

Big genomics and clinical data analytics strategies for precision cancer prognosis
- PMID: 27819294
- PMCID: PMC5098145
- DOI: 10.1038/srep36493
Big genomics and clinical data analytics strategies for precision cancer prognosis
Abstract
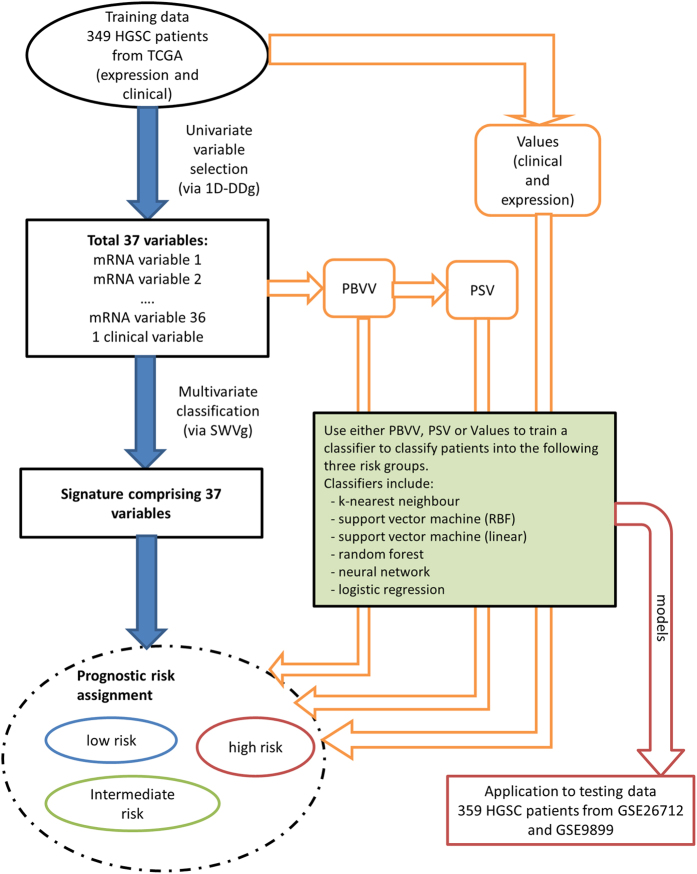
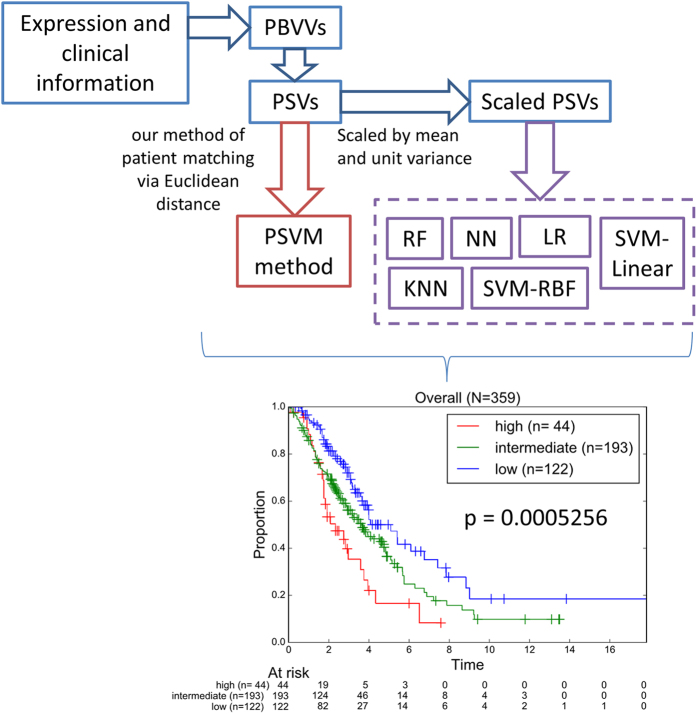
The field of personalized and precise medicine in the era of big data analytics is growing rapidly. Previously, we proposed our model of patient classification termed Prognostic Signature Vector Matching (PSVM) and identified a 37 variable signature comprising 36 let-7b associated prognostic significant mRNAs and the age risk factor that stratified large high-grade serous ovarian cancer patient cohorts into three survival-significant risk groups. Here, we investigated the predictive performance of PSVM via optimization of the prognostic variable weights, which represent the relative importance of one prognostic variable over the others. In addition, we compared several multivariate prognostic models based on PSVM with classical machine learning techniques such as K-nearest-neighbor, support vector machine, random forest, neural networks and logistic regression. Our results revealed that negative log-rank p-values provides more robust weight values as opposed to the use of other quantities such as hazard ratios, fold change, or a combination of those factors. PSVM, together with the classical machine learning classifiers were combined in an ensemble (multi-test) voting system, which collectively provides a more precise and reproducible patient stratification. The use of the multi-test system approach, rather than the search for the ideal classification/prediction method, might help to address limitations of the individual classification algorithm in specific situation.
Figures



References
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
Molecular Biology Databases
