

Multi-Objective Markov Decision Processes for Data-Driven Decision Support
- PMID: 28018133
- PMCID: PMC5179144
Multi-Objective Markov Decision Processes for Data-Driven Decision Support
Abstract
We present new methodology based on Multi-Objective Markov Decision Processes for developing sequential decision support systems from data. Our approach uses sequential decision-making data to provide support that is useful to many different decision-makers, each with different, potentially time-varying preference. To accomplish this, we develop an extension of fitted-Q iteration for multiple objectives that computes policies for all scalarization functions, i.e. preference functions, simultaneously from continuous-state, finite-horizon data. We identify and address several conceptual and computational challenges along the way, and we introduce a new solution concept that is appropriate when different actions have similar expected outcomes. Finally, we demonstrate an application of our method using data from the Clinical Antipsychotic Trials of Intervention Effectiveness and show that our approach offers decision-makers increased choice by a larger class of optimal policies.
Keywords: Markov decision processes; clinical decision support; evidence-based medicine; multi-objective optimization; reinforcement learning.
Figures
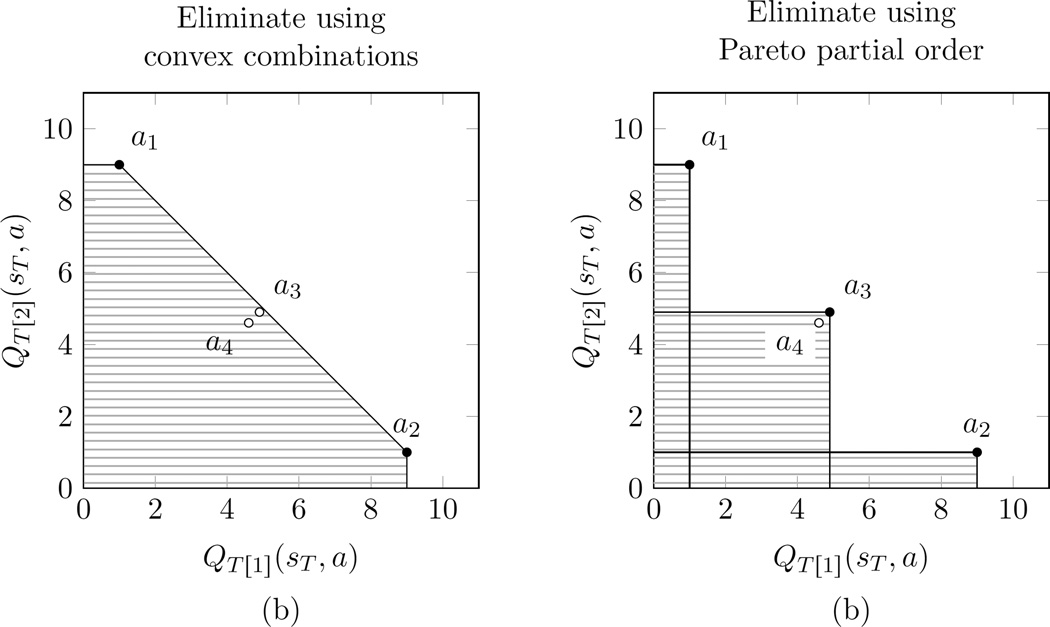
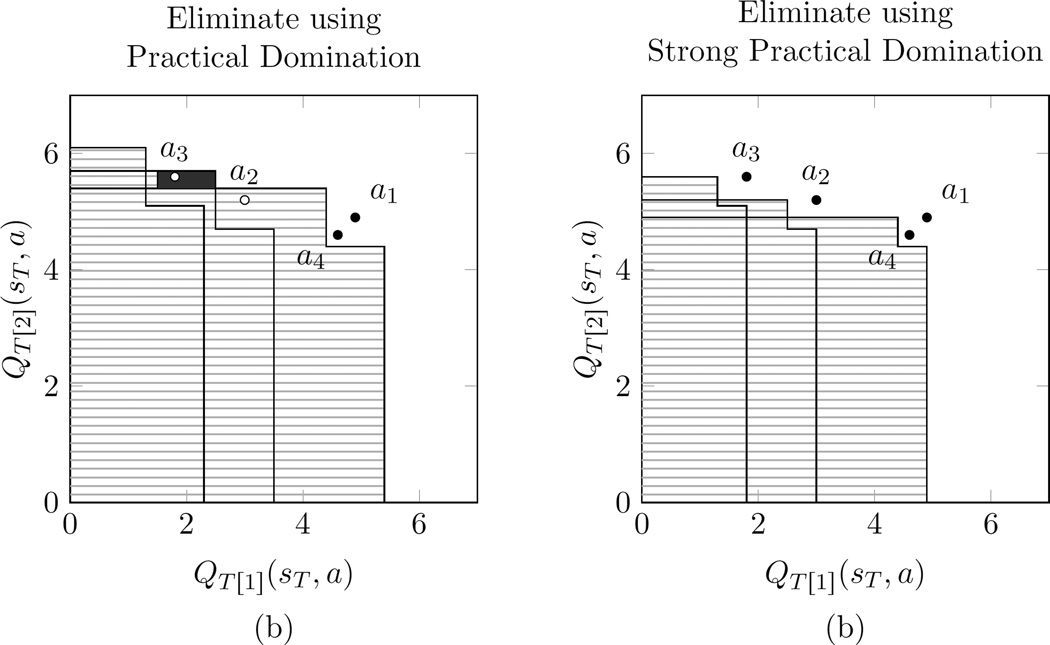
 ,
,  ,
,  ,
,  ,
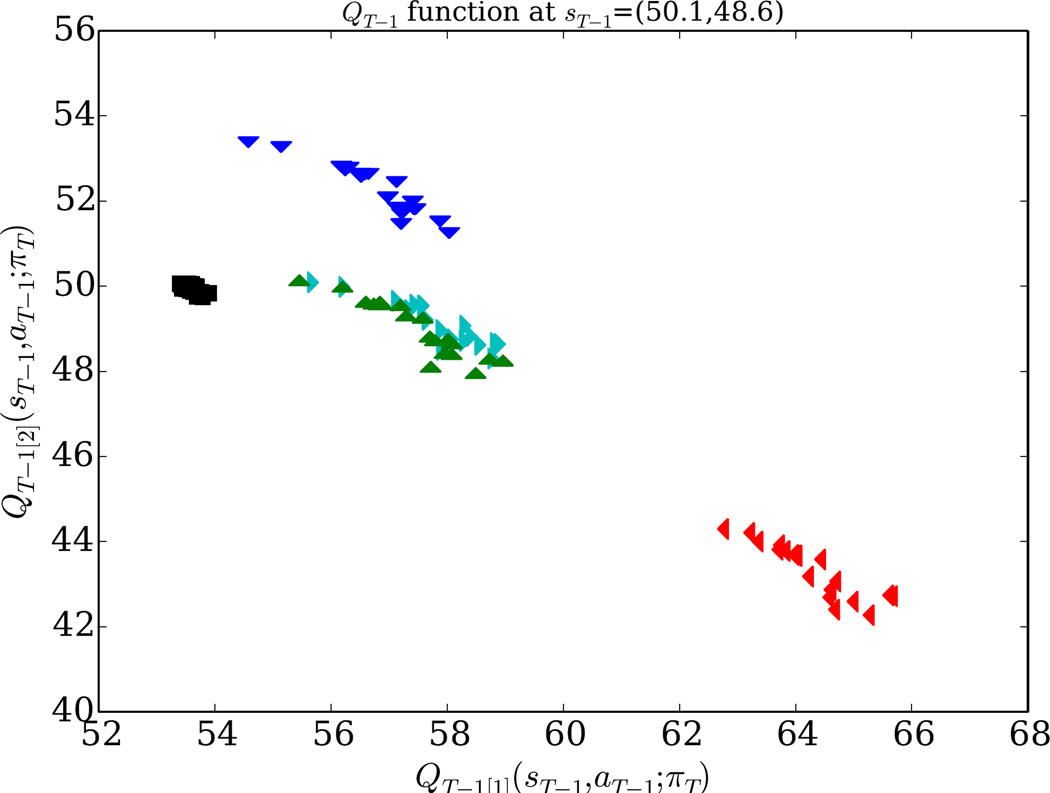
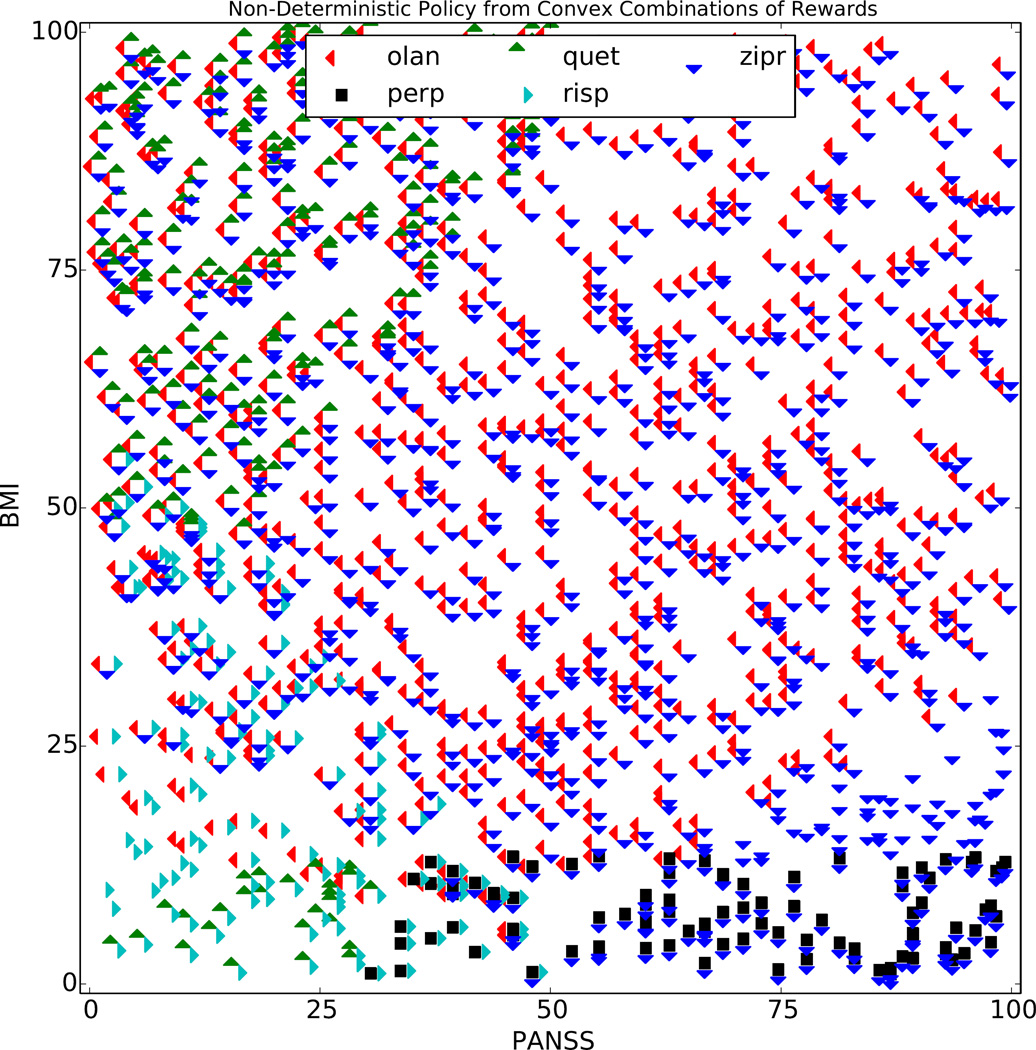
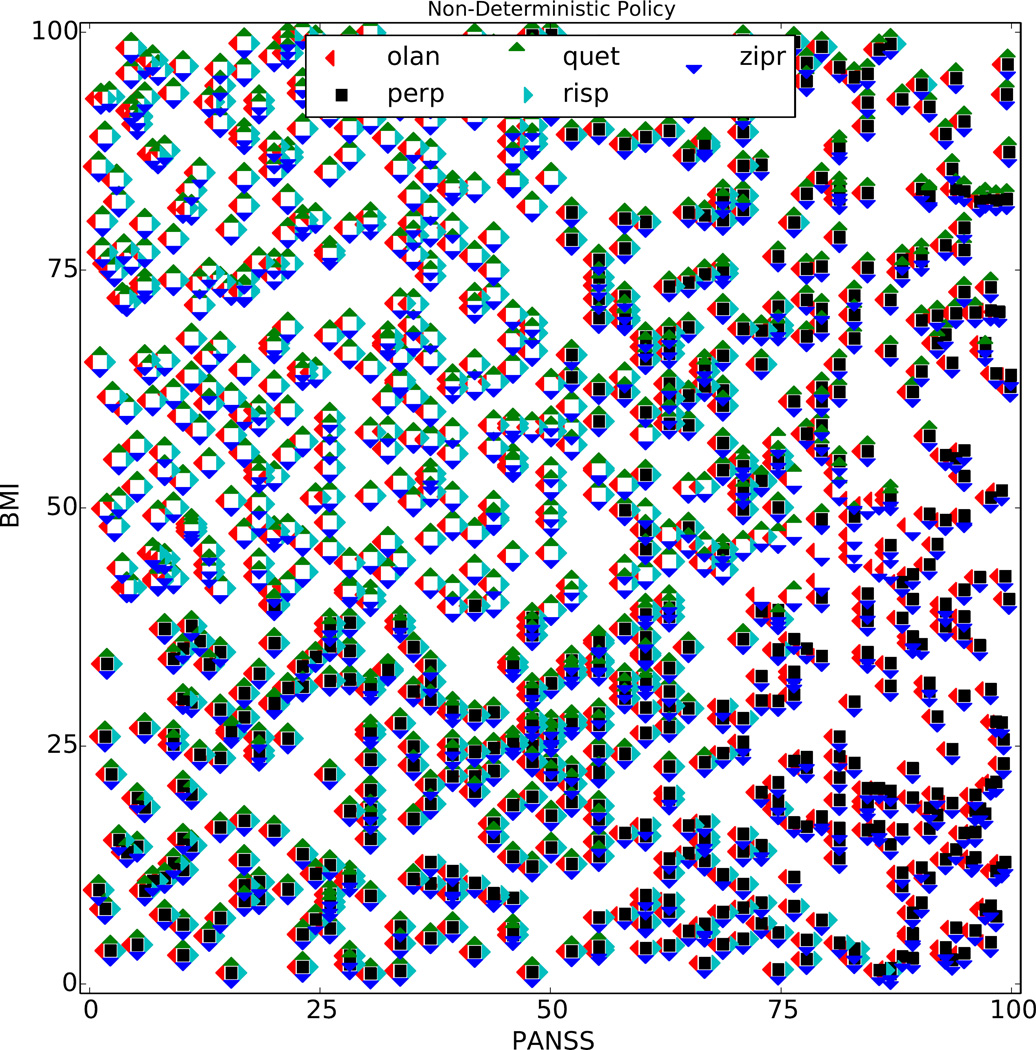
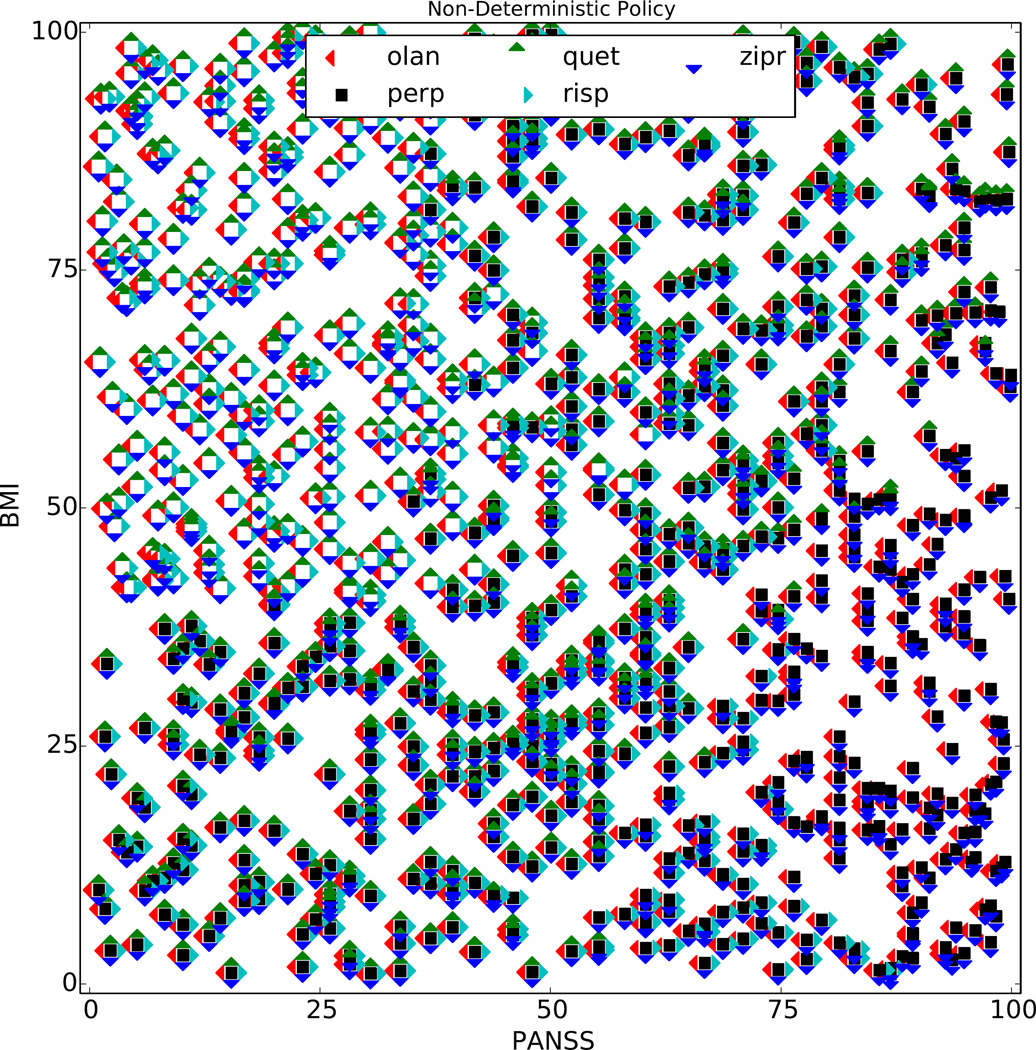
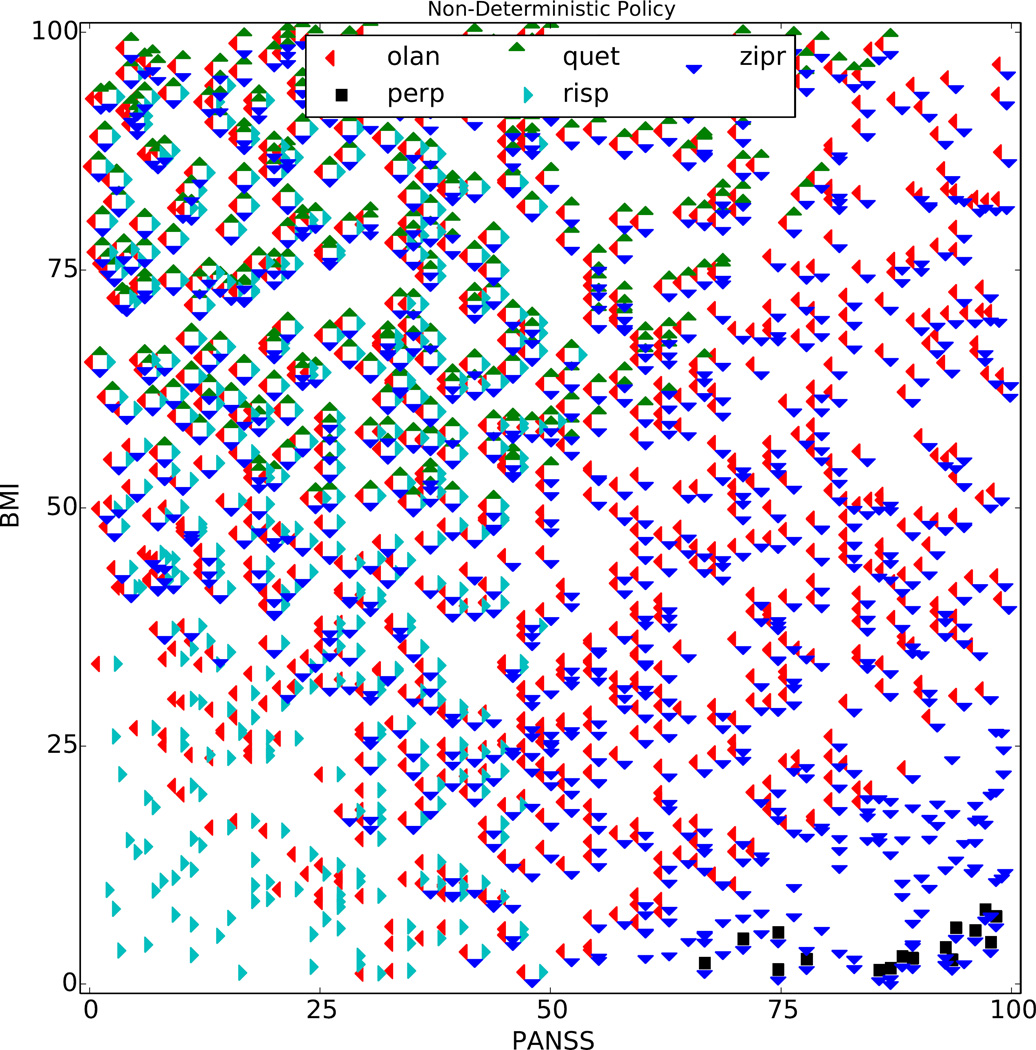
