

Statistical Approaches to Candidate Biomarker Panel Selection
- PMID: 27975231
- PMCID: PMC7885896
- DOI: 10.1007/978-3-319-41448-5_22
Statistical Approaches to Candidate Biomarker Panel Selection
Abstract
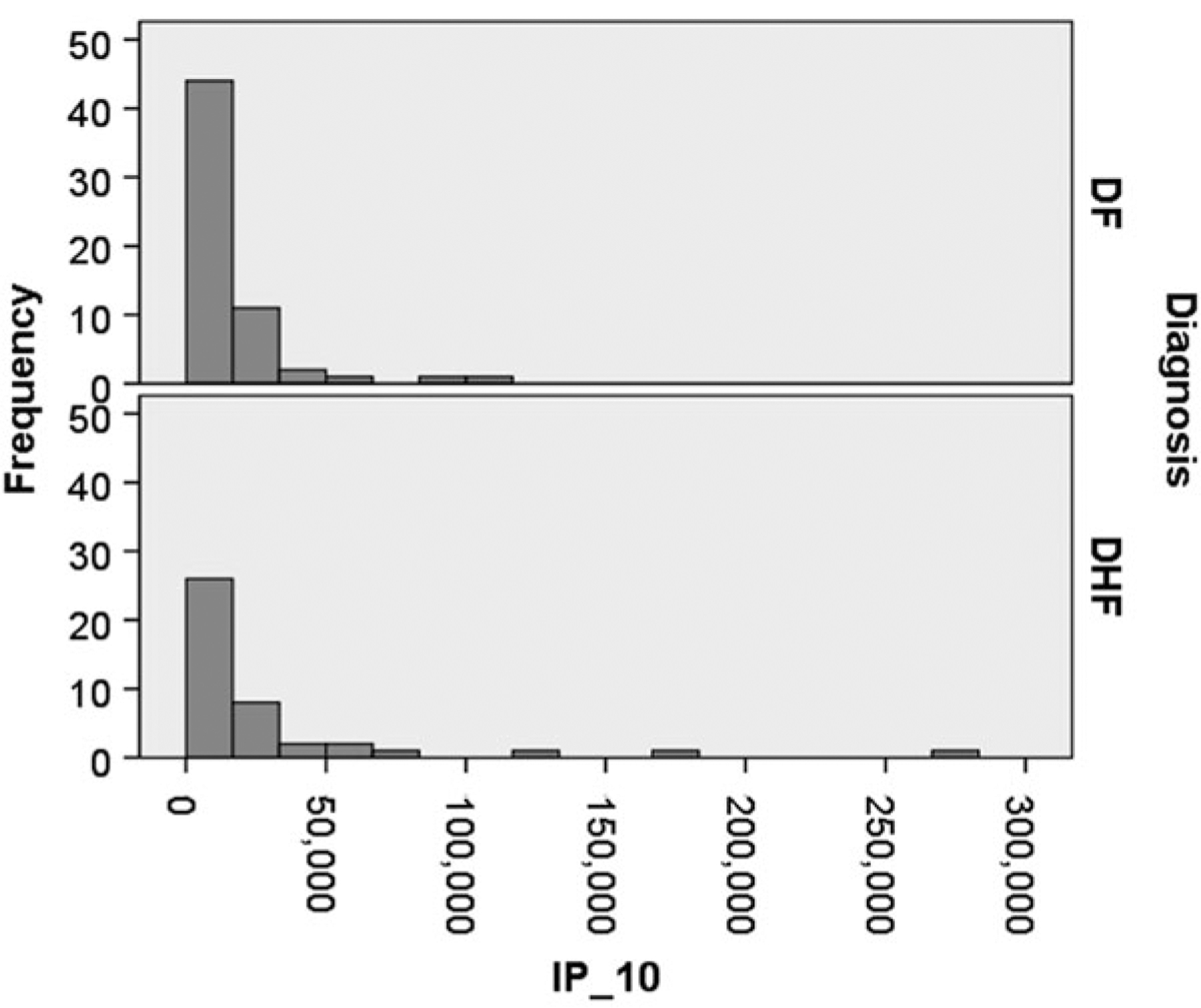
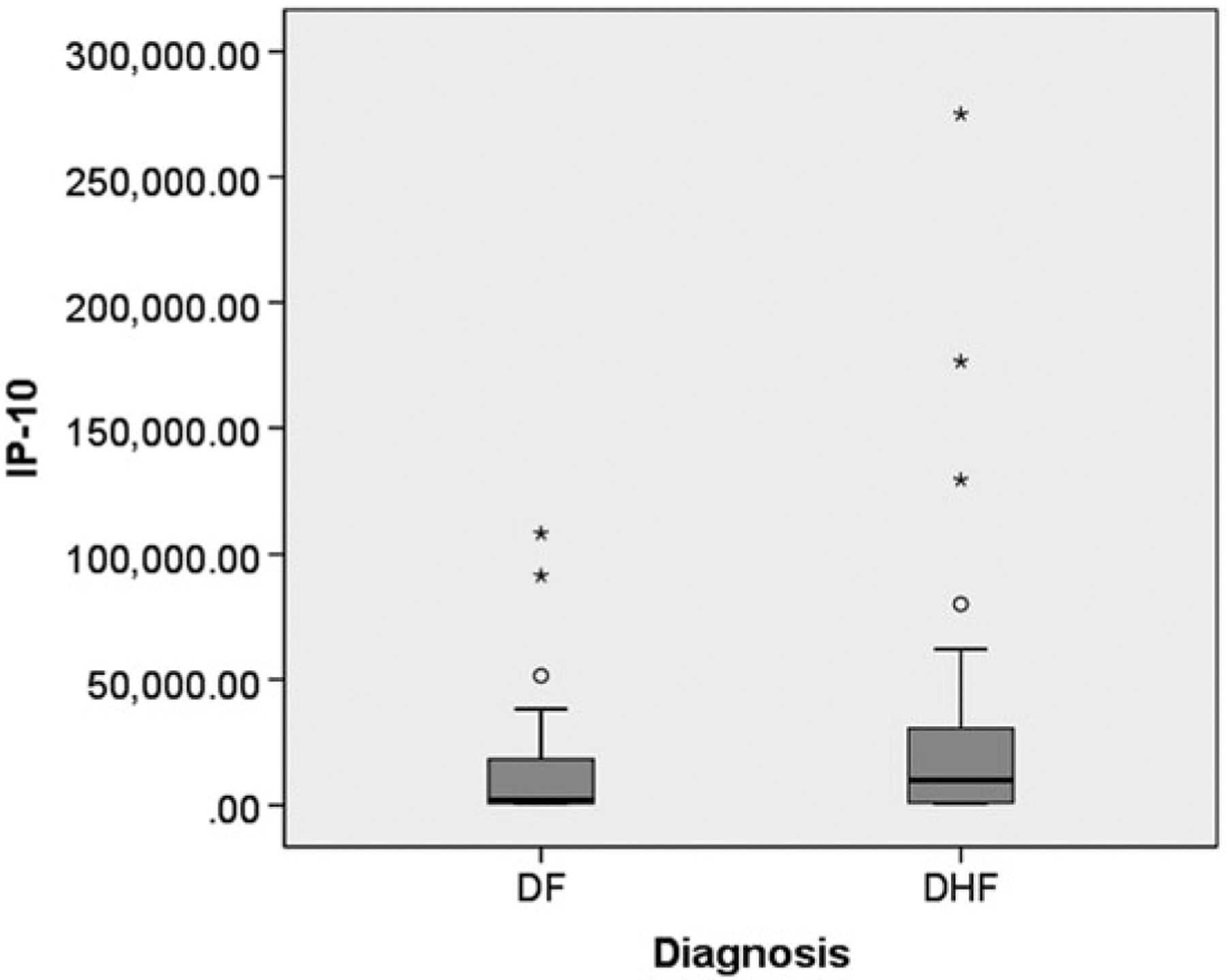
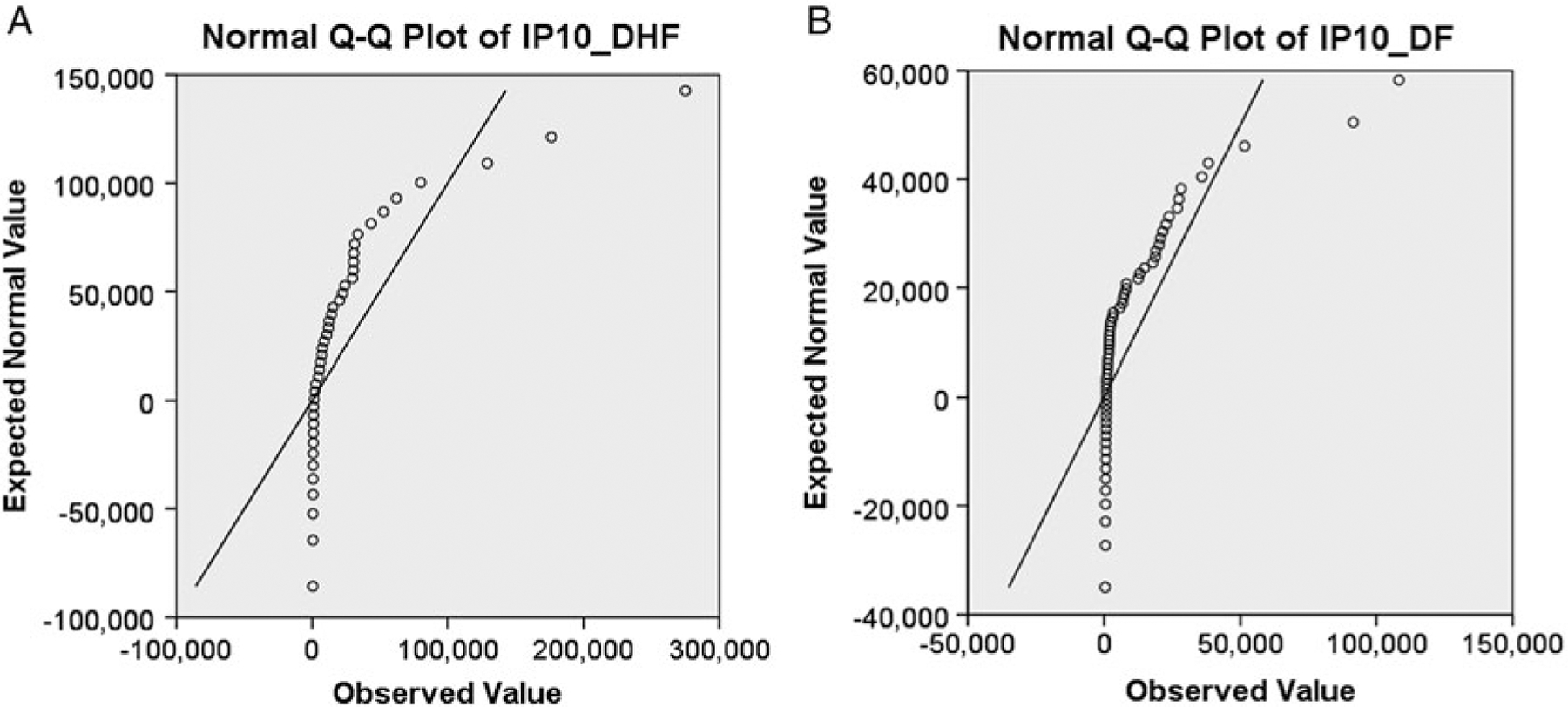
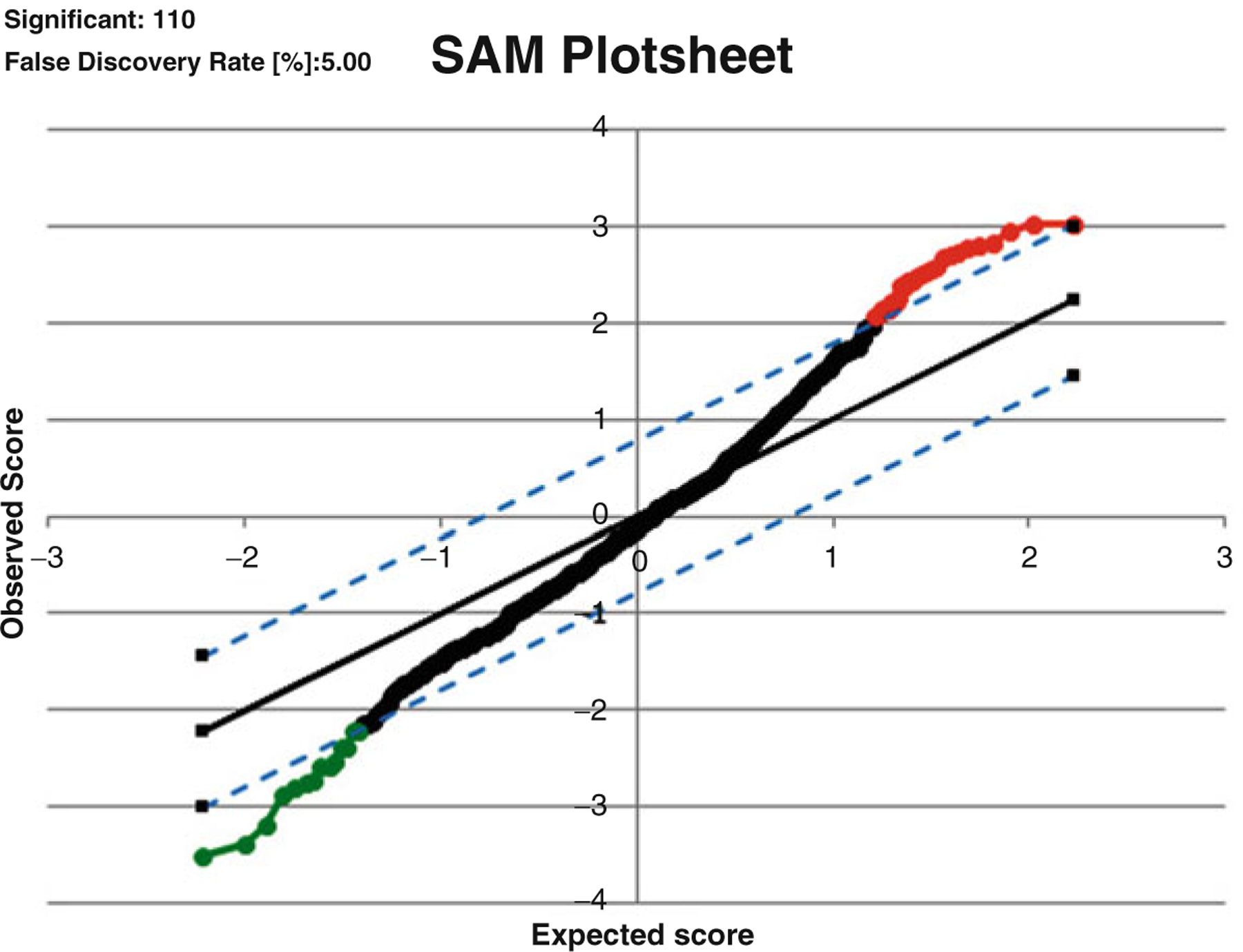
