

GreekLex 2: A comprehensive lexical database with part-of-speech, syllabic, phonological, and stress information
- PMID: 28231303
- PMCID: PMC5322960
- DOI: 10.1371/journal.pone.0172493
GreekLex 2: A comprehensive lexical database with part-of-speech, syllabic, phonological, and stress information
Abstract
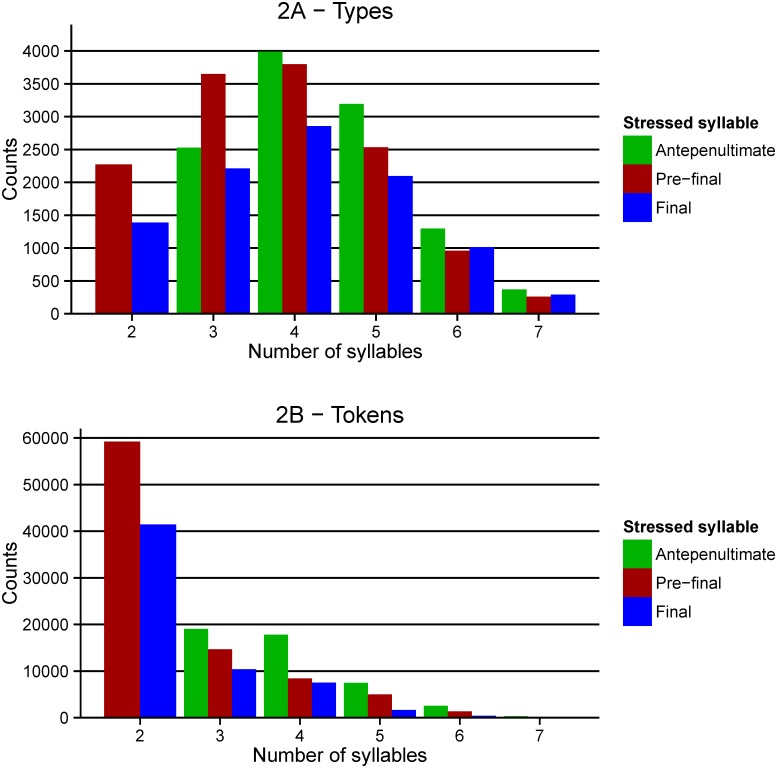
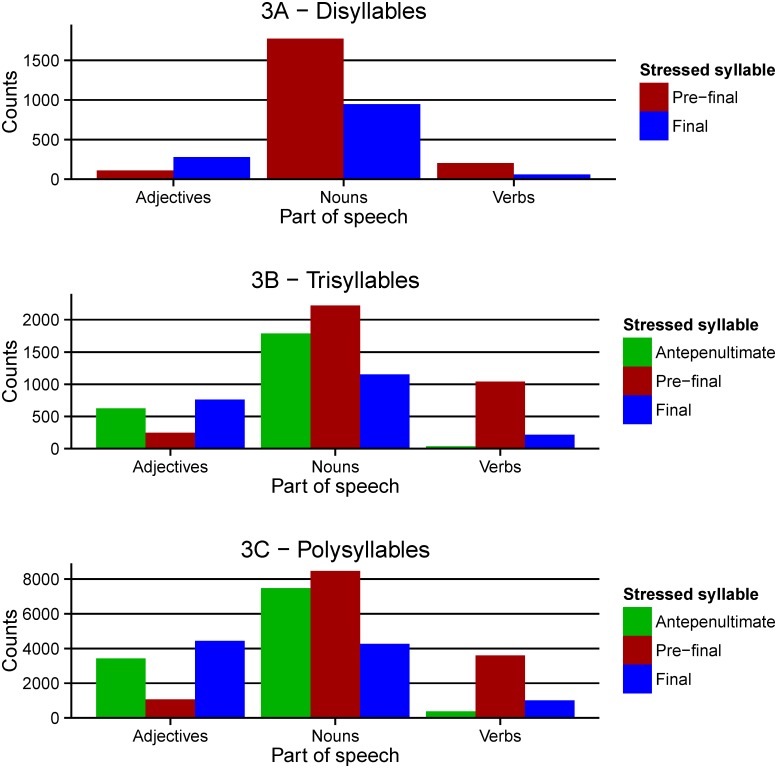
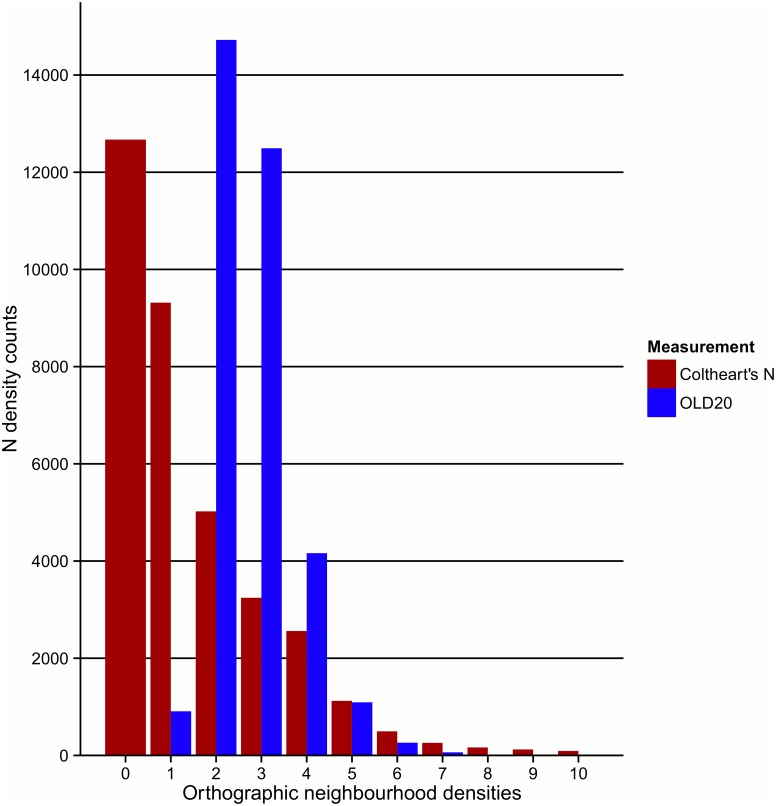
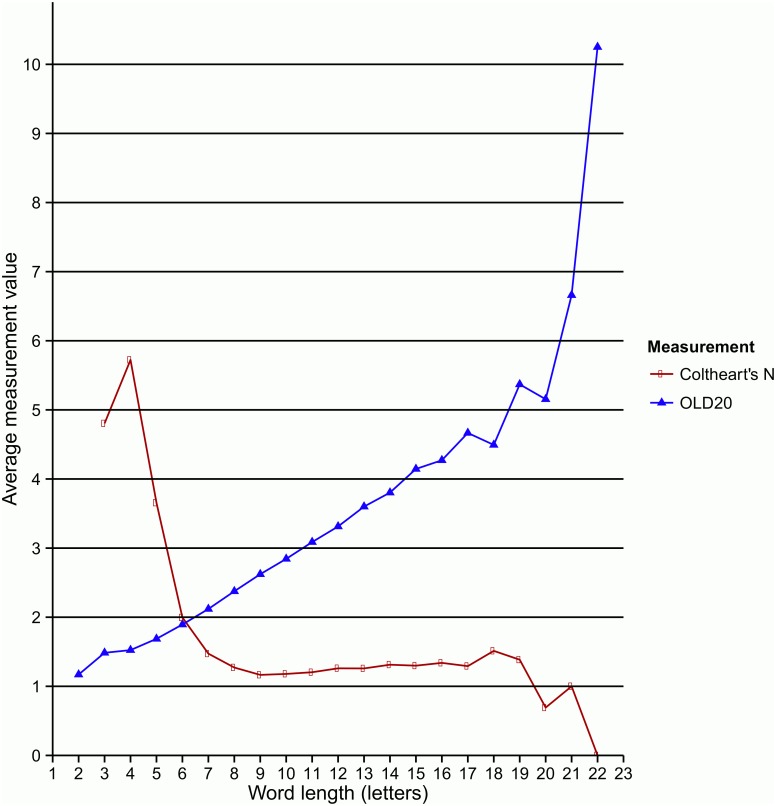
Databases containing lexical properties on any given orthography are crucial for psycholinguistic research. In the last ten years, a number of lexical databases have been developed for Greek. However, these lack important part-of-speech information. Furthermore, the need for alternative procedures for calculating syllabic measurements and stress information, as well as combination of several metrics to investigate linguistic properties of the Greek language are highlighted. To address these issues, we present a new extensive lexical database of Modern Greek (GreekLex 2) with part-of-speech information for each word and accurate syllabification and orthographic information predictive of stress, as well as several measurements of word similarity and phonetic information. The addition of detailed statistical information about Greek part-of-speech, syllabification, and stress neighbourhood allowed novel analyses of stress distribution within different grammatical categories and syllabic lengths to be carried out. Results showed that the statistical preponderance of stress position on the pre-final syllable that is reported for Greek language is dependent upon grammatical category. Additionally, analyses showed that a proportion higher than 90% of the tokens in the database would be stressed correctly solely by relying on stress neighbourhood information. The database and the scripts for orthographic and phonological syllabification as well as phonetic transcription are available at http://www.psychology.nottingham.ac.uk/greeklex/.
