

RNA-binding specificity landscape of the pentatricopeptide repeat protein PPR10
- PMID: 28108520
- PMCID: PMC5340921
- DOI: 10.1261/rna.059568.116
RNA-binding specificity landscape of the pentatricopeptide repeat protein PPR10
Abstract
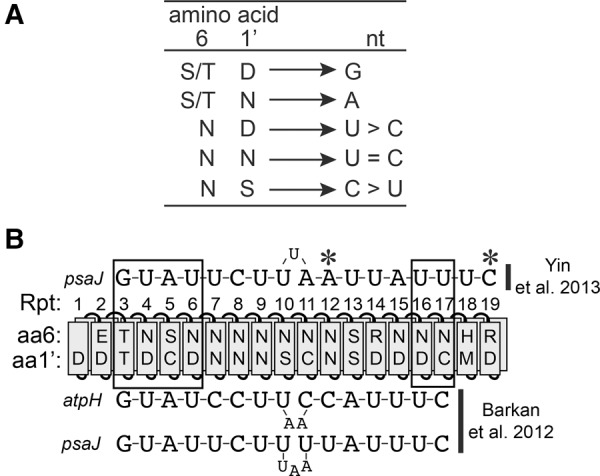
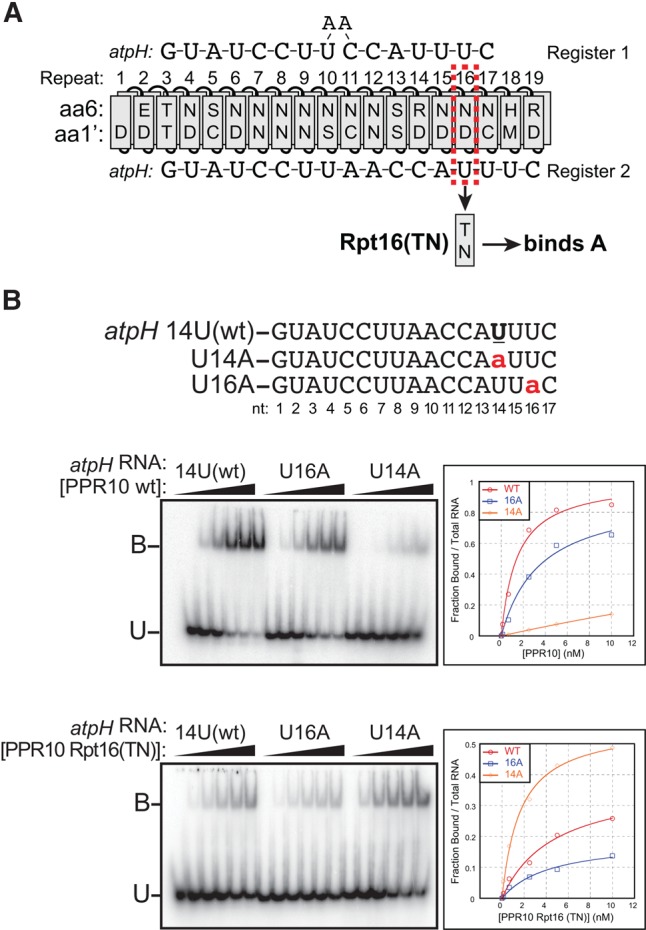
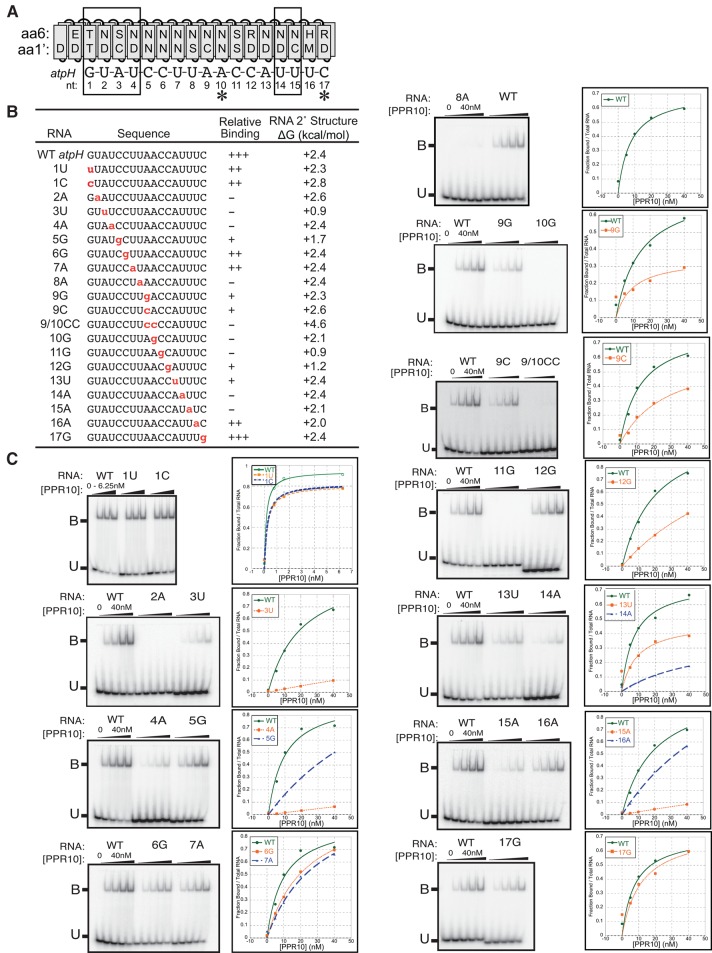
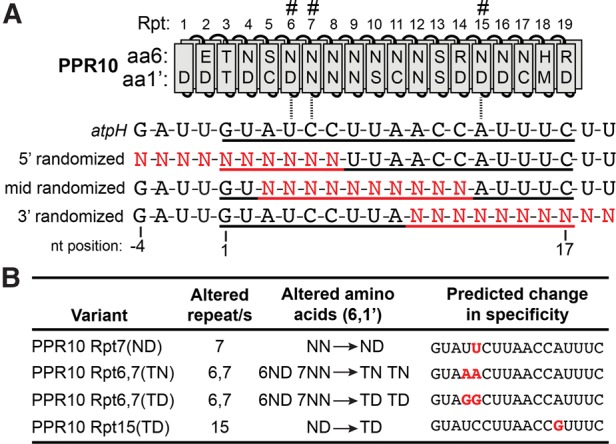
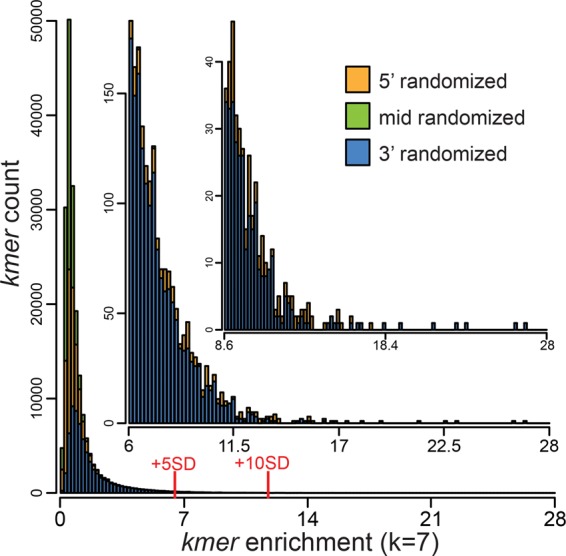
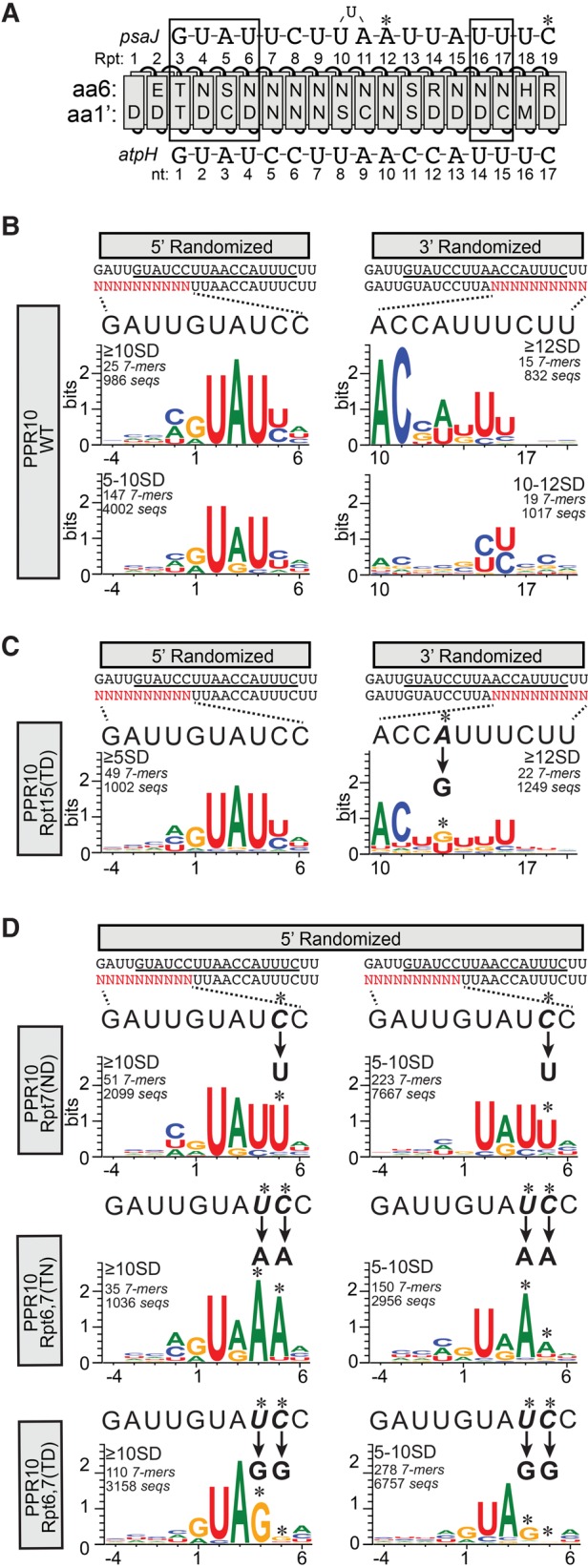
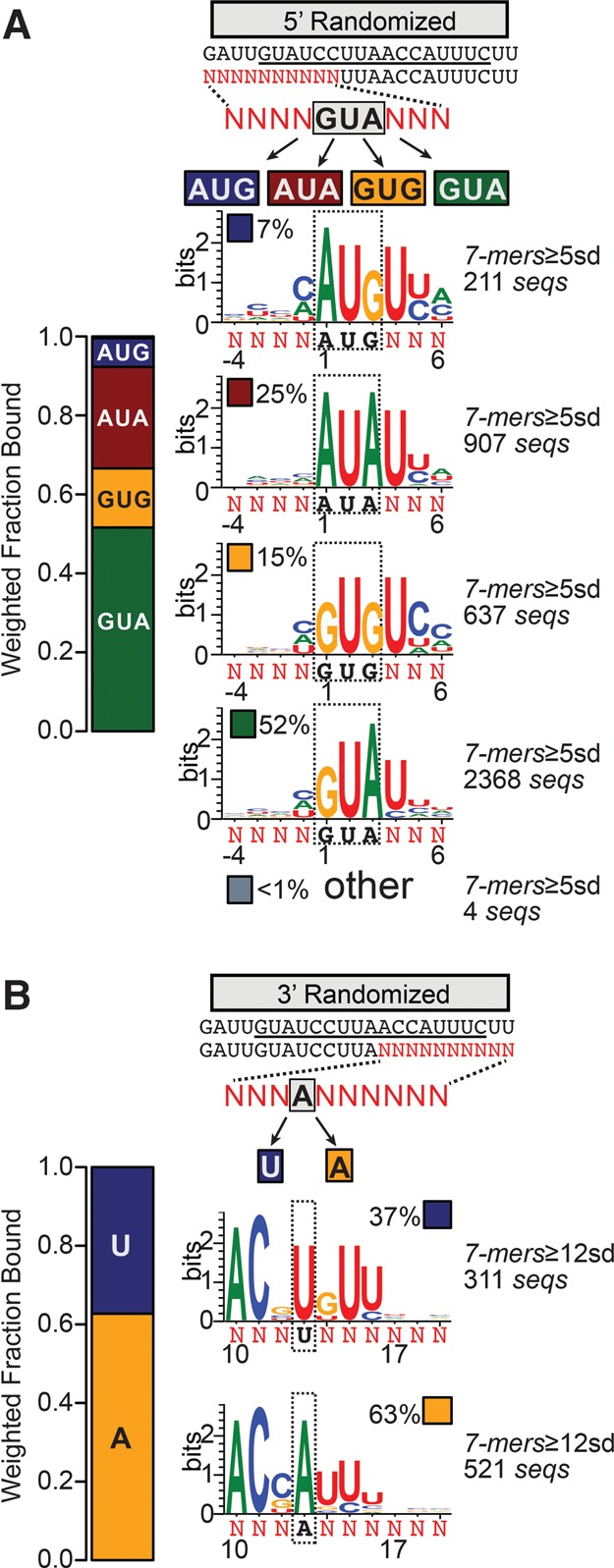