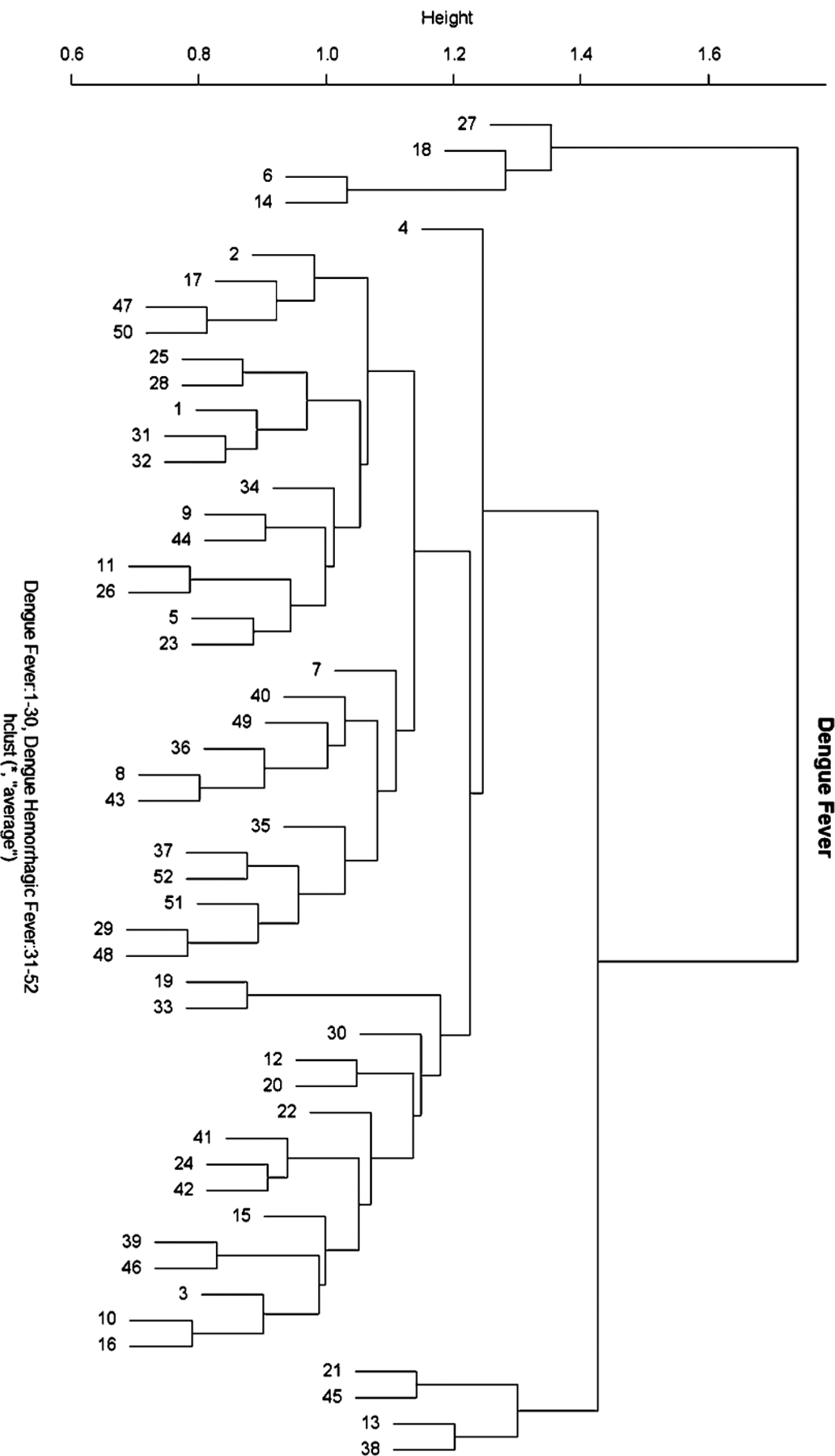
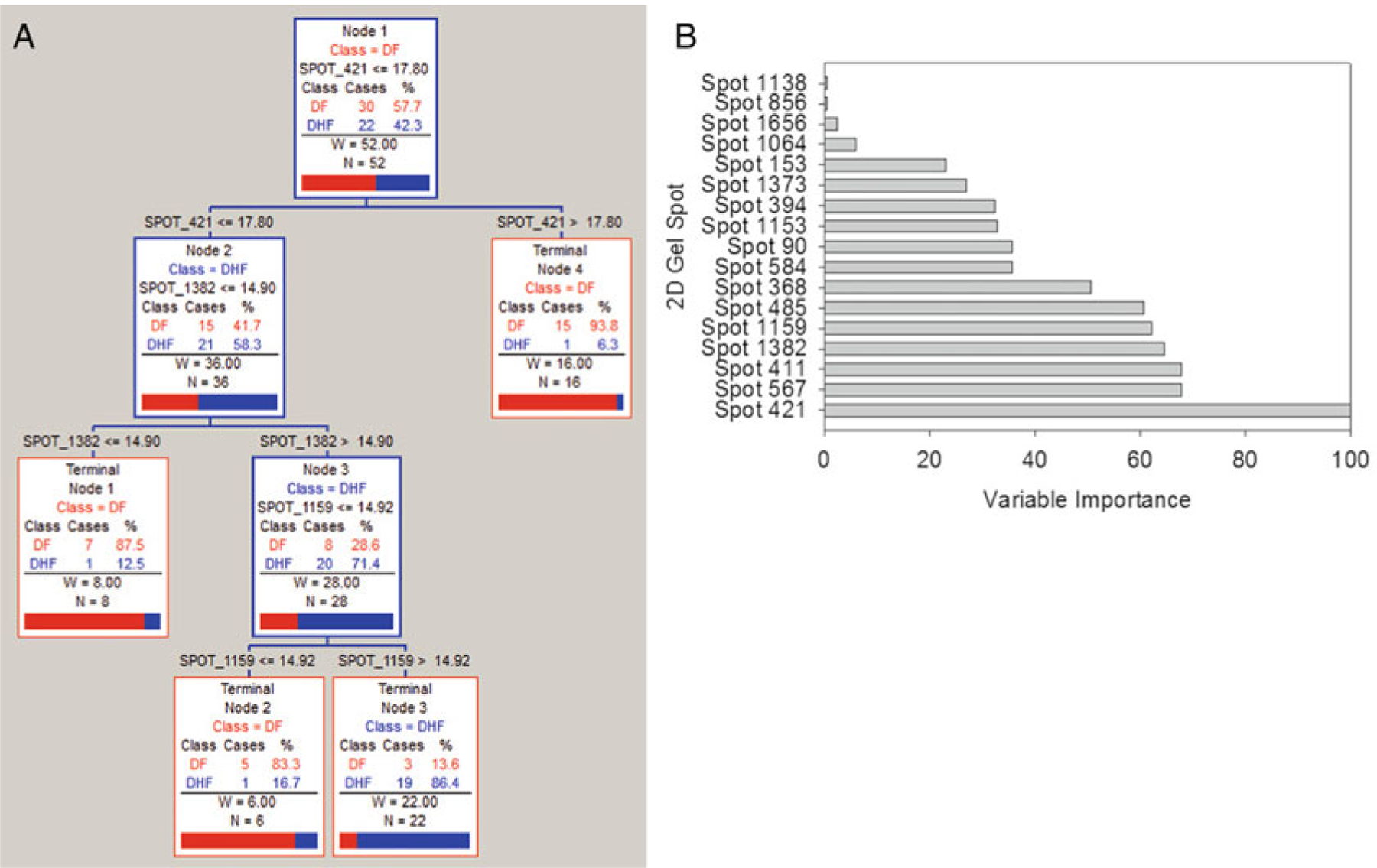
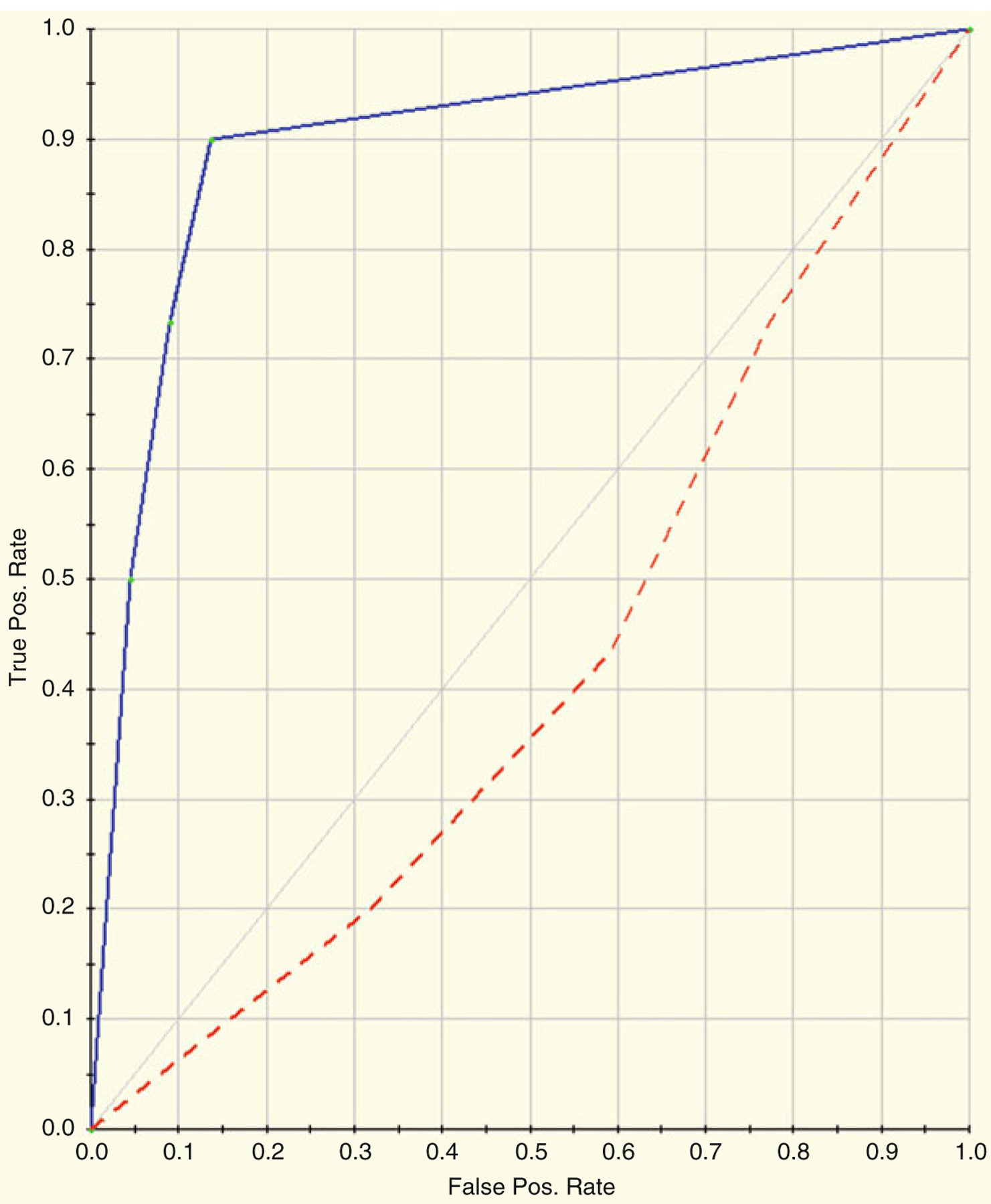
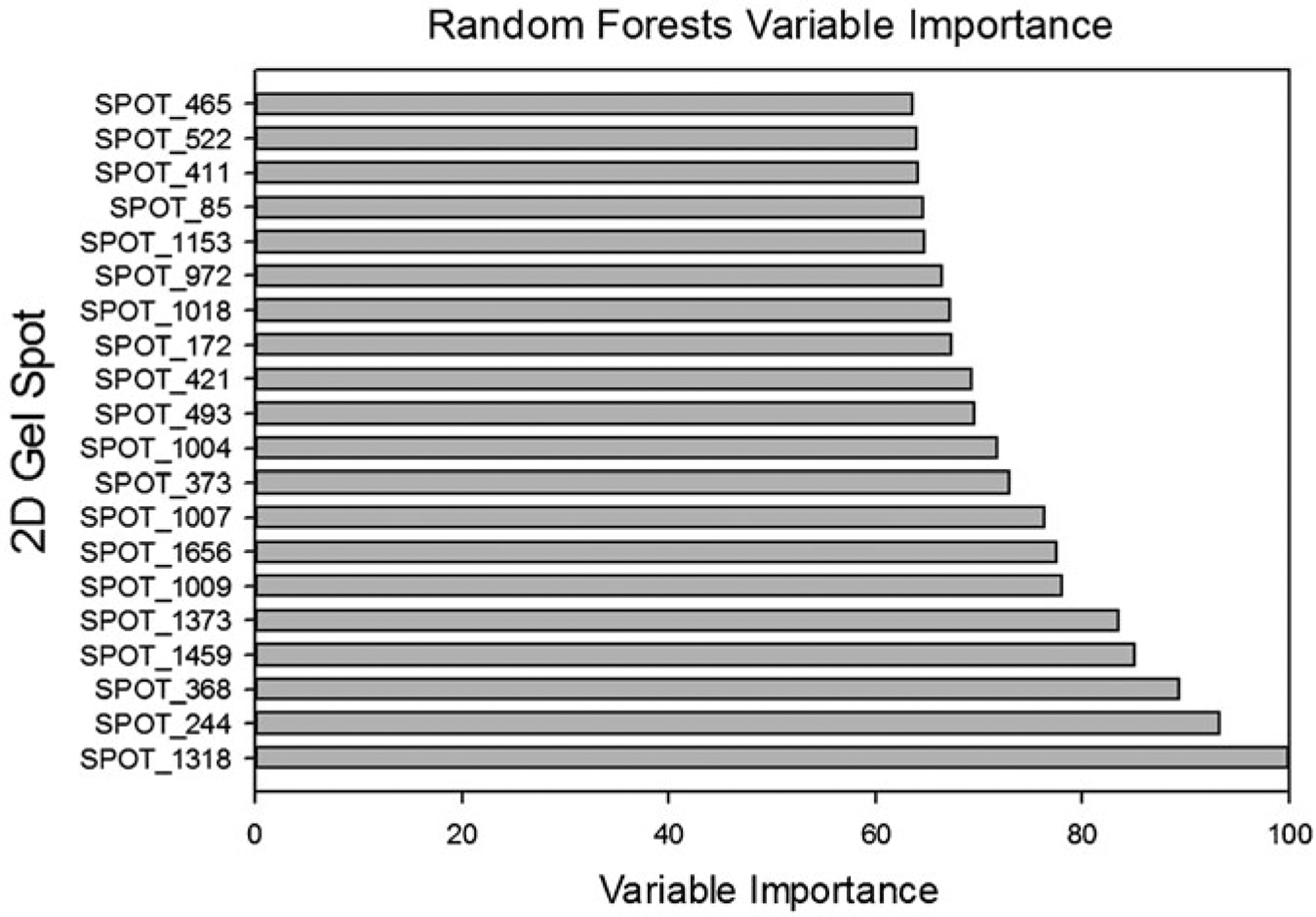
The statistical analysis of robust biomarker candidates is a complex process, and is involved in several key steps in the overall biomarker development pipeline (see Fig. 22.1, Chap. 19 ). Initially, data