

A cloud-based workflow to quantify transcript-expression levels in public cancer compendia
- PMID: 27982081
- PMCID: PMC5159871
- DOI: 10.1038/srep39259
A cloud-based workflow to quantify transcript-expression levels in public cancer compendia
Abstract
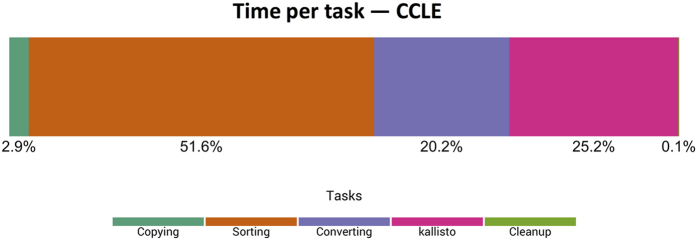
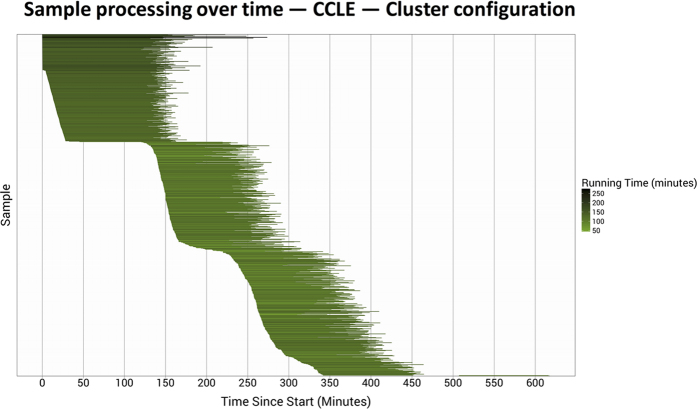
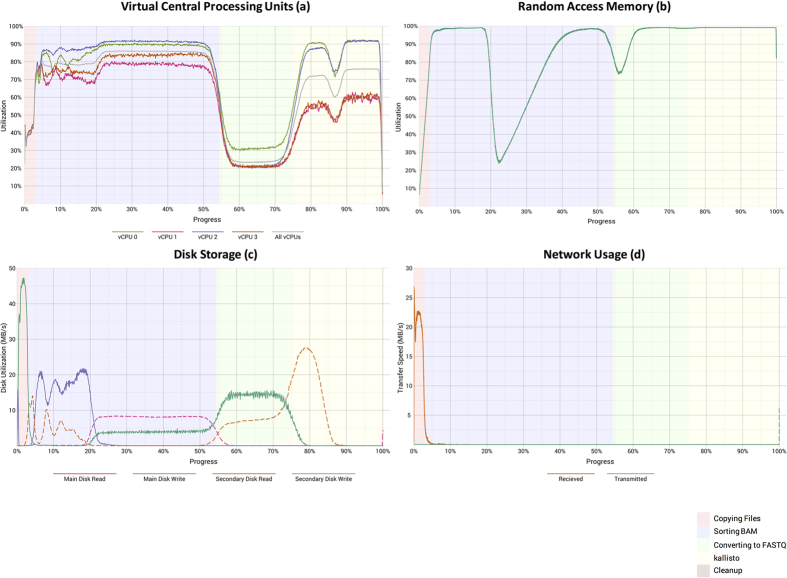
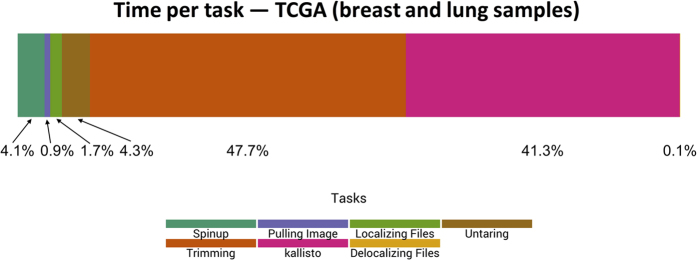
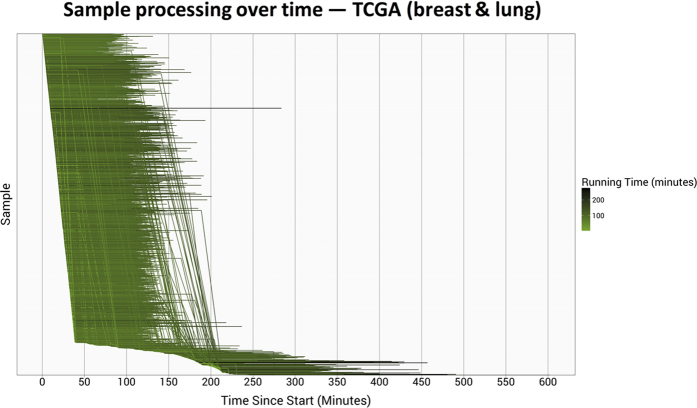
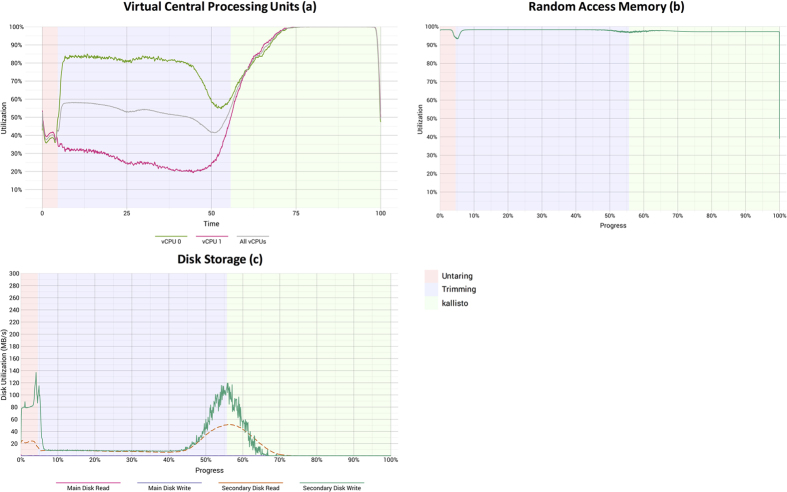
Public compendia of sequencing data are now measured in petabytes. Accordingly, it is infeasible for researchers to transfer these data to local computers. Recently, the National Cancer Institute began exploring opportunities to work with molecular data in cloud-computing environments. With this approach, it becomes possible for scientists to take their tools to the data and thereby avoid large data transfers. It also becomes feasible to scale computing resources to the needs of a given analysis. We quantified transcript-expression levels for 12,307 RNA-Sequencing samples from the Cancer Cell Line Encyclopedia and The Cancer Genome Atlas. We used two cloud-based configurations and examined the performance and cost profiles of each configuration. Using preemptible virtual machines, we processed the samples for as little as $0.09 (USD) per sample. As the samples were processed, we collected performance metrics, which helped us track the duration of each processing step and quantified computational resources used at different stages of sample processing. Although the computational demands of reference alignment and expression quantification have decreased considerably, there remains a critical need for researchers to optimize preprocessing steps. We have stored the software, scripts, and processed data in a publicly accessible repository (https://osf.io/gqrz9).
Figures
Comment in
-
Cheap-seq.Sci Transl Med. 2016 Dec 21;8(370):370ec203. doi: 10.1126/scitranslmed.aal3701. Sci Transl Med. 2016. PMID: 28003542 No abstract available.
References
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
Research Materials
