

Breeding novel solutions in the brain: a model of Darwinian neurodynamics
- PMID: 27990266
- PMCID: PMC5130073
- DOI: 10.12688/f1000research.9630.2
Breeding novel solutions in the brain: a model of Darwinian neurodynamics
Abstract
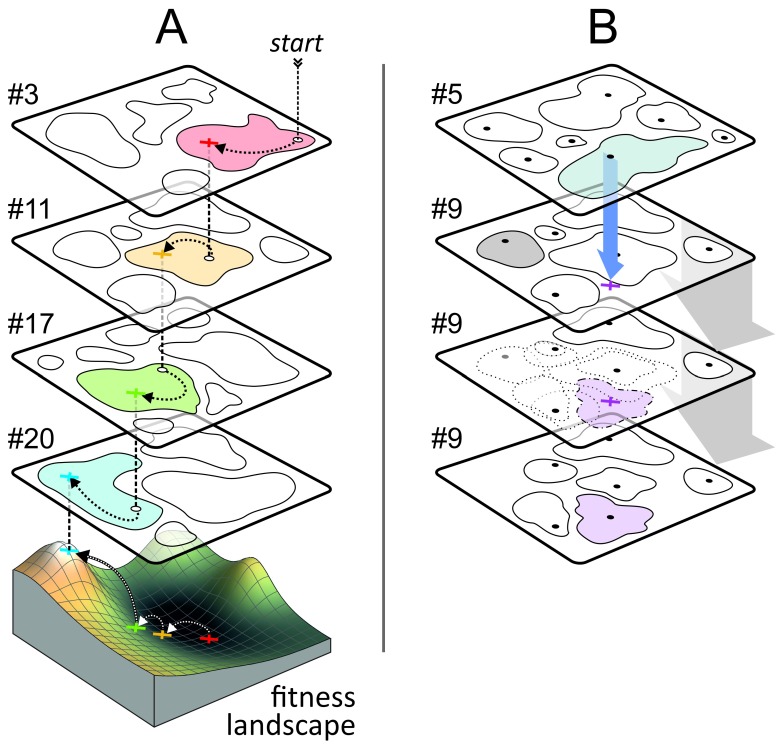
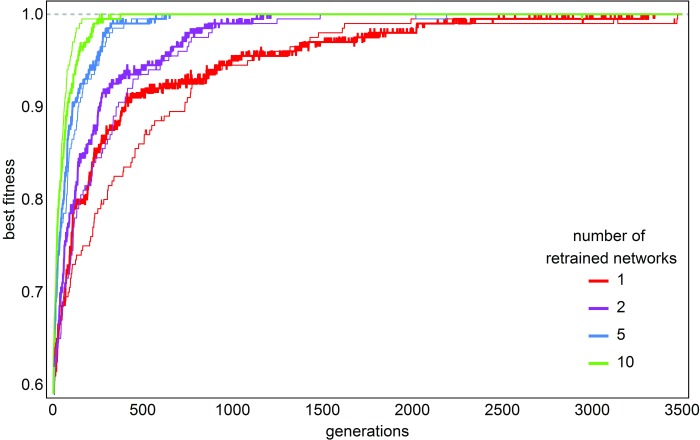
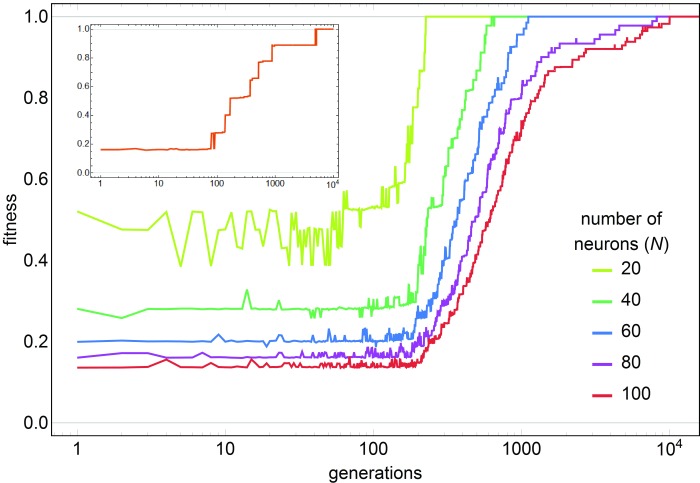
Background: The fact that surplus connections and neurons are pruned during development is well established. We complement this selectionist picture by a proof-of-principle model of evolutionary search in the brain, that accounts for new variations in theory space. We present a model for Darwinian evolutionary search for candidate solutions in the brain. Methods: We combine known components of the brain - recurrent neural networks (acting as attractors), the action selection loop and implicit working memory - to provide the appropriate Darwinian architecture. We employ a population of attractor networks with palimpsest memory. The action selection loop is employed with winners-share-all dynamics to select for candidate solutions that are transiently stored in implicit working memory. Results: We document two processes: selection of stored solutions and evolutionary search for novel solutions. During the replication of candidate solutions attractor networks occasionally produce recombinant patterns, increasing variation on which selection can act. Combinatorial search acts on multiplying units (activity patterns) with hereditary variation and novel variants appear due to (i) noisy recall of patterns from the attractor networks, (ii) noise during transmission of candidate solutions as messages between networks, and, (iii) spontaneously generated, untrained patterns in spurious attractors. Conclusions: Attractor dynamics of recurrent neural networks can be used to model Darwinian search. The proposed architecture can be used for fast search among stored solutions (by selection) and for evolutionary search when novel candidate solutions are generated in successive iterations. Since all the suggested components are present in advanced nervous systems, we hypothesize that the brain could implement a truly evolutionary combinatorial search system, capable of generating novel variants.
Keywords: Darwinian dynamics; attractor network; autoassociative neural network; evolutionary search; learning; neurodynamics; problem solving.
Conflict of interest statement
Competing interests: No competing interests were disclosed.
Figures


References
-
- Changeux JP: Neuronal man: The biology of mind. Princeton, NJ: Princeton University Press; Translated by Garey, L. 1985. Reference Source
-
- Edelman GM: Neural Darwinism. The theory of neuronal group selection. New York: Basic Books;1987. Reference Source - PubMed
LinkOut - more resources
Full Text Sources
Other Literature Sources