visualization (Sect. 22.1, below) is important to determine outliers and to get a feel for the nature of the data and whether there appear to be any differences among the groups being examined. From there, the data must be pre-processed (Sect. 22.2) so that outliers are handled, missing values are dealt with, and normality is assessed. Once the processed data has been cleaned and is ready for downstream analysis, hypothesis tests (Sect. 22.3) are performed, and proteins that are differentially expressed are identified. Since the number of differentially expressed proteins is usually larger than warrants further investigation (50+ proteins versus just a handful that will be considered for a biomarker panel), some sort of feature reduction (Sect. 22.4) should be performed to narrow the list of candidate biomarkers down to a more reasonable number. Once the list of proteins has been reduced to those that are likely most useful for downstream classification purposes, unsupervised or supervised learning is performed (Sects. 22.5 and 22.6, respectively).
Keywords: Candidate biomarker selection; Data clustering; Data consistency; Data inspection; Data normalization; Data transformations; Machine learning; Outlier detection.
Figures
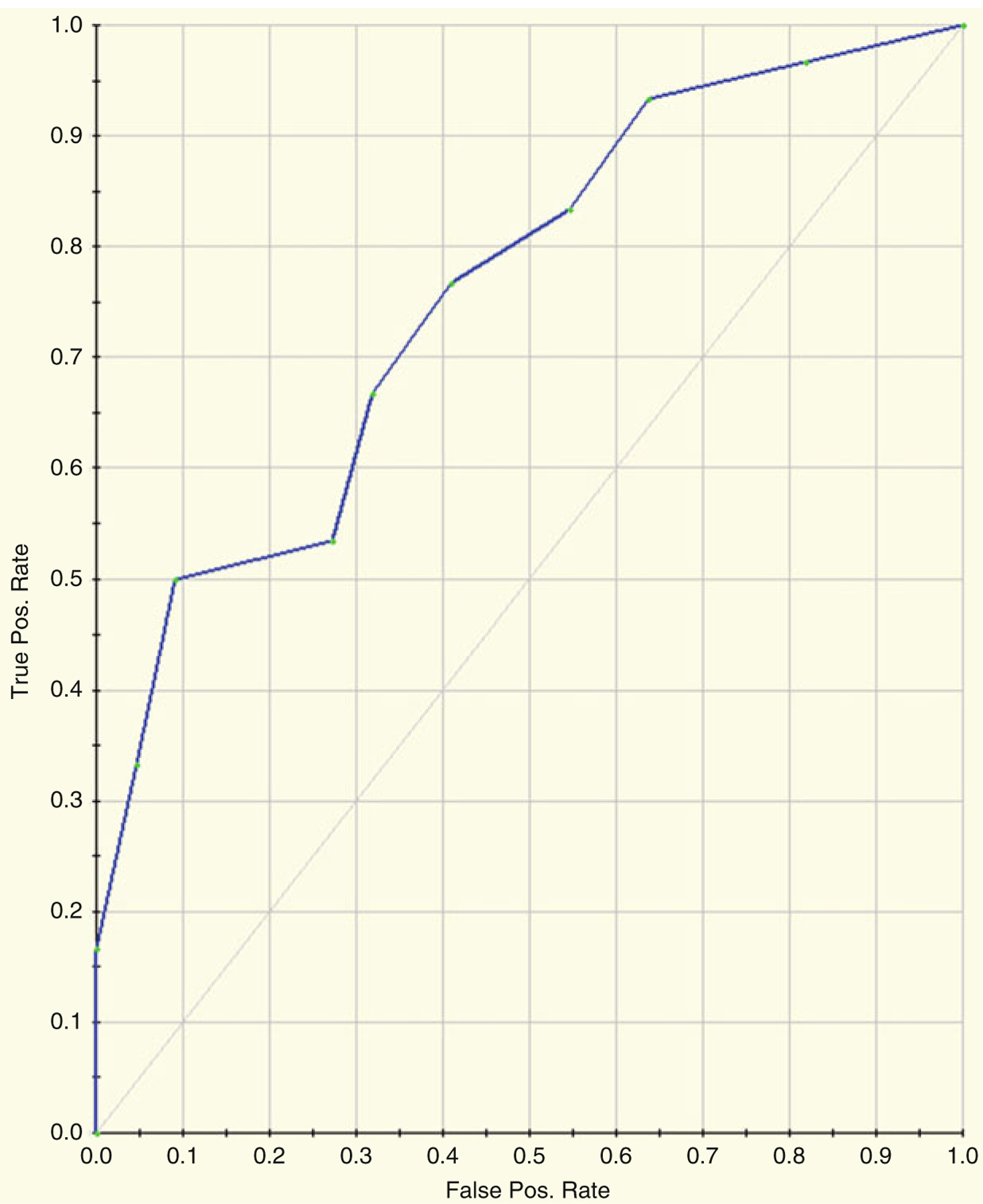
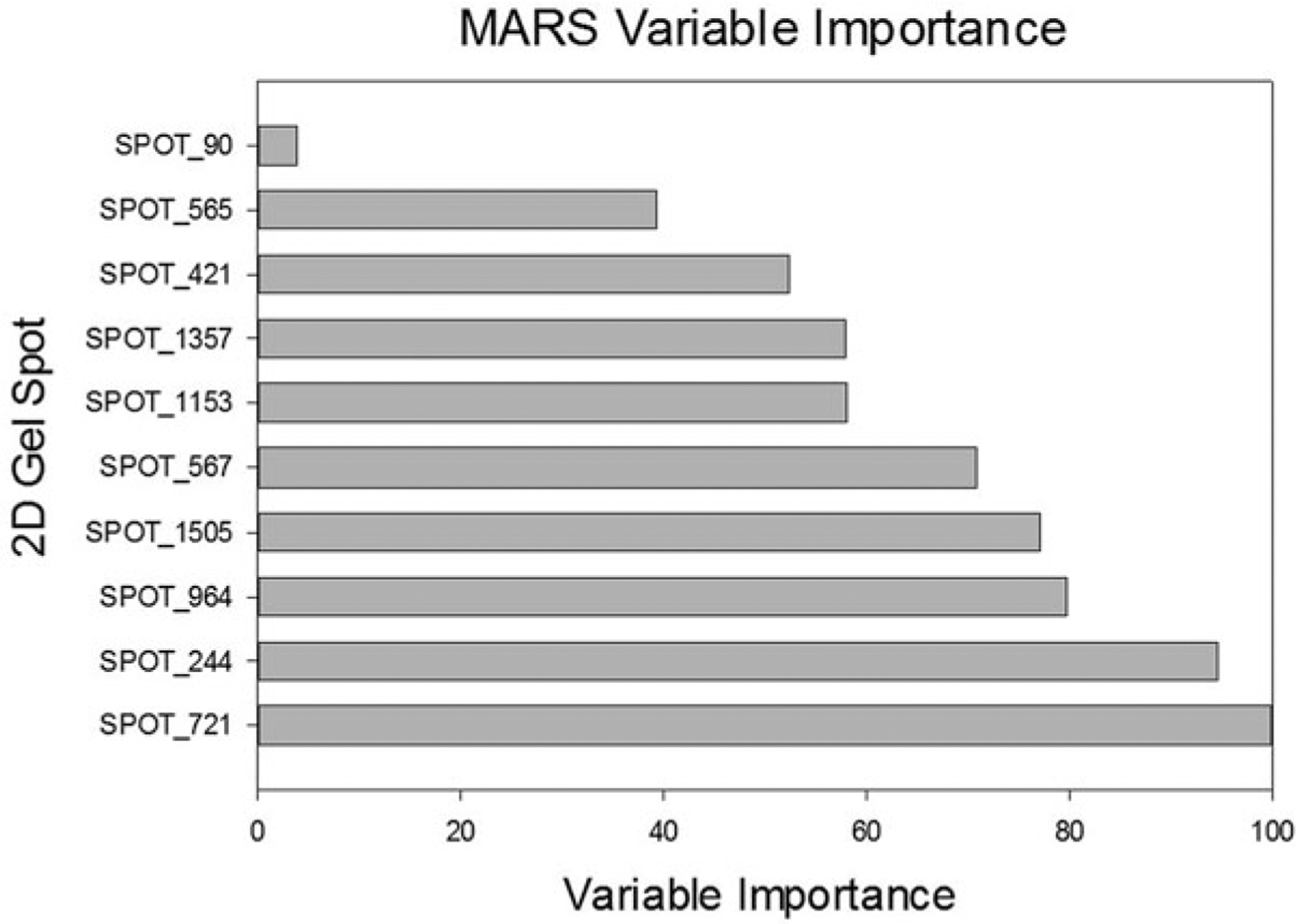
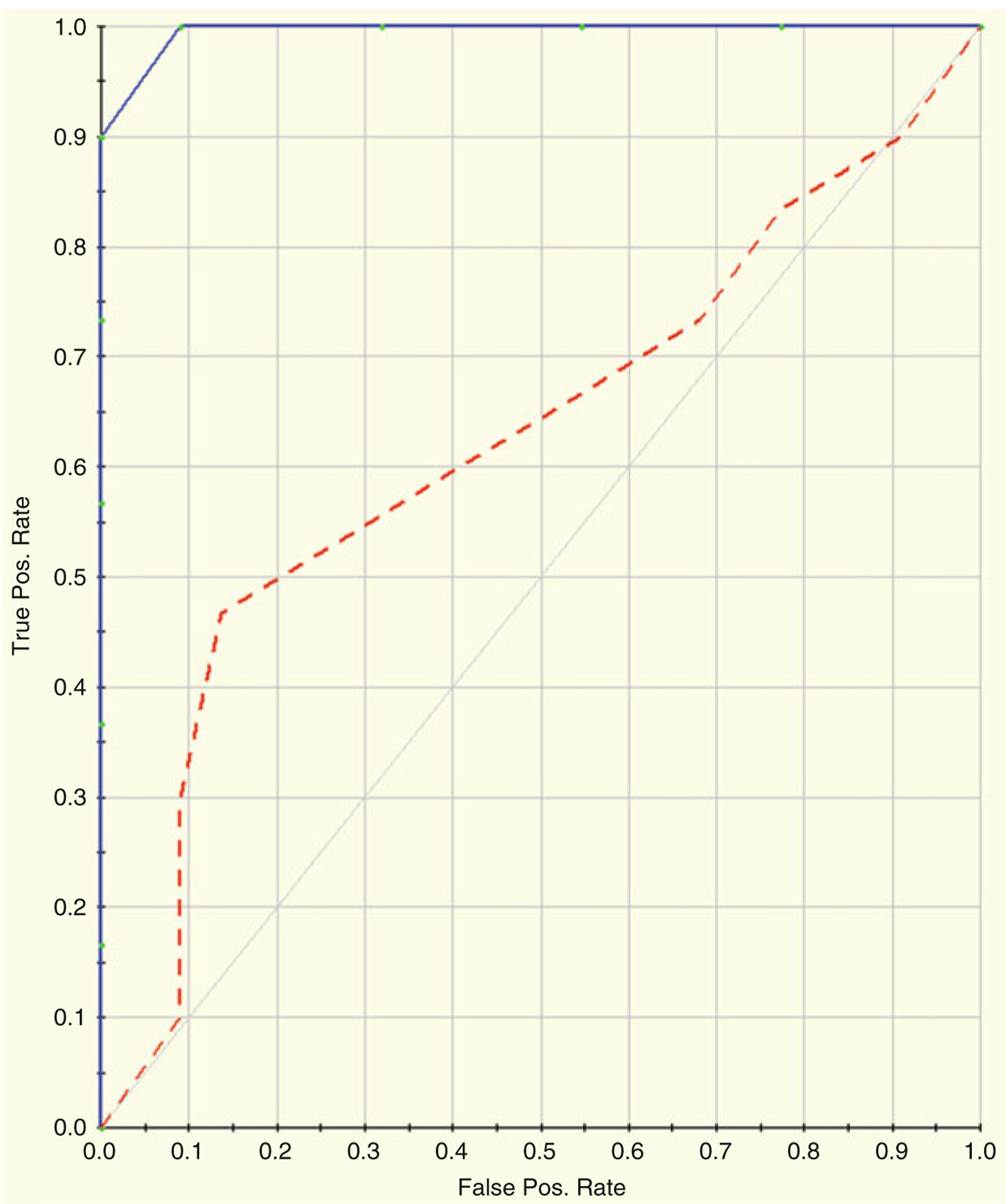
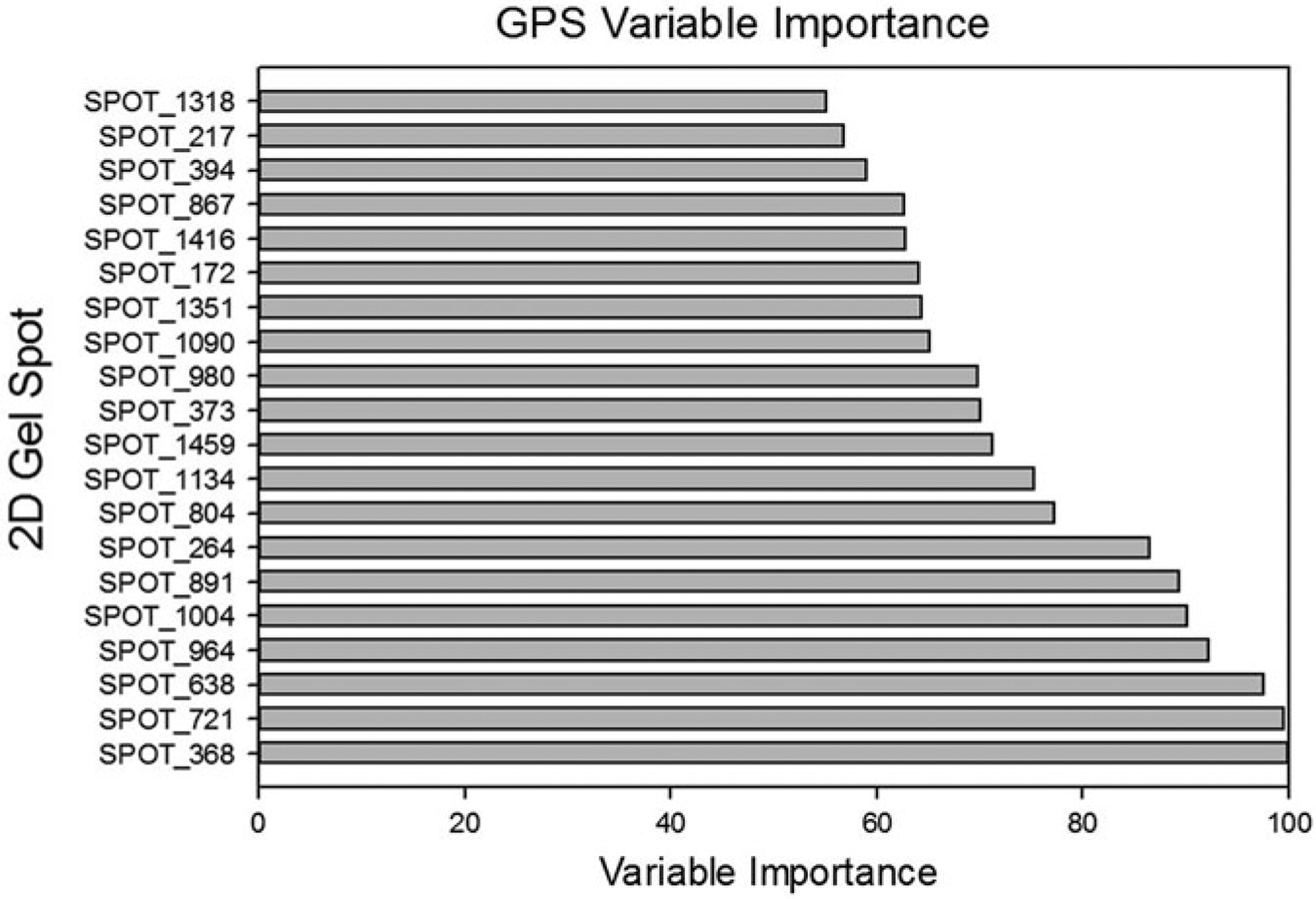
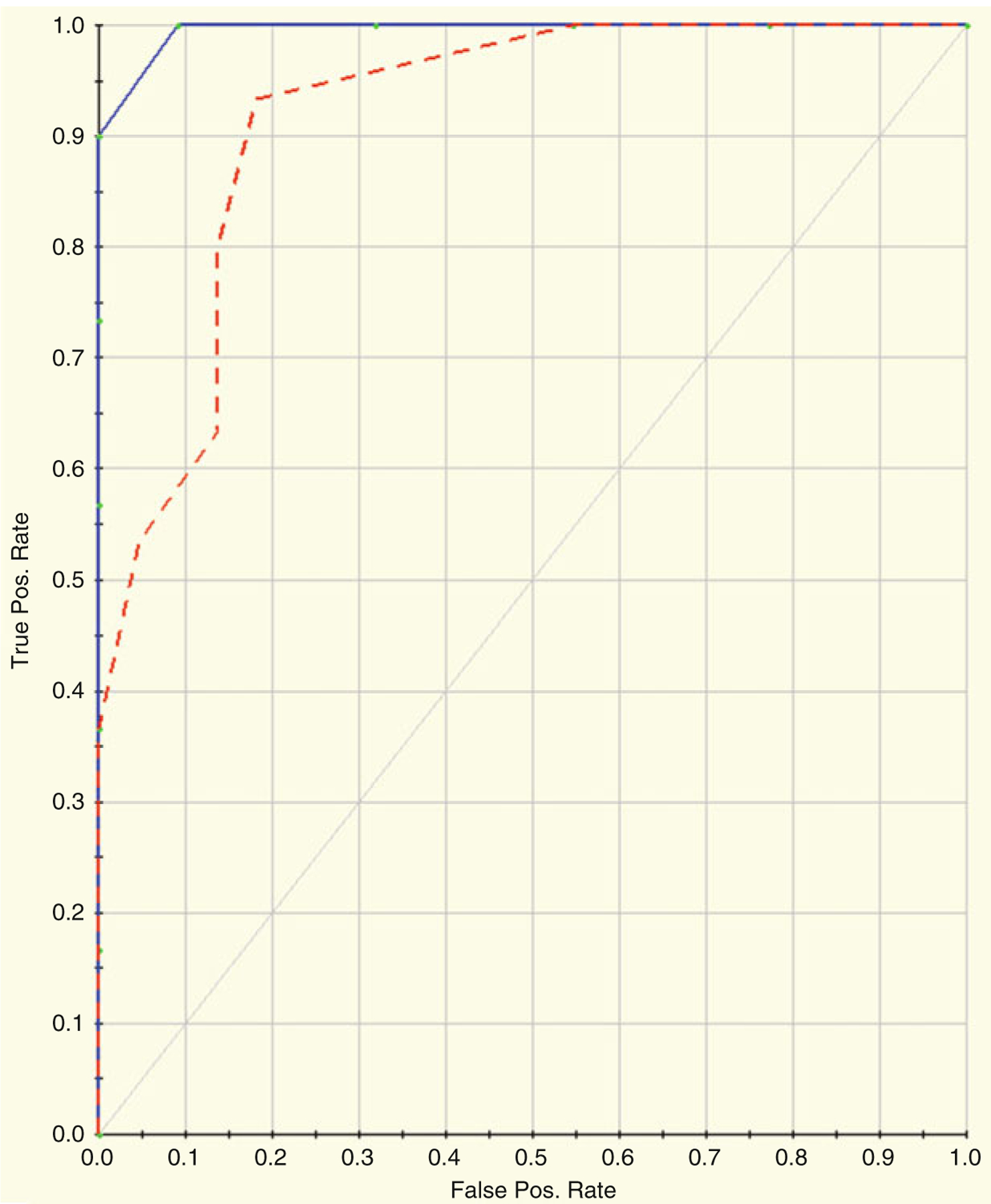
