

Using Big Data to Discover Diagnostics and Therapeutics for Gastrointestinal and Liver Diseases
- PMID: 27773806
- PMCID: PMC5193106
- DOI: 10.1053/j.gastro.2016.09.065
Using Big Data to Discover Diagnostics and Therapeutics for Gastrointestinal and Liver Diseases
Abstract
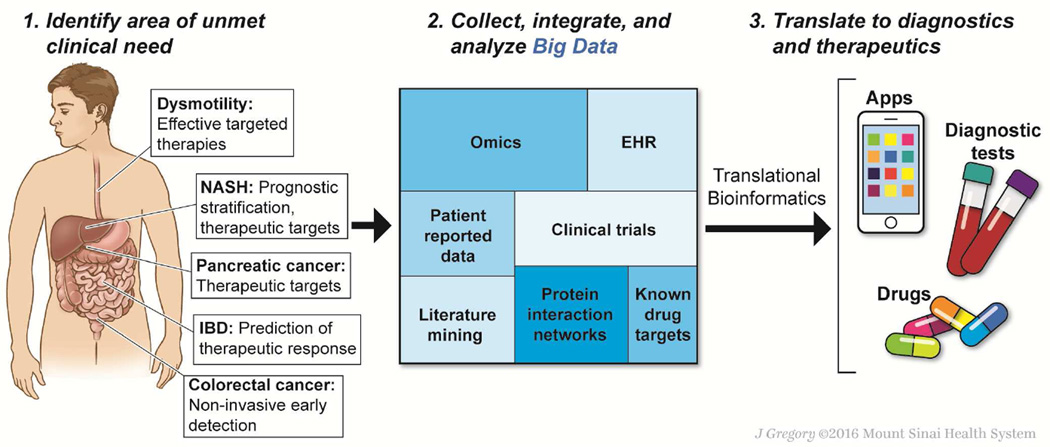
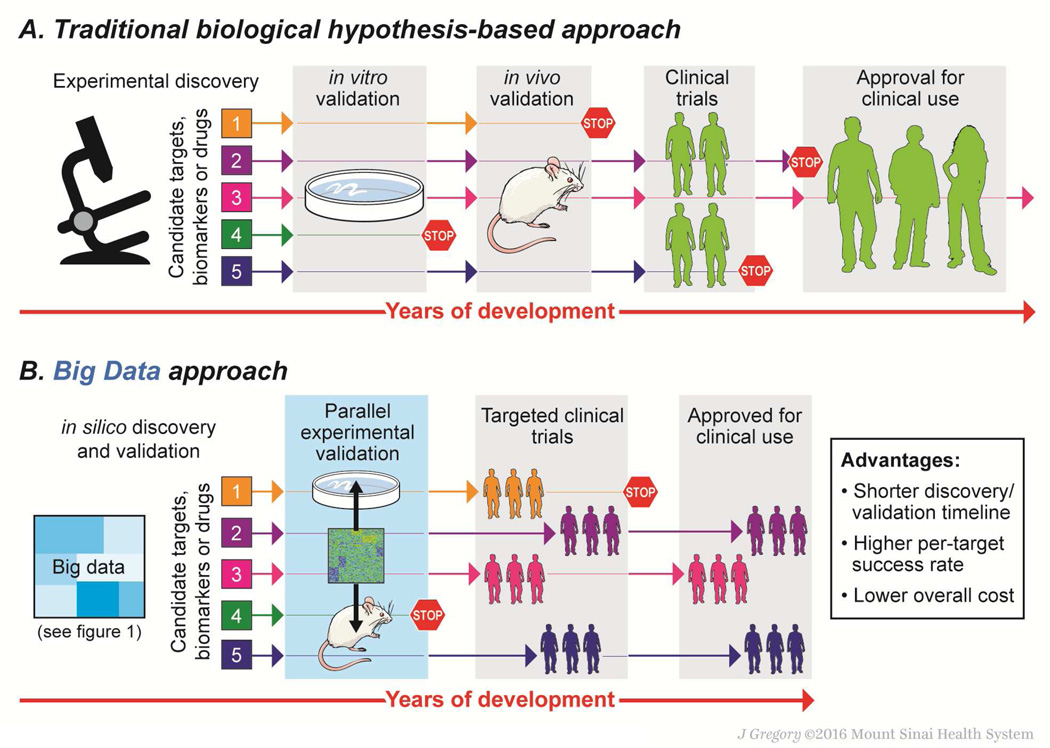
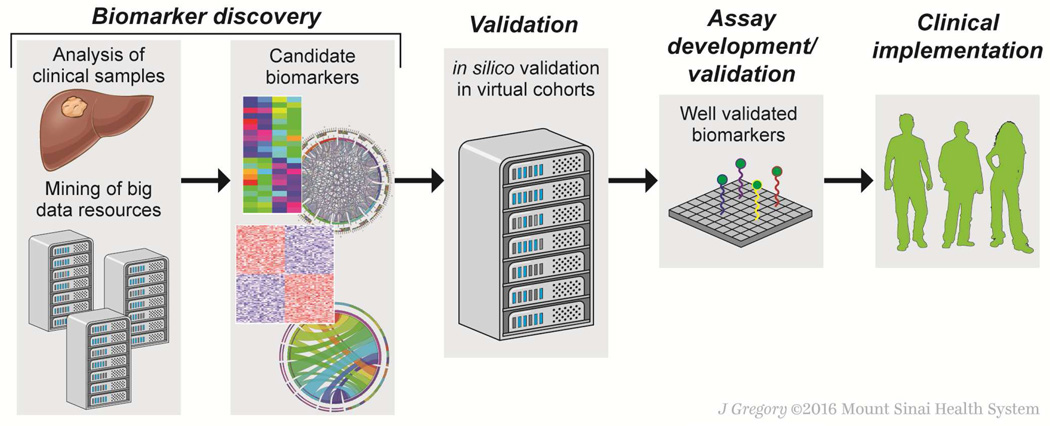
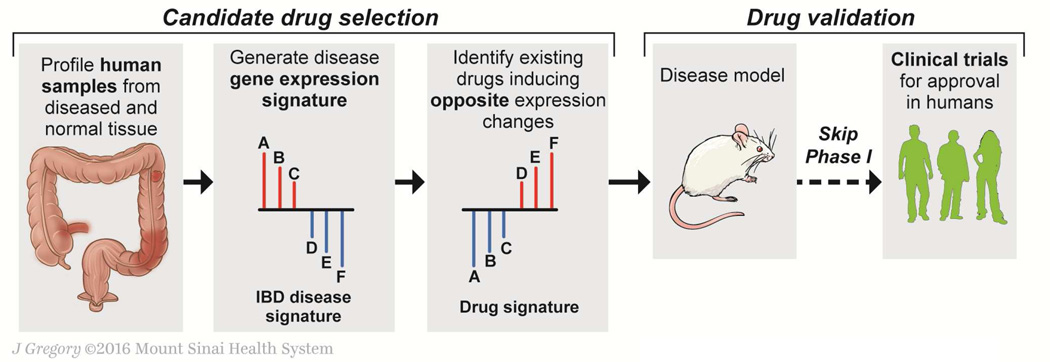
Technologies such as genome sequencing, gene expression profiling, proteomic and metabolomic analyses, electronic medical records, and patient-reported health information have produced large amounts of data from various populations, cell types, and disorders (big data). However, these data must be integrated and analyzed if they are to produce models or concepts about physiological function or mechanisms of pathogenesis. Many of these data are available to the public, allowing researchers anywhere to search for markers of specific biological processes or therapeutic targets for specific diseases or patient types. We review recent advances in the fields of computational and systems biology and highlight opportunities for researchers to use big data sets in the fields of gastroenterology and hepatology to complement traditional means of diagnostic and therapeutic discovery.
Keywords: Big Data; Drug Repurposing; Precision Medicine; Translational Bioinformatics.
Copyright © 2017 AGA Institute. Published by Elsevier Inc. All rights reserved.
Conflict of interest statement
The authors have no relevant conflicts.
Figures
Similar articles
-
Biomarker and drug discovery for gastroenterology through translational bioinformatics.Gastroenterology. 2010 Sep;139(3):735-41, 741.e1. doi: 10.1053/j.gastro.2010.07.024. Epub 2010 Jul 19. Gastroenterology. 2010. PMID: 20650279 Review. No abstract available.
-
Leveraging big data to transform target selection and drug discovery.Clin Pharmacol Ther. 2016 Mar;99(3):285-97. doi: 10.1002/cpt.318. Clin Pharmacol Ther. 2016. PMID: 26659699 Free PMC article. Review.