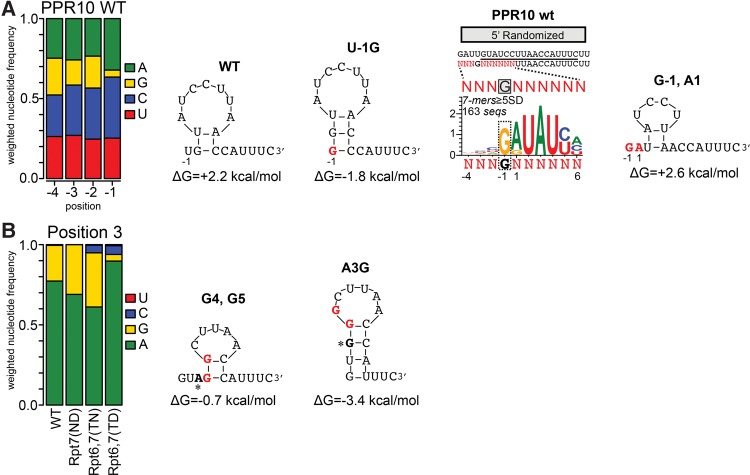
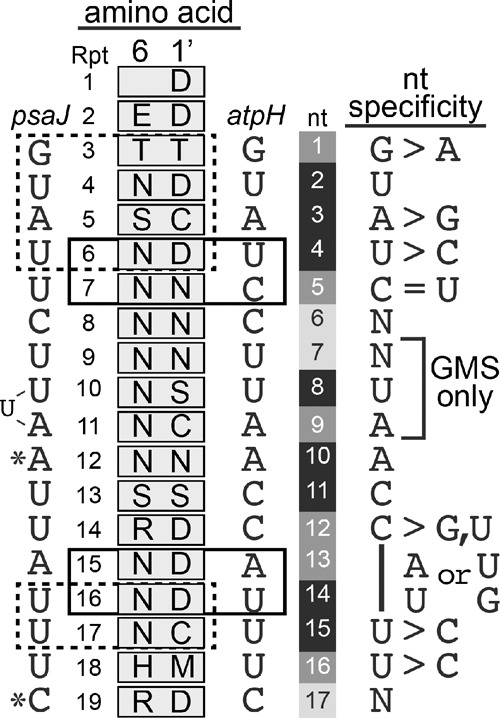
Pentatricopeptide repeat (PPR) proteins comprise a large family of helical repeat proteins that influence gene expression in mitochondria and chloroplasts. PPR tracts can bind RNA via a modular one repeat-one nucleotide mechanism in which the nucleotide is specified by the identities of several amino acids in each repeat. This mode of recognition, the so-called PPR code, offers opportunities for the prediction of native PPR binding sites and the design of proteins to bind specified RNAs. However, a deep understanding of the parameters that dictate the affinity and specificity of PPR-RNA interactions is necessary to realize these goals. We report a comprehensive analysis of the sequence specificity of PPR10, a protein that binds similar RNA sequences of ∼18 nucleotides (nt) near the chloroplast atpH and psaJ genes in maize. We assessed the contribution of each nucleotide in the atpH binding site to PPR10 affinity in vitro by analyzing the effects of single-nucleotide changes at each position. In a complementary approach, the RNAs bound by PPR10 from partially randomized RNA pools were analyzed by deep sequencing. The results revealed three patches in which nucleotide identity has a major impact on binding affinity. These include 5 nt for which protein contacts were not observed in a PPR10-RNA crystal structure and 4 nt that are not explained by current views of the PPR code. These findings highlight aspects of PPR-RNA interactions that pose challenges for binding site prediction and design.