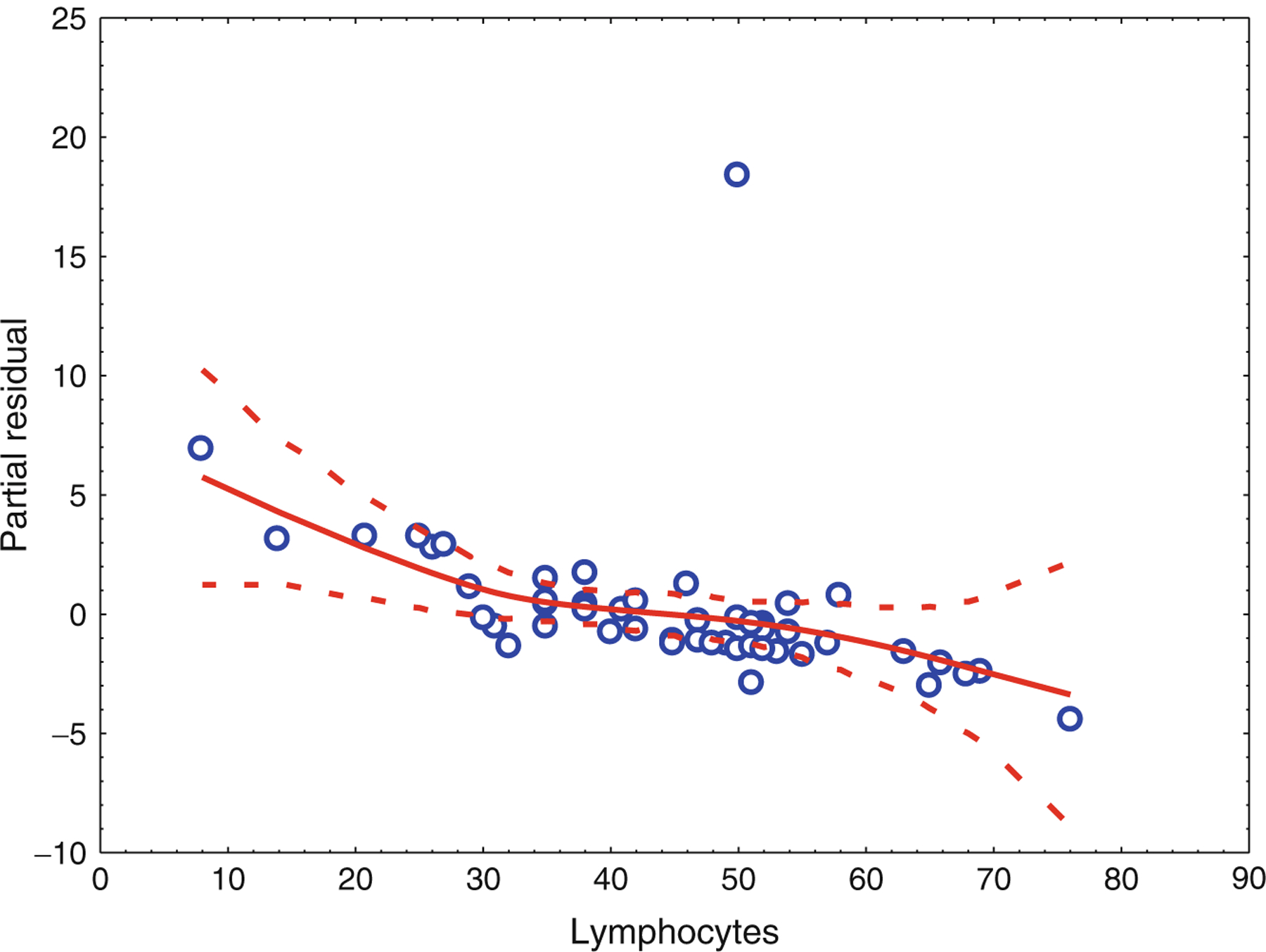
References
-
- Batista G, Monard M (2002) A study of K-nearest neighbour as an imputation method. Hybrid Intelligent Systems, Santiago, Chile, pp 251–260
-
- Benjamini Y, Hochberg Y (1995) Controlling the false discovery rate: a practical and powerful approach to multiple testing. J R Stat Soc Ser B 57:125–133
-
- Breiman L, Friedman J, Olshen R, Stone C (1984) Classification and regression trees. Wadsworth, Belmont
-
- Breiman L (2001) Random forests-random features. University of California, Berkeley
-
- Carroll R, Ruppert A, Stefanski L, Crainiceanu C (2006) Measurement error in nonlinear models: a modern perspective, 2nd edn. CRC Press, London
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