-
Big Dreams With Big Data! Use of Clinical Informatics to Inform Biomarker Discovery.Clin Transl Gastroenterol. 2019 Mar;10(3):e00018. doi: 10.14309/ctg.0000000000000018. Clin Transl Gastroenterol. 2019. PMID: 30908310 Free PMC article.
-
Leveraging Big Data to Transform Drug Discovery.Methods Mol Biol. 2019;1939:91-118. doi: 10.1007/978-1-4939-9089-4_6. Methods Mol Biol. 2019. PMID: 30848458 Free PMC article.
-
Molecular biology and gene therapy in gastroenterology and hepatology.Eur J Gastroenterol Hepatol. 1999 Jan;11(1):1-7. doi: 10.1097/00042737-199901000-00001. Eur J Gastroenterol Hepatol. 1999. PMID: 10495163 Review.
Cited by
-
A Review of the Role and Challenges of Big Data in Healthcare Informatics and Analytics.Comput Intell Neurosci. 2022 Sep 29;2022:5317760. doi: 10.1155/2022/5317760. eCollection 2022. Comput Intell Neurosci. 2022. PMID: 36210978 Free PMC article. Review.
-
From Reductionistic Approach to Systems Immunology Approach for the Understanding of Tumor Microenvironment.Int J Mol Sci. 2023 Jul 28;24(15):12086. doi: 10.3390/ijms241512086. Int J Mol Sci. 2023. PMID: 37569461 Free PMC article. Review.
-
Random gene sets in predicting survival of patients with hepatocellular carcinoma.J Mol Med (Berl). 2019 Jun;97(6):879-888. doi: 10.1007/s00109-019-01764-2. Epub 2019 Apr 17. J Mol Med (Berl). 2019. PMID: 31001651
-
Innovations in Genomics and Big Data Analytics for Personalized Medicine and Health Care: A Review.Int J Mol Sci. 2022 Apr 22;23(9):4645. doi: 10.3390/ijms23094645. Int J Mol Sci. 2022. PMID: 35563034 Free PMC article. Review.
-
Clinico-histological and molecular features of hepatocellular carcinoma from nonalcoholic fatty liver disease.Cancer Sci. 2023 Oct;114(10):3825-3833. doi: 10.1111/cas.15925. Epub 2023 Aug 7. Cancer Sci. 2023. PMID: 37545384 Free PMC article. Review.
References
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
