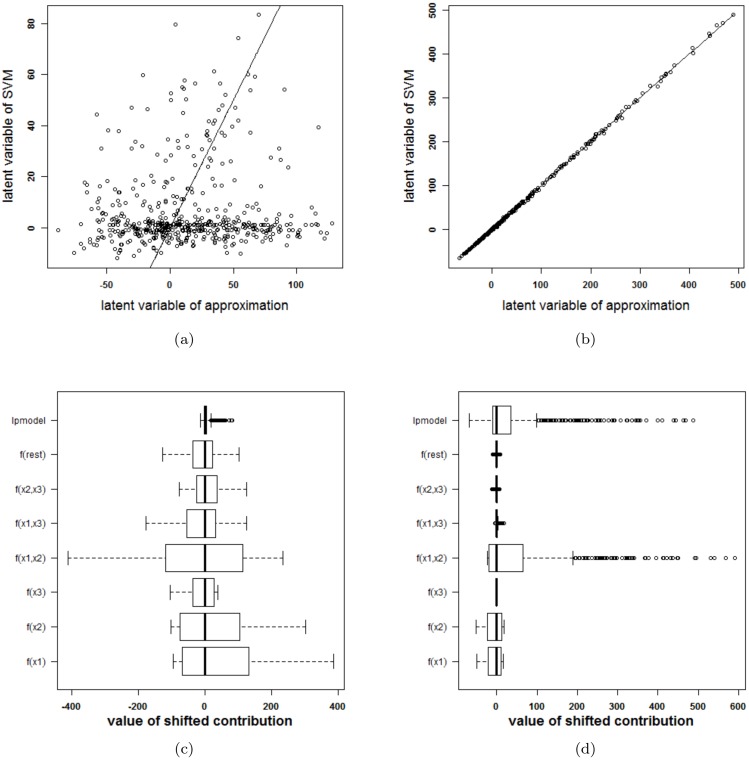
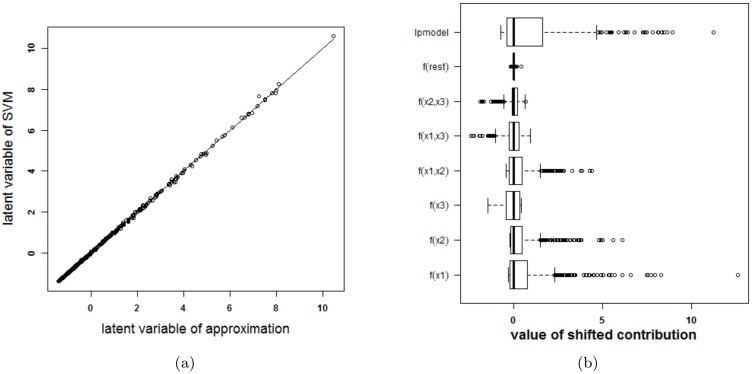
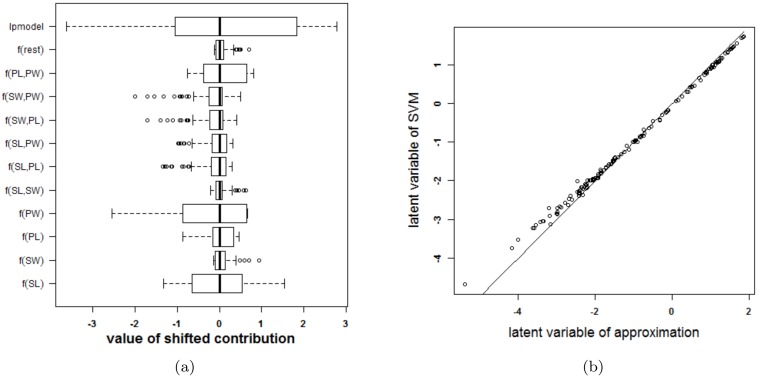
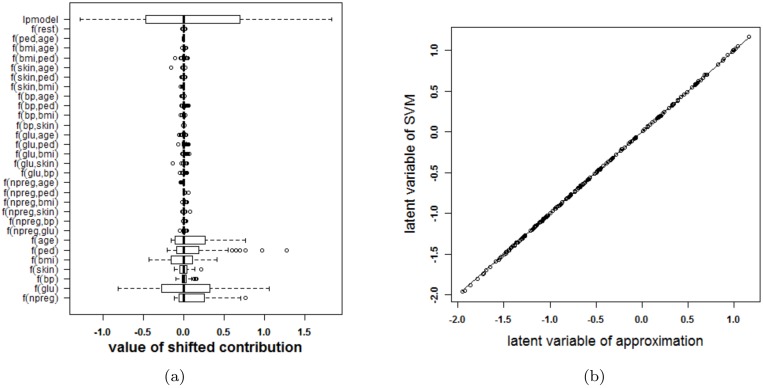
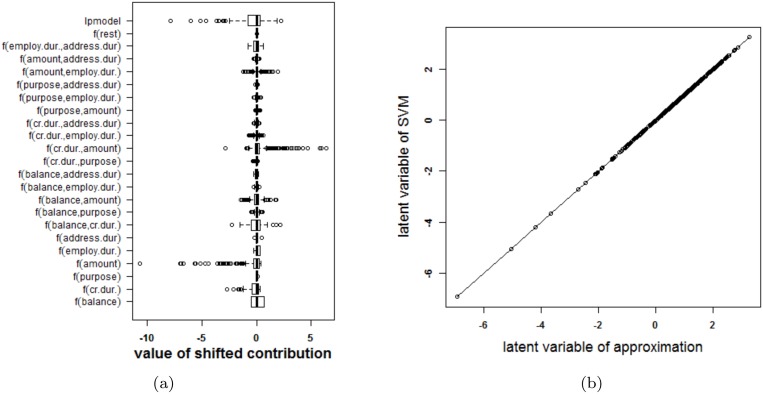
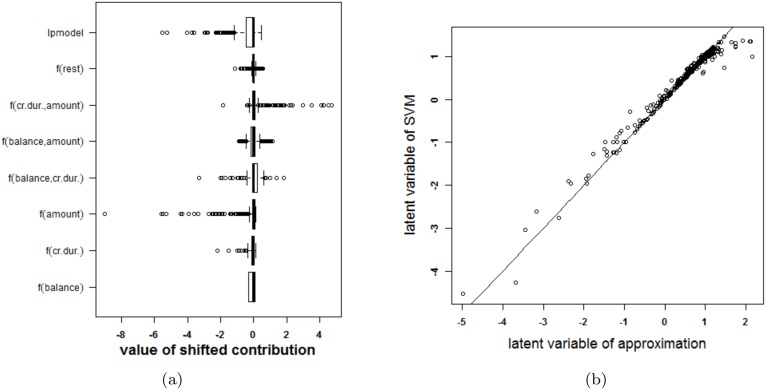
Results: Our experiments on simulated and real-life data show that explainability of an SVM depends on the chosen parameter values (degree of polynomial kernel, width of RBF kernel and regularization constant). When several combinations of parameter values yield the same cross-validation performance, combinations with a lower polynomial degree or a larger kernel width have a higher chance of being explainable.