,  }. For example, the markers near the top of the plot correspond to expected returns for each Q̂ ∈ 𝒬T that is achievable by taking the action at the current time point and then following a particular future policy. This example 𝒬T−1 contains 20 Q̂T−1 functions, each assuming a different πT.
}. For example, the markers near the top of the plot correspond to expected returns for each Q̂ ∈ 𝒬T that is achievable by taking the action at the current time point and then following a particular future policy. This example 𝒬T−1 contains 20 Q̂T−1 functions, each assuming a different πT.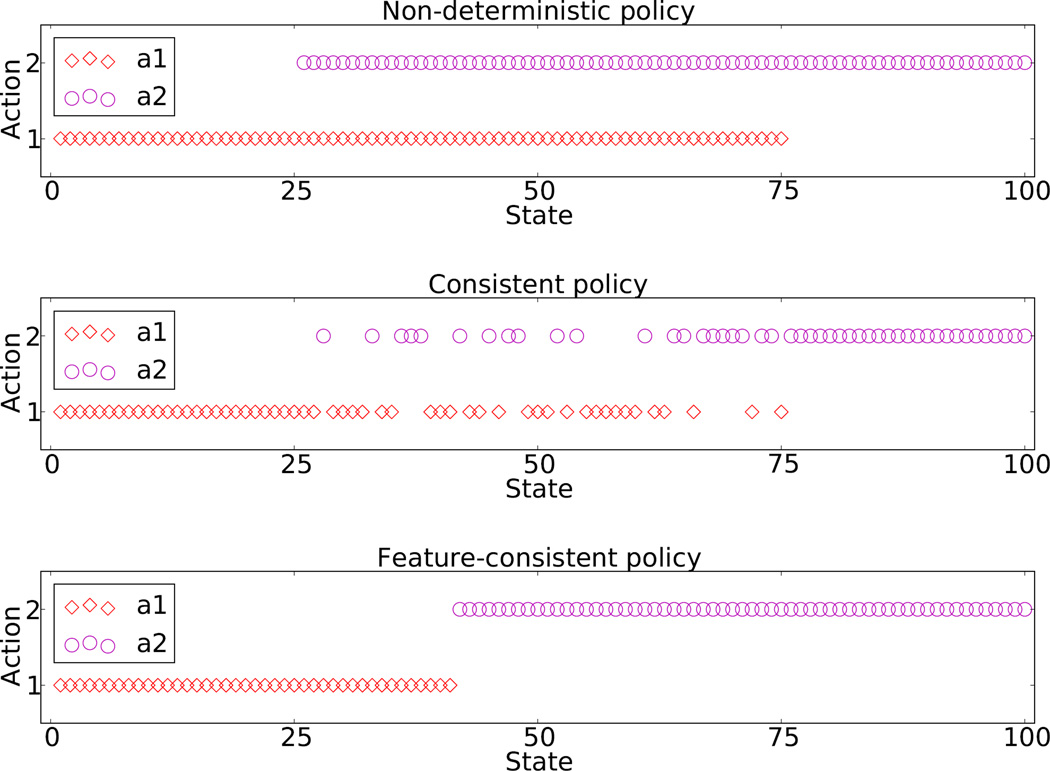
Similar articles
-
Evolving Robust Policy Coverage Sets in Multi-Objective Markov Decision Processes Through Intrinsically Motivated Self-Play.Front Neurorobot. 2018 Oct 9;12:65. doi: 10.3389/fnbot.2018.00065. eCollection 2018. Front Neurorobot. 2018. PMID: 30356836 Free PMC article.
