

MISSING DATA IMPUTATION IN THE ELECTRONIC HEALTH RECORD USING DEEPLY LEARNED AUTOENCODERS
- PMID: 27896976
- PMCID: PMC5144587
- DOI: 10.1142/9789813207813_0021
MISSING DATA IMPUTATION IN THE ELECTRONIC HEALTH RECORD USING DEEPLY LEARNED AUTOENCODERS
Abstract
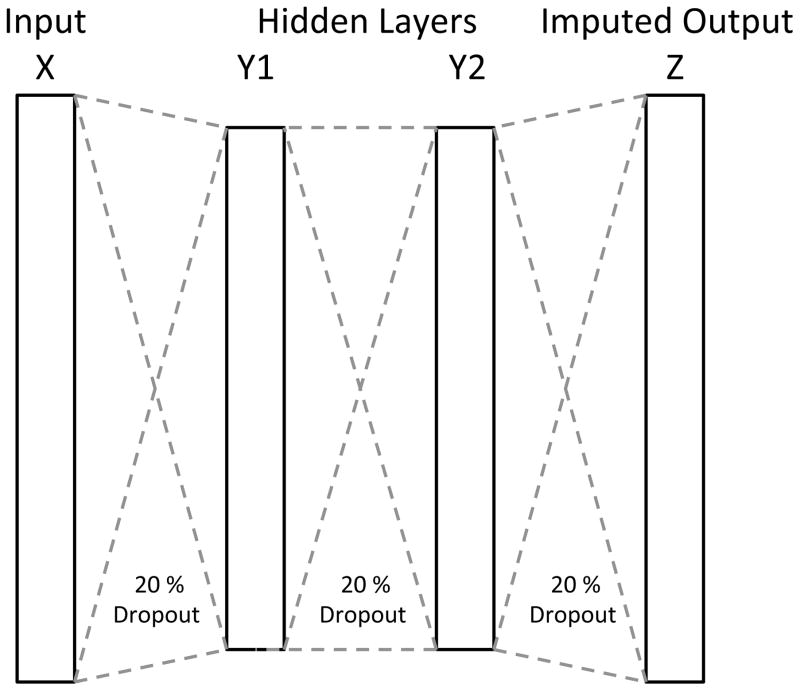
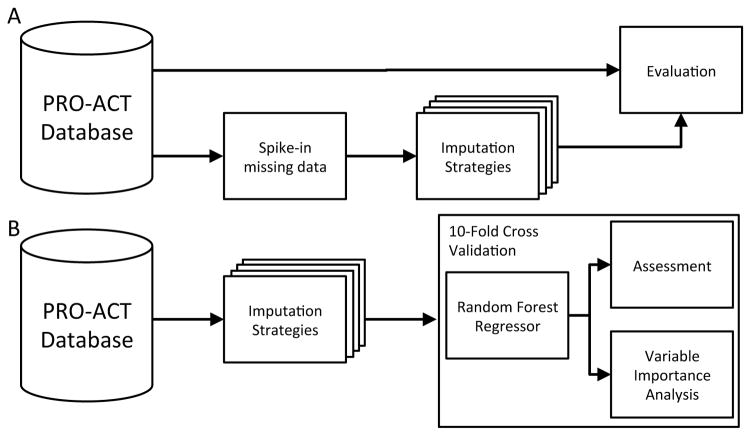
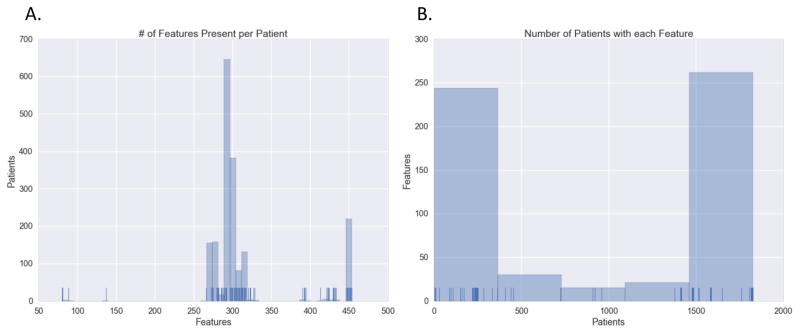
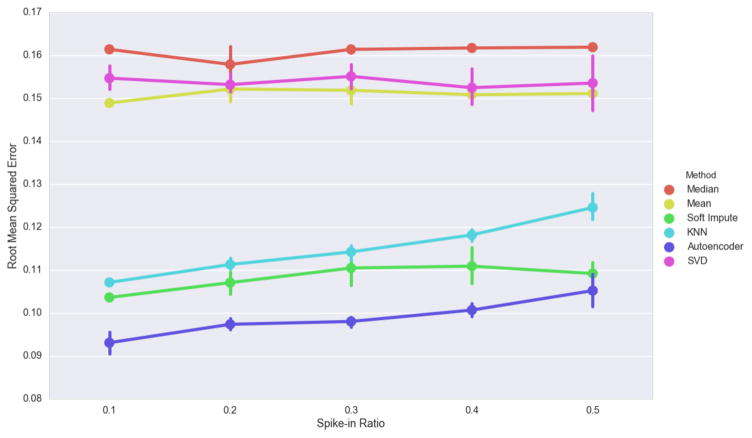
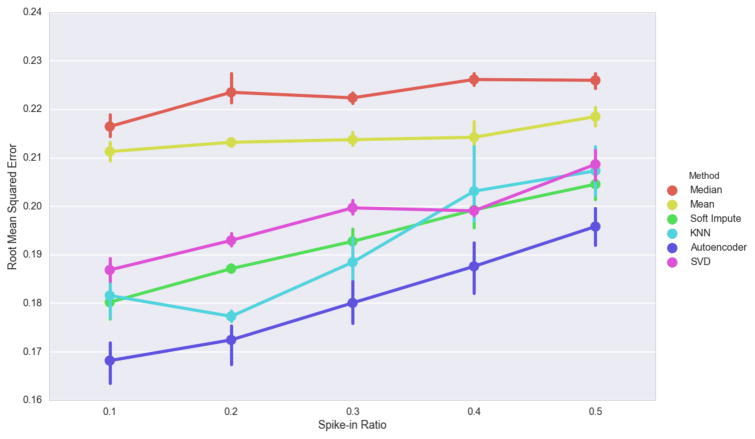
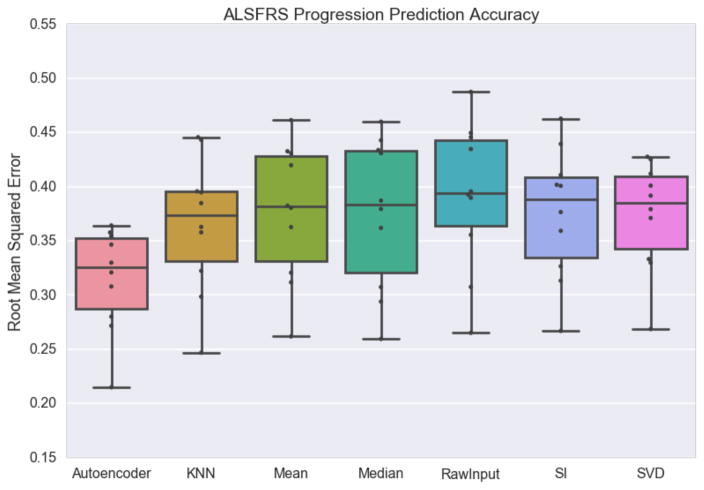
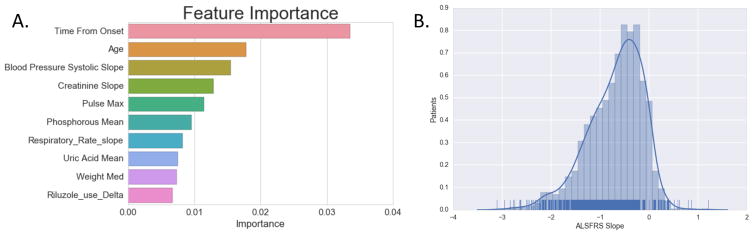
Electronic health records (EHRs) have become a vital source of patient outcome data but the widespread prevalence of missing data presents a major challenge. Different causes of missing data in the EHR data may introduce unintentional bias. Here, we compare the effectiveness of popular multiple imputation strategies with a deeply learned autoencoder using the Pooled Resource Open-Access ALS Clinical Trials Database (PRO-ACT). To evaluate performance, we examined imputation accuracy for known values simulated to be either missing completely at random or missing not at random. We also compared ALS disease progression prediction across different imputation models. Autoencoders showed strong performance for imputation accuracy and contributed to the strongest disease progression predictor. Finally, we show that despite clinical heterogeneity, ALS disease progression appears homogenous with time from onset being the most important predictor.
Figures
References
-
- McClatchey KD. Clinical Laboratory Medicine. Lippincott Williams & Wilkins; 2002.
-
- Little R, Rubin D. Statistical Analysis with Missing Data. John Wiley & Sons; 2014.
-
- Marlin B. [Accessed August 7, 2016];Missing data problems in machine learning. 2008 http://www-devel.cs.ubc.ca/~bmarlin/research/phd_thesis/marlin-phd-thesi....
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Miscellaneous