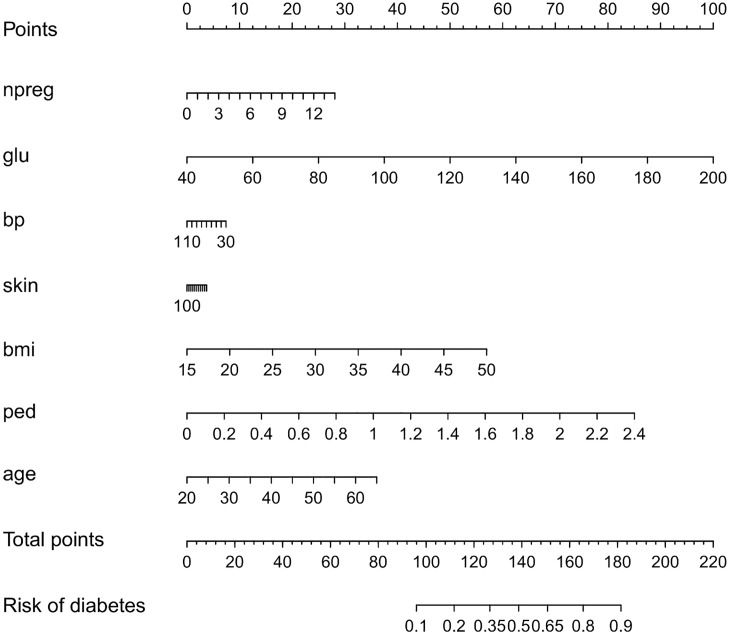
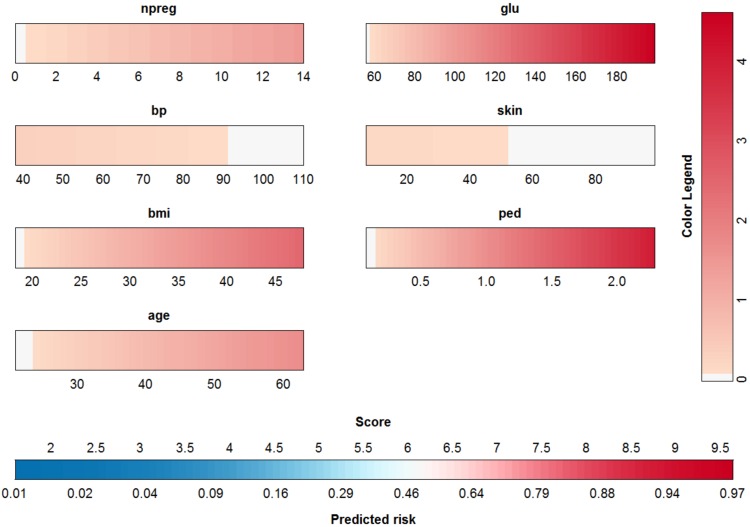
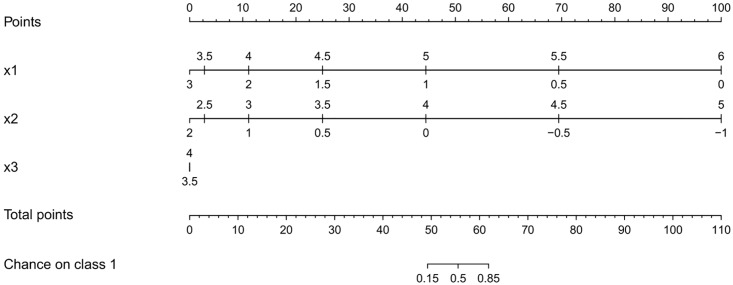
Conclusions: This work summarizes SVM classifiers obtained with linear, polynomial and RBF kernels in a single plot. Linear and polynomial kernels up to the second degree are represented exactly. For other kernels an indication of the reliability of the approximation is presented. The complete methodology is available as an R package and two apps and a movie are provided to illustrate the possibilities offered by the method.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures

References
-
- Joachims T. Learning to Classify Text Using Support Vector Machines: Methods, Theory and Algorithms; 2002. Available from: http://portal.acm.org/citation.cfm?id=572351. 10.1007/978-1-4615-0907-3 - DOI
-
- Decoste D, Schölkopf B. Training invariant support vector machines. Machine Learning. 2002;46(1–3):161–190. 10.1023/A:1012454411458 - DOI
-
- Moghaddam B, Yang MH. Learning gender with support faces. IEEE Transactions on Pattern Analysis and Machine Intelligence. 2002;24(5):707–711. 10.1109/34.1000244 - DOI
-
- Van Belle V, Lisboa P. Research directions in interpretable machine learning methods. In: Verleysen M, editor. Proceedings of the European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning (ESANN2013). d-side, Evere; 2013. p. 533–541.
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
Research Materials
