

The Memory Trace Supporting Lose-Shift Responding Decays Rapidly after Reward Omission and Is Distinct from Other Learning Mechanisms in Rats
- PMID: 27896312
- PMCID: PMC5112541
- DOI: 10.1523/ENEURO.0167-16.2016
The Memory Trace Supporting Lose-Shift Responding Decays Rapidly after Reward Omission and Is Distinct from Other Learning Mechanisms in Rats
Abstract
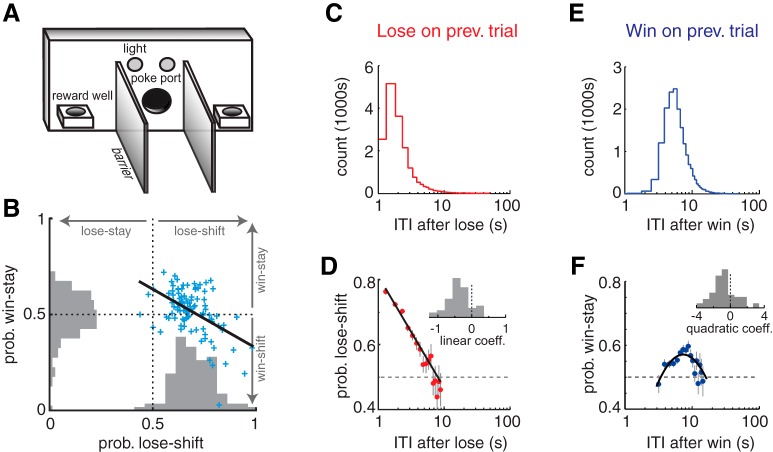
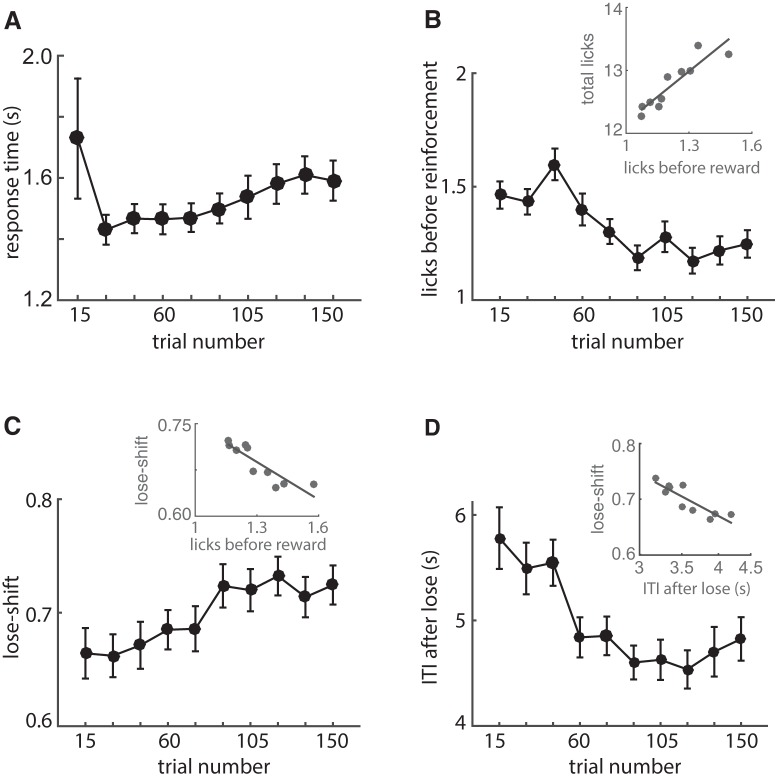
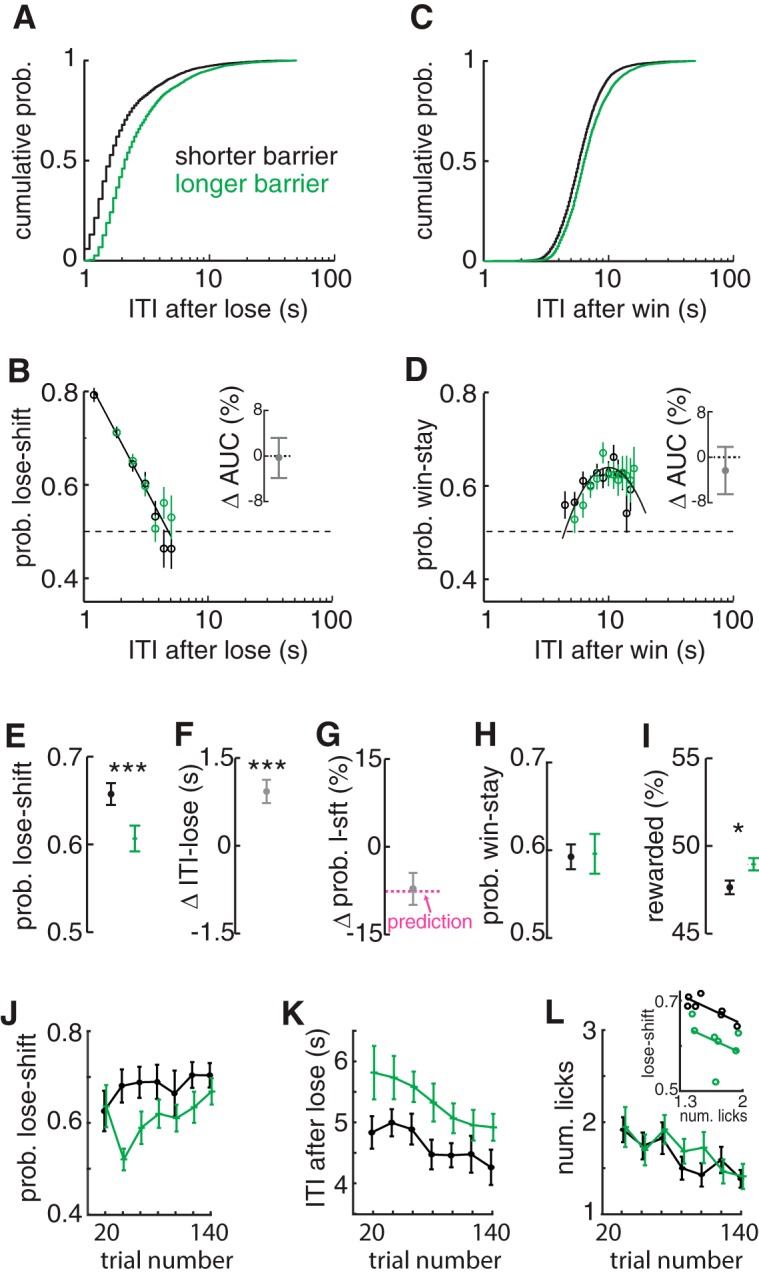
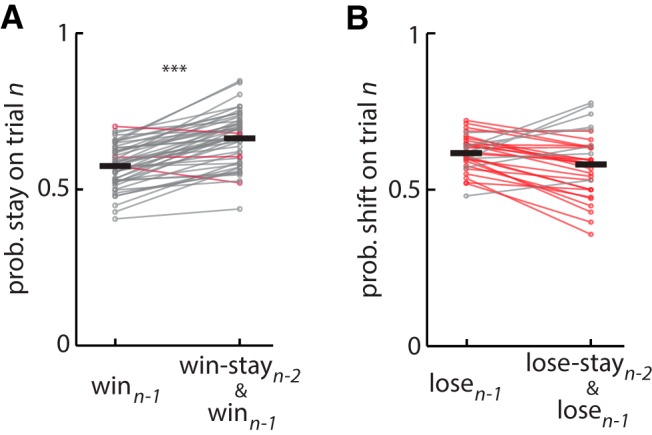
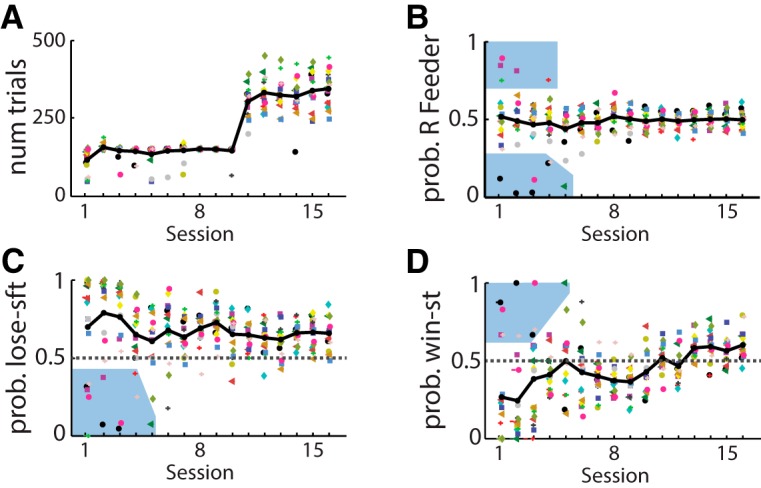
The propensity of animals to shift choices immediately after unexpectedly poor reinforcement outcomes is a pervasive strategy across species and tasks. We report here that the memory supporting such lose-shift responding in rats rapidly decays during the intertrial interval and persists throughout training and testing on a binary choice task, despite being a suboptimal strategy. Lose-shift responding is not positively correlated with the prevalence and temporal dependence of win-stay responding, and it is inconsistent with predictions of reinforcement learning on the task. These data provide further evidence that win-stay and lose-shift are mediated by dissociated neural mechanisms and indicate that lose-shift responding presents a potential confound for the study of choice in the many operant choice tasks with short intertrial intervals. We propose that this immediate lose-shift responding is an intrinsic feature of the brain's choice mechanisms that is engaged as a choice reflex and works in parallel with reinforcement learning and other control mechanisms to guide action selection.
Keywords: WSLS; decay; lose-switch; memory; reinforcement.
Conflict of interest statement
The authors have no conflicts of interest.
Figures
References
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
Miscellaneous