-
Linear Fitted-Q Iteration with Multiple Reward Functions.J Mach Learn Res. 2012 Nov;13(Nov):3253-3295. J Mach Learn Res. 2012. PMID: 23741197 Free PMC article.
-
Optimization of anemia treatment in hemodialysis patients via reinforcement learning.Artif Intell Med. 2014 Sep;62(1):47-60. doi: 10.1016/j.artmed.2014.07.004. Epub 2014 Jul 19. Artif Intell Med. 2014. PMID: 25091172
-
A Promising Approach to Optimizing Sequential Treatment Decisions for Depression: Markov Decision Process.Pharmacoeconomics. 2022 Nov;40(11):1015-1032. doi: 10.1007/s40273-022-01185-z. Epub 2022 Sep 14. Pharmacoeconomics. 2022. PMID: 36100825 Free PMC article. Review.
-
[Mathematical models of decision making and learning].Brain Nerve. 2008 Jul;60(7):791-8. Brain Nerve. 2008. PMID: 18646619 Review. Japanese.
Cited by
-
Bayesian Nonparametric Policy Search with Application to Periodontal Recall Intervals.J Am Stat Assoc. 2020;115(531):1066-1078. doi: 10.1080/01621459.2019.1660169. Epub 2019 Oct 9. J Am Stat Assoc. 2020. PMID: 33012901 Free PMC article.
-
Quantiles based personalized treatment selection for multivariate outcomes and multiple treatments.Stat Med. 2022 Jul 10;41(15):2695-2710. doi: 10.1002/sim.9377. Epub 2022 Mar 16. Stat Med. 2022. PMID: 35699385 Free PMC article.
-
Multi-Response Based Personalized Treatment Selection with Data from Crossover Designs for Multiple Treatments.Commun Stat Simul Comput. 2022;51(2):554-569. doi: 10.1080/03610918.2019.1656739. Epub 2019 Sep 10. Commun Stat Simul Comput. 2022. PMID: 35299995 Free PMC article.
-
An Optimal Policy for Patient Laboratory Tests in Intensive Care Units.Pac Symp Biocomput. 2019;24:320-331. Pac Symp Biocomput. 2019. PMID: 30864333 Free PMC article.
-
Precision Medicine.Annu Rev Stat Appl. 2019 Mar;6:263-286. doi: 10.1146/annurev-statistics-030718-105251. Annu Rev Stat Appl. 2019. PMID: 31073534 Free PMC article.
References
-
- Allison DB, Mentore JL, Heo M, Chandler LP, Cappelleri JC, Infante MC, Weiden PJ. Antipsychotic-induced weight gain: A comprehensive research synthesis. American Journal of Psychiatry. 1999 Nov;156:1686–1696. - PubMed
-
- Bertsekas DP. Dynamic Programming and Optimal Control, Vol. II. 3rd. Athena Scientific; 2007. ISBN 1886529302, 9781886529304.
-
- Bertsekas DP, Tsitsiklis JN. Neuro-Dynamic Programming. chapter 2.1. Athena Scientific; 1996. p. 12.
-
- Blatt D, Murphy SA, Zhu J. Technical Report 04-63. The Methodology Center, Penn. State University; 2004. A-learning for approximate planning.
Grants and funding
LinkOut - more resources
Full Text Sources