

A support vector machine model provides an accurate transcript-level-based diagnostic for major depressive disorder
- PMID: 27779627
- PMCID: PMC5290347
- DOI: 10.1038/tp.2016.198
A support vector machine model provides an accurate transcript-level-based diagnostic for major depressive disorder
Abstract
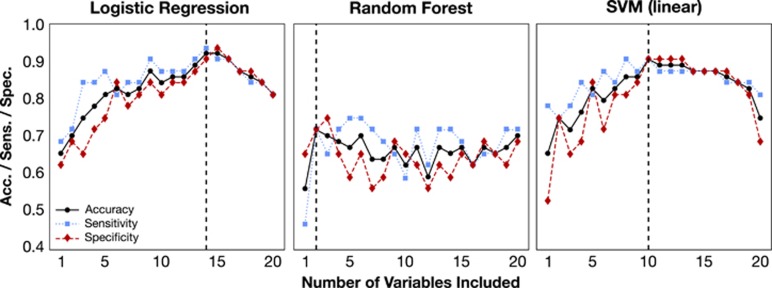
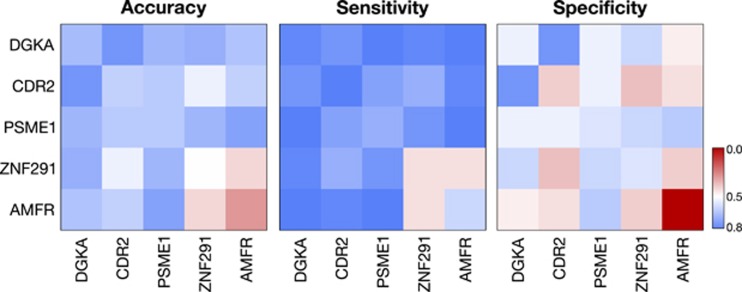
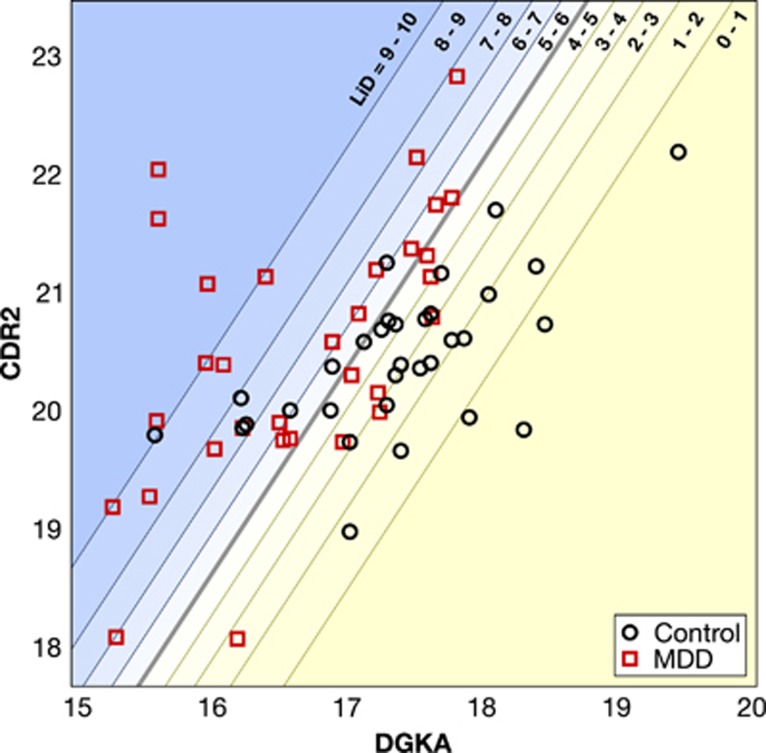
Major depressive disorder (MDD) is a critical cause of morbidity and disability with an economic cost of hundreds of billions of dollars each year, necessitating more effective treatment strategies and novel approaches to translational research. A notable barrier in addressing this public health threat involves reliable identification of the disorder, as many affected individuals remain undiagnosed or misdiagnosed. An objective blood-based diagnostic test using transcript levels of a panel of markers would provide an invaluable tool for MDD as the infrastructure-including equipment, trained personnel, billing, and governmental approval-for similar tests is well established in clinics worldwide. Here we present a supervised classification model utilizing support vector machines (SVMs) for the analysis of transcriptomic data readily obtained from a peripheral blood specimen. The model was trained on data from subjects with MDD (n=32) and age- and gender-matched controls (n=32). This SVM model provides a cross-validated sensitivity and specificity of 90.6% for the diagnosis of MDD using a panel of 10 transcripts. We applied a logistic equation on the SVM model and quantified a likelihood of depression score. This score gives the probability of a MDD diagnosis and allows the tuning of specificity and sensitivity for individual patients to bring personalized medicine closer in psychiatry.
Figures

References
-
- Kessler RC, Berglund P, Demler O, Jin R, Merikangas KR, Walters EE. Lifetime prevalence and age-of-onset distributions of DSM-IV disorders in the National Comorbidity Survey Replication. Arch Gen Psychiatry 2005; 62: 593–602. - PubMed
-
- Wells KB, Hays RD, Burnam MA, Rogers W, Greenfield S, Ware JE. Detection of depressive disorder for patients receiving prepaid or fee-for-service care. Results from the Medical Outcomes Study. JAMA 1989; 262: 3298–3302. - PubMed
-
- Belmaker RH, Agam G. Major depressive disorder. N Engl J Med 2008; 358: 55–68. - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
