

Predicting human olfactory perception from chemical features of odor molecules
- PMID: 28219971
- PMCID: PMC5455768
- DOI: 10.1126/science.aal2014
Predicting human olfactory perception from chemical features of odor molecules
Abstract
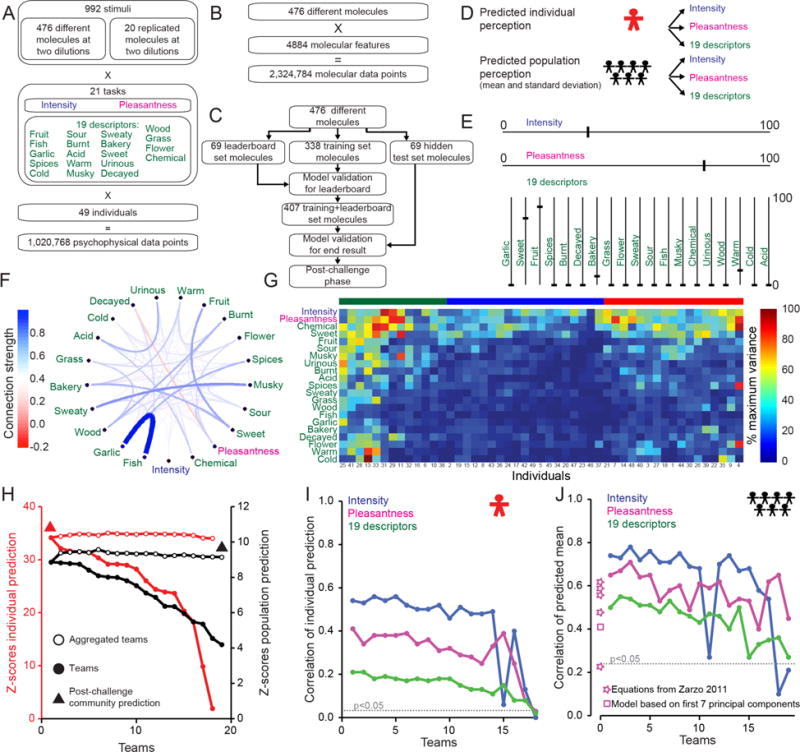
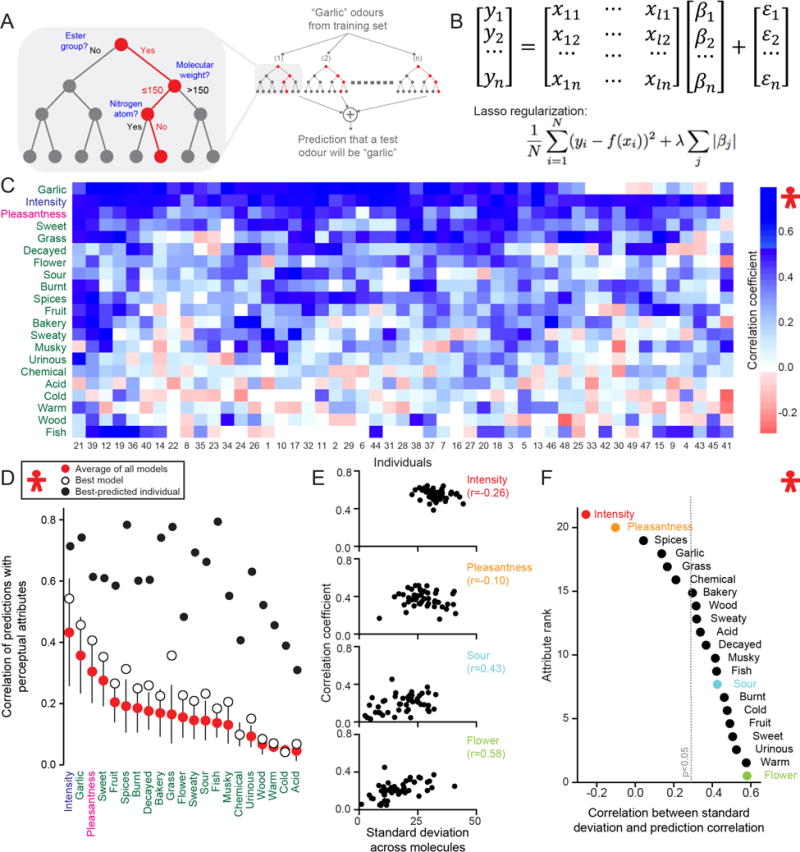
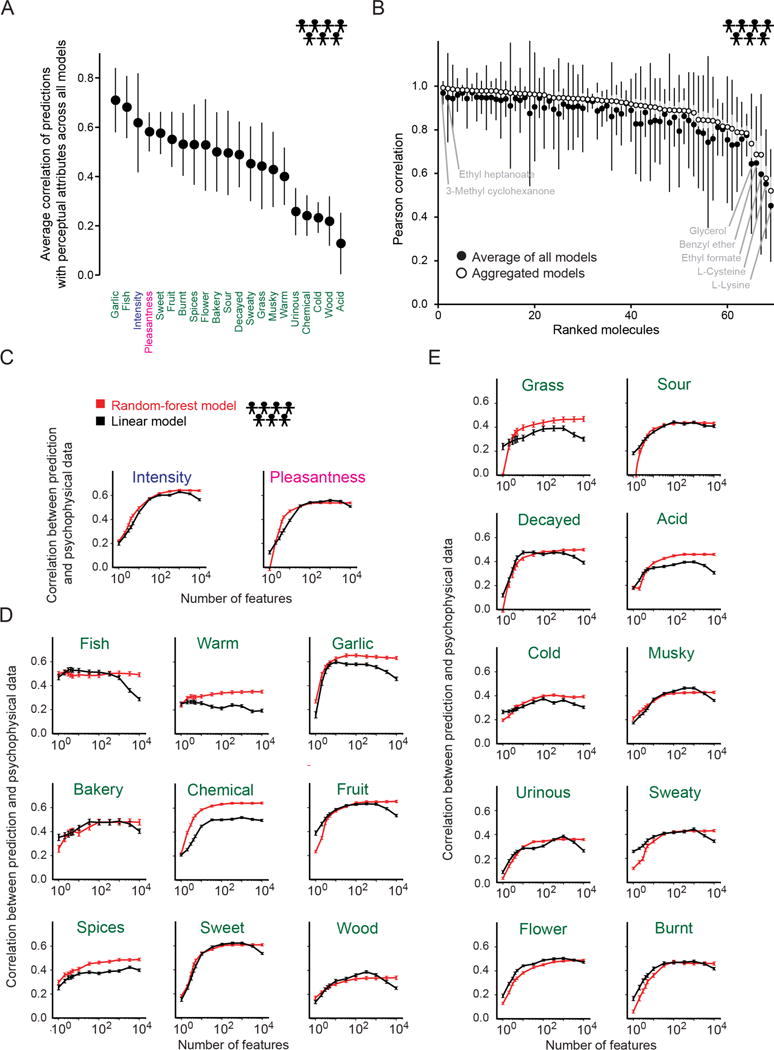
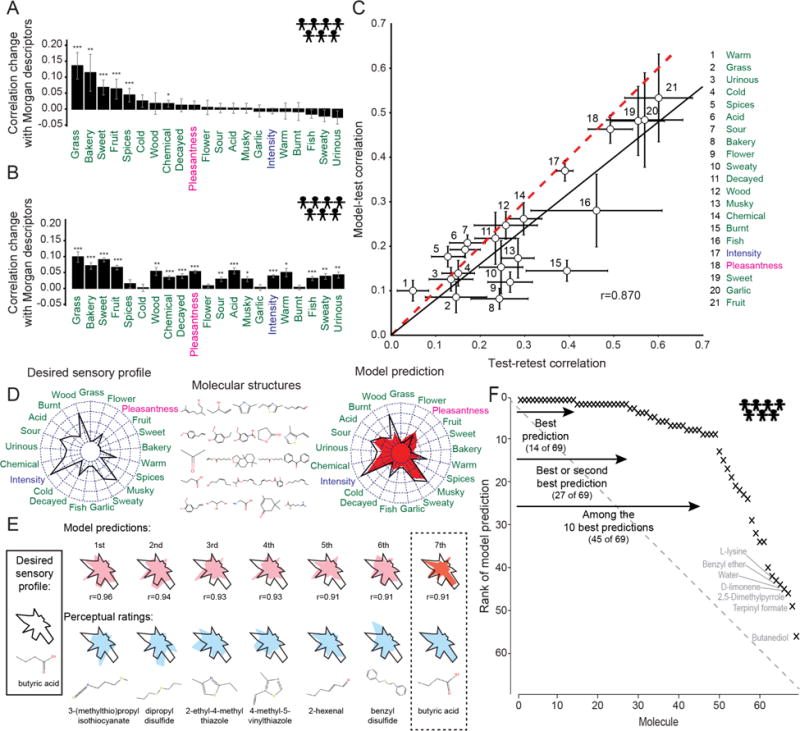
It is still not possible to predict whether a given molecule will have a perceived odor or what olfactory percept it will produce. We therefore organized the crowd-sourced DREAM Olfaction Prediction Challenge. Using a large olfactory psychophysical data set, teams developed machine-learning algorithms to predict sensory attributes of molecules based on their chemoinformatic features. The resulting models accurately predicted odor intensity and pleasantness and also successfully predicted 8 among 19 rated semantic descriptors ("garlic," "fish," "sweet," "fruit," "burnt," "spices," "flower," and "sour"). Regularized linear models performed nearly as well as random forest-based ones, with a predictive accuracy that closely approaches a key theoretical limit. These models help to predict the perceptual qualities of virtually any molecule with high accuracy and also reverse-engineer the smell of a molecule.
Copyright © 2017, American Association for the Advancement of Science.
Figures
References
-
- Boelens H. Structure-activity relationships in chemoreception by human olfaction. Trends Pharmacol Sci. 1983;4:421–426.
-
- Sell C. Structure-odor relationships: On the unpredictability of odor. Angew Chem Int Edit. 2006;45:6254–6261. - PubMed
-
- Laska M, Teubner P. Olfactory discrimination ability for homologous series of aliphatic alcohols and aldehydes. Chem Senses. 1999;24:263–270. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
