

Drug Response Prediction as a Link Prediction Problem
- PMID: 28067293
- PMCID: PMC5220354
- DOI: 10.1038/srep40321
Drug Response Prediction as a Link Prediction Problem
Erratum in
-
Corrigendum: Drug Response Prediction as a Link Prediction Problem.Sci Rep. 2017 Mar 23;7:44961. doi: 10.1038/srep44961. Sci Rep. 2017. PMID: 28332499 Free PMC article. No abstract available.
Abstract
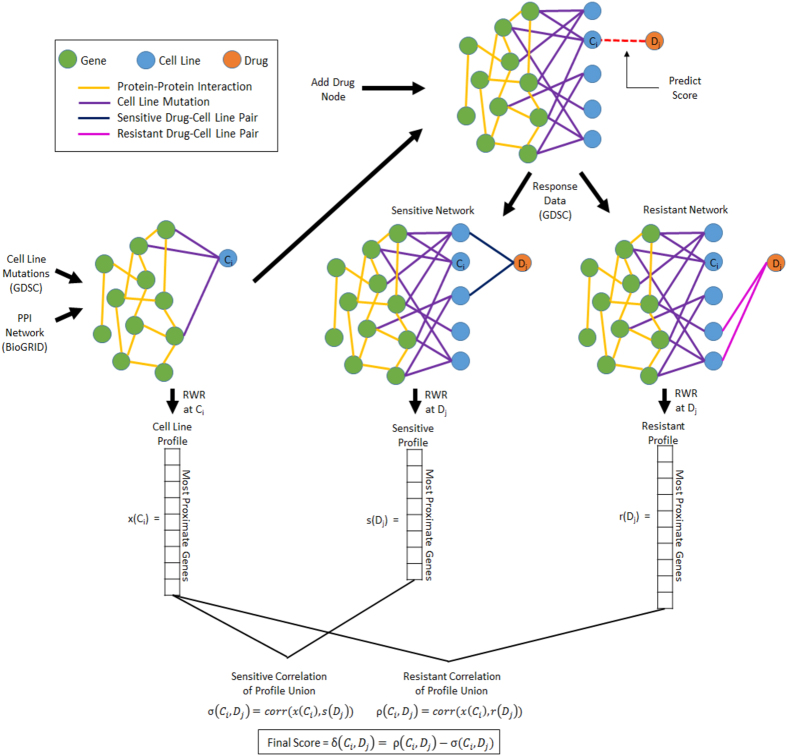
Drug response prediction is a well-studied problem in which the molecular profile of a given sample is used to predict the effect of a given drug on that sample. Effective solutions to this problem hold the key for precision medicine. In cancer research, genomic data from cell lines are often utilized as features to develop machine learning models predictive of drug response. Molecular networks provide a functional context for the integration of genomic features, thereby resulting in robust and reproducible predictive models. However, inclusion of network data increases dimensionality and poses additional challenges for common machine learning tasks. To overcome these challenges, we here formulate drug response prediction as a link prediction problem. For this purpose, we represent drug response data for a large cohort of cell lines as a heterogeneous network. Using this network, we compute "network profiles" for cell lines and drugs. We then use the associations between these profiles to predict links between drugs and cell lines. Through leave-one-out cross validation and cross-classification on independent datasets, we show that this approach leads to accurate and reproducible classification of sensitive and resistant cell line-drug pairs, with 85% accuracy. We also examine the biological relevance of the network profiles.
Figures





References
-
- Meyerson M., Gabriel S. & Getz G. Advances in understanding cancer genomes through second-generation sequencing. Nature Publishing Group 11, 685–696 (2010). - PubMed
-
- Buermans H. P. J. & den Dunnen J. T. Next generation sequencing technology : Advances and applications. Biochimica et Biophysica Acta 1842, 1932–1941 ( 2014). - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