Keywords: RNA-binding protein; bind-n-seq; chloroplast; helical repeat protein.
© 2017 Miranda et al.; Published by Cold Spring Harbor Laboratory Press for the RNA Society.
Figures
Similar articles
-
Unexpected functional versatility of the pentatricopeptide repeat proteins PGR3, PPR5 and PPR10.Nucleic Acids Res. 2018 Nov 2;46(19):10448-10459. doi: 10.1093/nar/gky737. Nucleic Acids Res. 2018. PMID: 30125002 Free PMC article.
-
The solution structure of the pentatricopeptide repeat protein PPR10 upon binding atpH RNA.Nucleic Acids Res. 2015 Feb 18;43(3):1918-26. doi: 10.1093/nar/gkv027. Epub 2015 Jan 21. Nucleic Acids Res. 2015. PMID: 25609698 Free PMC article.
-
Structural basis for the modular recognition of single-stranded RNA by PPR proteins.Nature. 2013 Dec 5;504(7478):168-71. doi: 10.1038/nature12651. Epub 2013 Oct 27. Nature. 2013. PMID: 24162847
-
Mechanistic insight into pentatricopeptide repeat proteins as sequence-specific RNA-binding proteins for organellar RNAs in plants.Plant Cell Physiol. 2012 Jul;53(7):1171-9. doi: 10.1093/pcp/pcs069. Epub 2012 May 9. Plant Cell Physiol. 2012. PMID: 22576772 Review.
-
[Family of pentatricopeptide repeat proteins].Postepy Biochem. 2005;51(4):440-6. Postepy Biochem. 2005. PMID: 16676579 Review. Polish.
Cited by
-
High throughput approaches to study RNA-protein interactions in vitro.Methods. 2020 Jun 1;178:3-10. doi: 10.1016/j.ymeth.2019.09.006. Epub 2019 Sep 5. Methods. 2020. PMID: 31494245 Free PMC article. Review.
-
In vivo stabilization of endogenous chloroplast RNAs by customized artificial pentatricopeptide repeat proteins.Nucleic Acids Res. 2021 Jun 4;49(10):5985-5997. doi: 10.1093/nar/gkab390. Nucleic Acids Res. 2021. PMID: 34037778 Free PMC article.
-
Maize Dek37 Encodes a P-type PPR Protein That Affects cis-Splicing of Mitochondrial nad2 Intron 1 and Seed Development.Genetics. 2018 Mar;208(3):1069-1082. doi: 10.1534/genetics.117.300602. Epub 2018 Jan 4. Genetics. 2018. PMID: 29301905 Free PMC article.
-
RNA-binding specificity landscapes of designer pentatricopeptide repeat proteins elucidate principles of PPR-RNA interactions.Nucleic Acids Res. 2018 Mar 16;46(5):2613-2623. doi: 10.1093/nar/gkx1288. Nucleic Acids Res. 2018. PMID: 29294070 Free PMC article.
-
Expanding the binding specificity for RNA recognition by a PUF domain.Nat Commun. 2021 Aug 24;12(1):5107. doi: 10.1038/s41467-021-25433-6. Nat Commun. 2021. PMID: 34429425 Free PMC article.
References
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Research Materials