

Adaptive integration of habits into depth-limited planning defines a habitual-goal-directed spectrum
- PMID: 27791110
- PMCID: PMC5111694
- DOI: 10.1073/pnas.1609094113
Adaptive integration of habits into depth-limited planning defines a habitual-goal-directed spectrum
Abstract
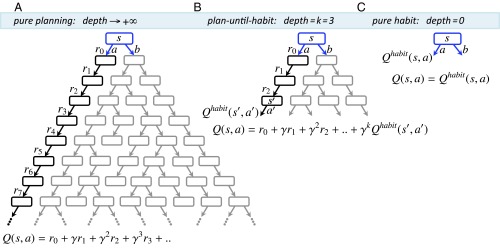
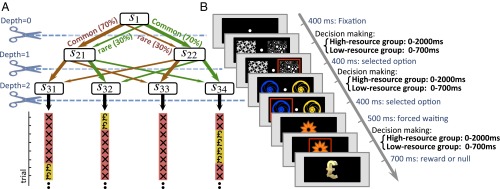
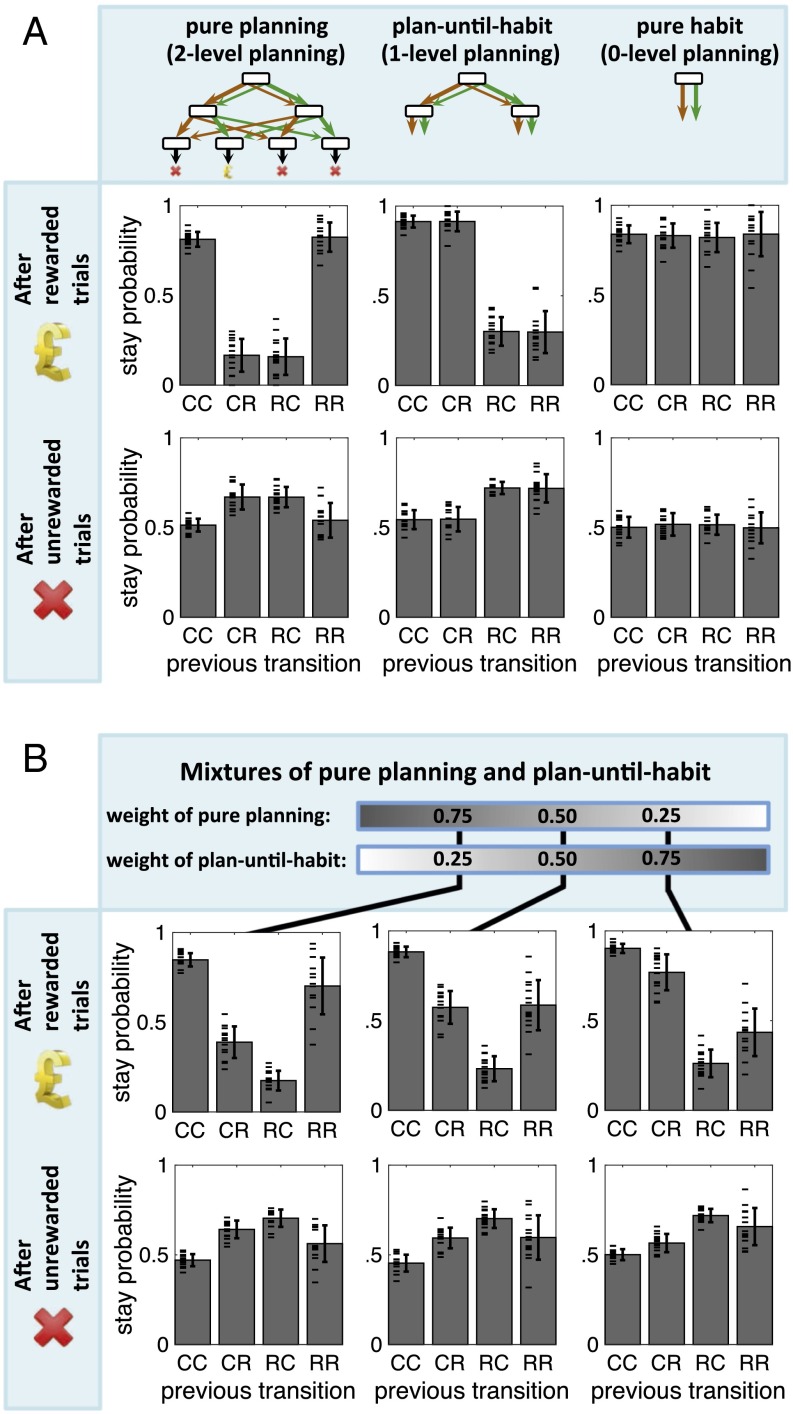
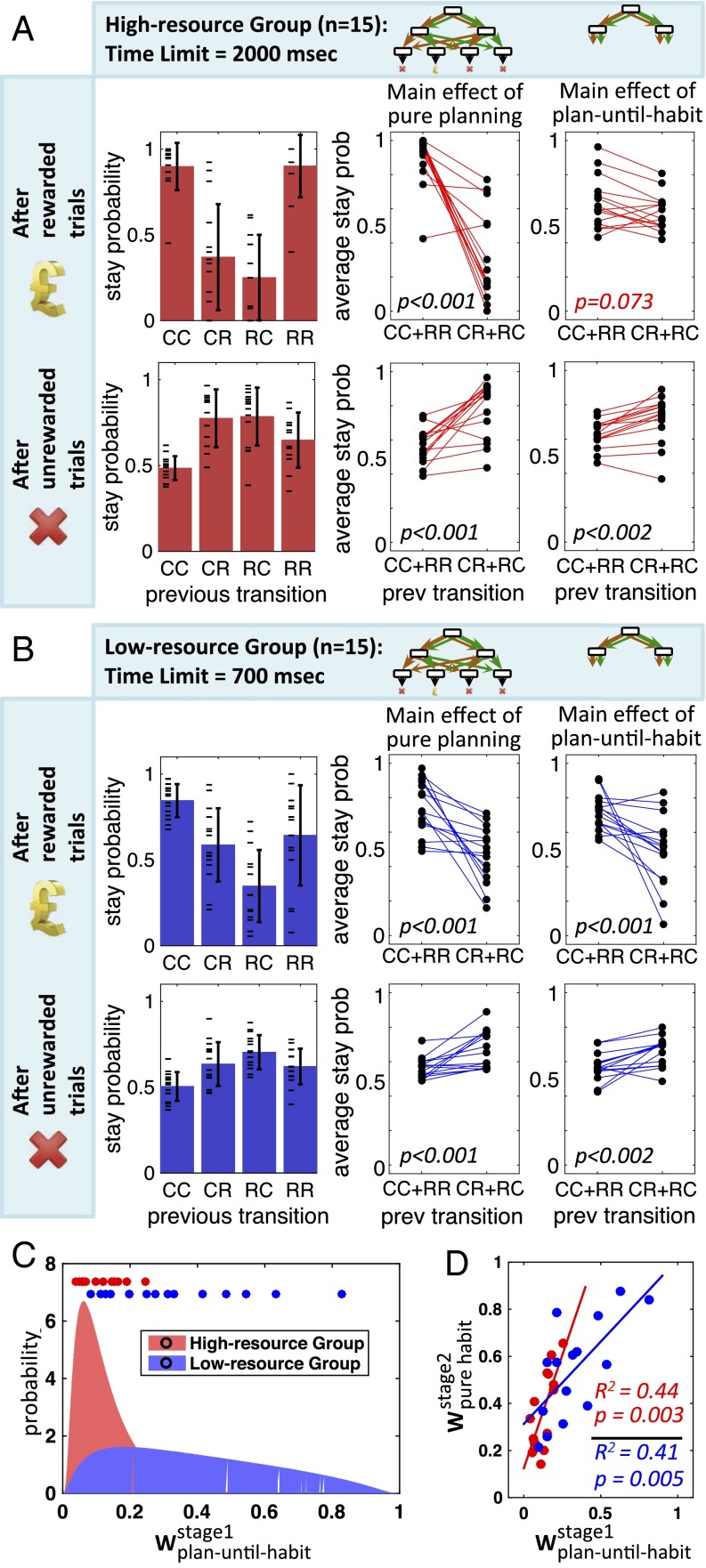
Behavioral and neural evidence reveal a prospective goal-directed decision process that relies on mental simulation of the environment, and a retrospective habitual process that caches returns previously garnered from available choices. Artificial systems combine the two by simulating the environment up to some depth and then exploiting habitual values as proxies for consequences that may arise in the further future. Using a three-step task, we provide evidence that human subjects use such a normative plan-until-habit strategy, implying a spectrum of approaches that interpolates between habitual and goal-directed responding. We found that increasing time pressure led to shallower goal-directed planning, suggesting that a speed-accuracy tradeoff controls the depth of planning with deeper search leading to more accurate evaluation, at the cost of slower decision-making. We conclude that subjects integrate habit-based cached values directly into goal-directed evaluations in a normative manner.
Keywords: habit; planning; reinforcement learning; speed/accuracy tradeoff; tree-based evaluation.
Conflict of interest statement
The authors declare no conflict of interest.
Figures
References
-
- Dickinson A, Balleine BW. The role of learning in motivation. In: Gallistel CR, editor. Steven’s Handbook of Experimental Psychology: Learning, Motivation, and Emotion. 3rd Ed. Vol 3. Wiley; New York: 2002. pp. 497–533.
-
- Daw ND, Niv Y, Dayan P. Uncertainty-based competition between prefrontal and dorsolateral striatal systems for behavioral control. Nat Neurosci. 2005;8(12):1704–1711. - PubMed
-
- Doya K. What are the computations of the cerebellum, the basal ganglia and the cerebral cortex? Neural Netw. 1999;12(7-8):961–974. - PubMed
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
