

Sequence of the Sugar Pine Megagenome
- PMID: 27794028
- PMCID: PMC5161289
- DOI: 10.1534/genetics.116.193227
Sequence of the Sugar Pine Megagenome
Abstract
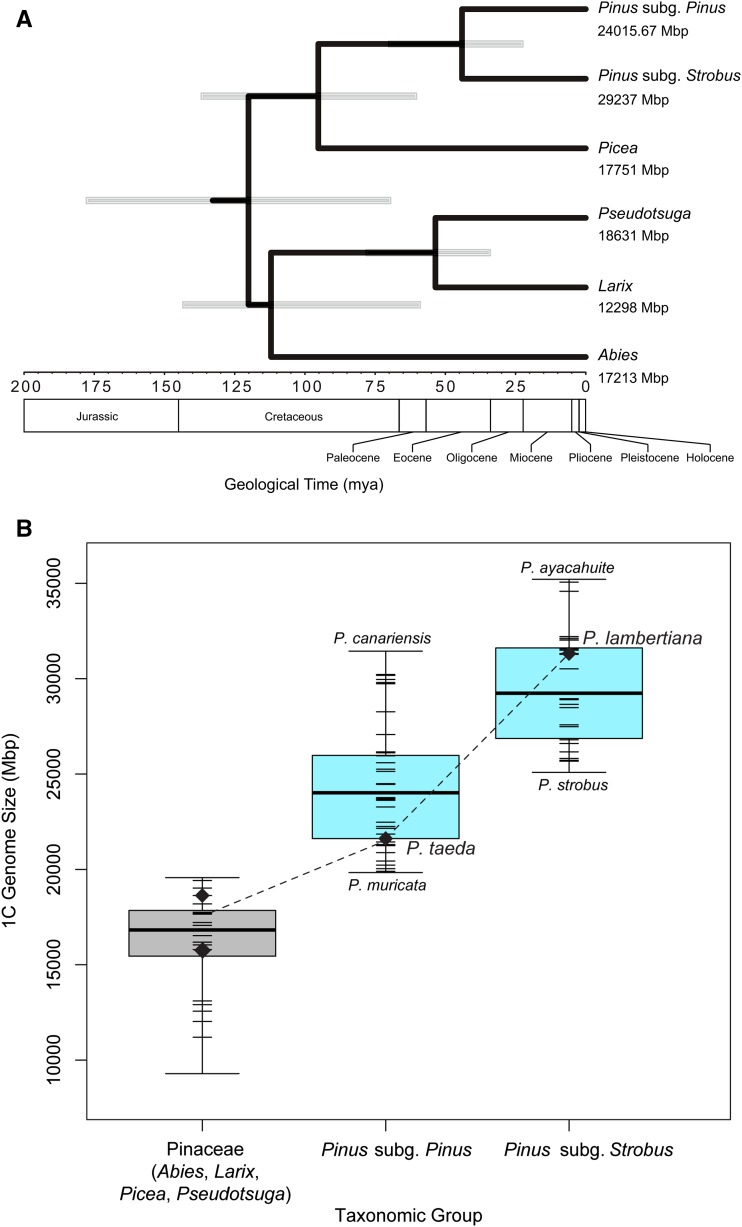
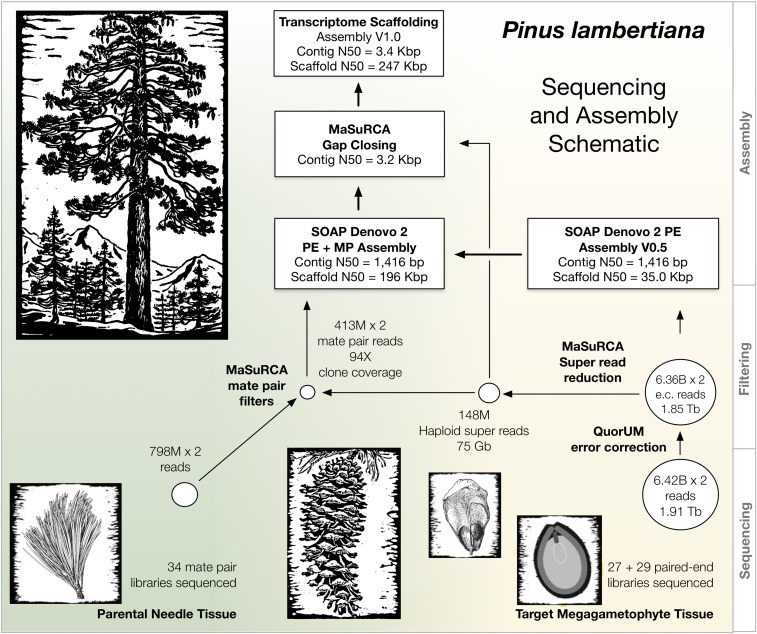
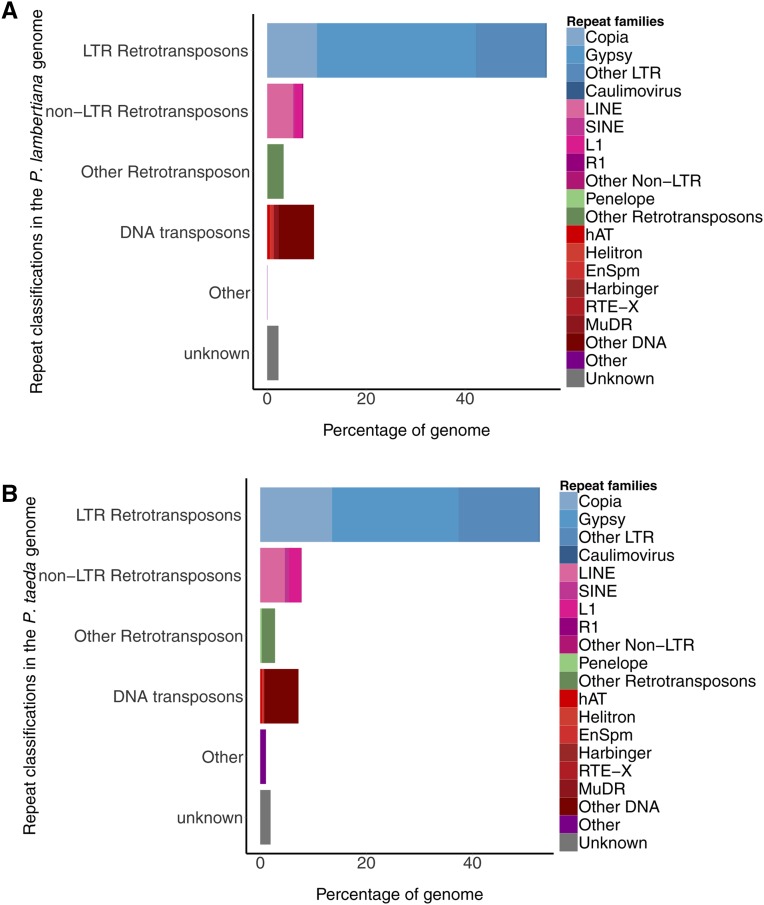
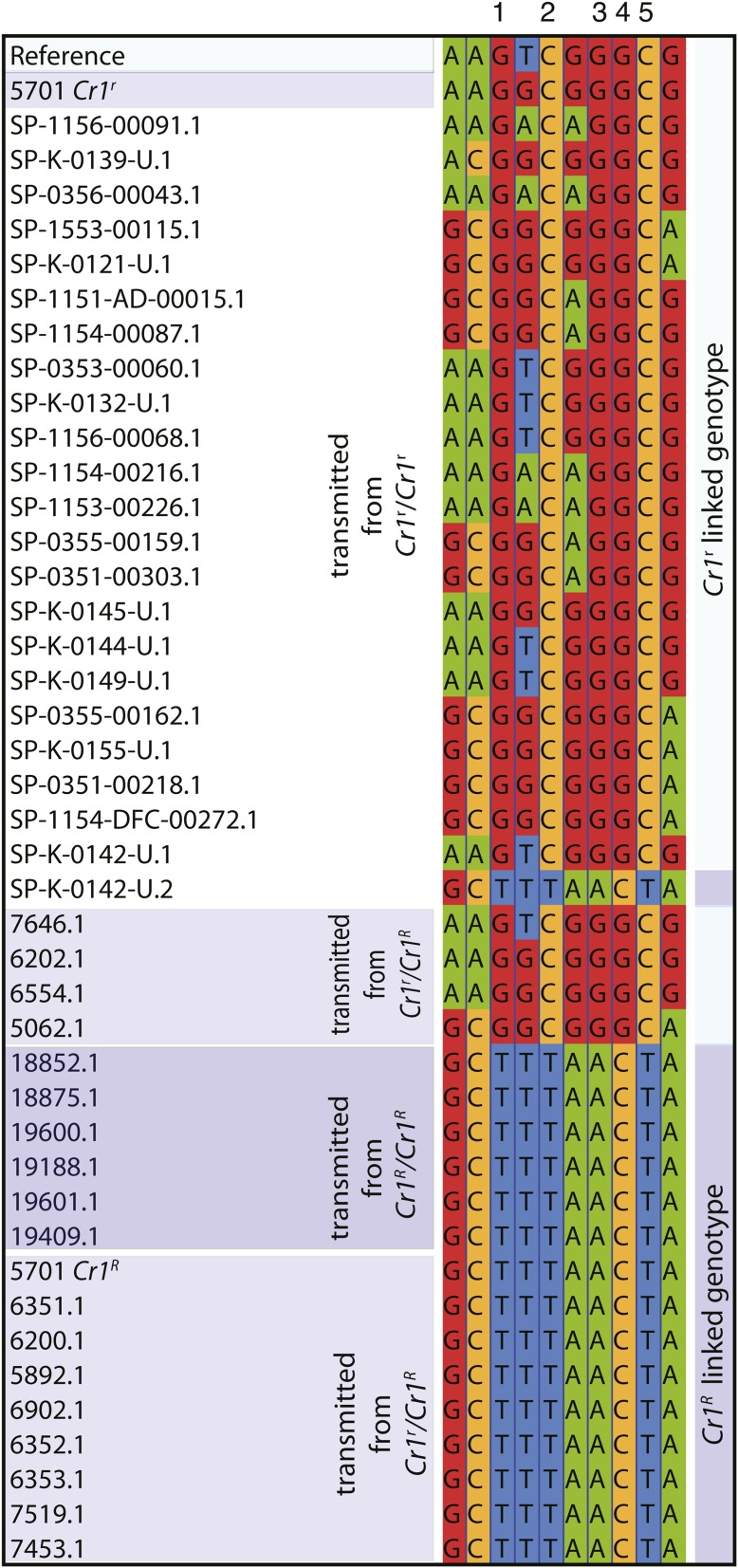
Until very recently, complete characterization of the megagenomes of conifers has remained elusive. The diploid genome of sugar pine (Pinus lambertiana Dougl.) has a highly repetitive, 31 billion bp genome. It is the largest genome sequenced and assembled to date, and the first from the subgenus Strobus, or white pines, a group that is notable for having the largest genomes among the pines. The genome represents a unique opportunity to investigate genome "obesity" in conifers and white pines. Comparative analysis of P. lambertiana and P. taeda L. reveals new insights on the conservation, age, and diversity of the highly abundant transposable elements, the primary factor determining genome size. Like most North American white pines, the principal pathogen of P. lambertiana is white pine blister rust (Cronartium ribicola J.C. Fischer ex Raben.). Identification of candidate genes for resistance to this pathogen is of great ecological importance. The genome sequence afforded us the opportunity to make substantial progress on locating the major dominant gene for simple resistance hypersensitive response, Cr1 We describe new markers and gene annotation that are both tightly linked to Cr1 in a mapping population, and associated with Cr1 in unrelated sugar pine individuals sampled throughout the species' range, creating a solid foundation for future mapping. This genomic variation and annotated candidate genes characterized in our study of the Cr1 region are resources for future marker-assisted breeding efforts as well as for investigations of fundamental mechanisms of invasive disease and evolutionary response.
Keywords: conifer genome; transposable elements; white pine blister rust.
Copyright © 2016 by the Genetics Society of America.
Figures

References
-
- Abrusán G., Grundmann N., DeMester L., Makalowski W., 2009. TEclass—a tool for automated classification of unknown eukaryotic transposable elements. Bioinformatics 25(10): 1329–1330. - PubMed
-
- Ahuja M. R., Neale D. B., 2005. Evolution of genome size in conifers. Silvae Genet. 54(3): 126–137.
-
- American Forests, 2015 This Is It! The Quest for a New Champion Sugar Pine. Available at: http://www.americanforests.org/blog/quest-for-a-new-champion-sugar-pine/.
-
- Bennett, M. D., and I. J. Leitch, 2012 Plant DNA C-values database, release 6.0, Dec. 2012. Available at: http://data.kew.org/cvalues/.
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