Conflict of interest statement
Figures

Similar articles
-
GreekLex: a lexical database of Modern Greek.Behav Res Methods. 2008 Aug;40(3):773-83. doi: 10.3758/brm.40.3.773. Behav Res Methods. 2008. PMID: 18697673
-
Procura-PALavras (P-PAL): A Web-based interface for a new European Portuguese lexical database.Behav Res Methods. 2018 Aug;50(4):1461-1481. doi: 10.3758/s13428-018-1058-z. Behav Res Methods. 2018. PMID: 29855811
-
Test-retest reliability of independent measures of phonology in the assessment of toddlers' speech.Lang Speech Hear Serv Sch. 2009 Jan;40(1):46-52. doi: 10.1044/0161-1461(2008/07-0082). Epub 2008 Oct 7. Lang Speech Hear Serv Sch. 2009. PMID: 18840673
-
Using network science in the language sciences and clinic.Int J Speech Lang Pathol. 2015 Feb;17(1):13-25. doi: 10.3109/17549507.2014.987819. Epub 2014 Dec 24. Int J Speech Lang Pathol. 2015. PMID: 25539473 Free PMC article. Review.
-
[Speech therapy intervention in phonological disorders from the psycholinguistic paradigm of speech processing].Rev Neurol. 2003 Feb;36 Suppl 1:S39-53. Rev Neurol. 2003. PMID: 12599102 Review. Spanish.
Cited by
-
Chipola: A Chinese Podcast Lexical Database for capturing spoken language nuances and predicting behavioral data.Behav Res Methods. 2025 May 8;57(6):166. doi: 10.3758/s13428-025-02697-0. Behav Res Methods. 2025. PMID: 40341999
-
Shabd: A psycholinguistic database for Hindi.Behav Res Methods. 2022 Apr;54(2):830-844. doi: 10.3758/s13428-021-01625-2. Epub 2021 Aug 6. Behav Res Methods. 2022. PMID: 34357542
-
HelexKids: A word frequency database for Greek and Cypriot primary school children.Behav Res Methods. 2017 Feb;49(1):83-96. doi: 10.3758/s13428-015-0698-5. Behav Res Methods. 2017. PMID: 26822666 Free PMC article.
-
Syllables and their beginnings have a special role in the mental lexicon.Proc Natl Acad Sci U S A. 2023 Sep 5;120(36):e2215710120. doi: 10.1073/pnas.2215710120. Epub 2023 Aug 28. Proc Natl Acad Sci U S A. 2023. PMID: 37639606 Free PMC article.
-
Universal linguistic hierarchies are not innately wired. Evidence from multiple adjectives.PeerJ. 2019 Aug 1;7:e7438. doi: 10.7717/peerj.7438. eCollection 2019. PeerJ. 2019. PMID: 31396461 Free PMC article.
References
-
- Ktori M, van Heuven WJB, Pitchford NJ. GreekLex: a lexical database of Modern Greek. Behav Res Methods. 2008; 40(3): 773–783. - PubMed
-
- Protopapas A, Tzakosta M, Chalamandaris A, Tsiakoulis P. IPLR: An online resource for Greek word-level and sublexical information. Lang Resour Eval. 2012; 46(3): 449–459.
-
- Gimenes M, New B. Worldlex: Twitter and blog word frequencies for 66 languages. Behav Res Methods. 2015; 48(3): 963–72. - PubMed
-
- Hatzigeorgiu N, Gavrilidou M, Piperdis S, Carayannis G, Papakostopoulou A, Spiliotopoulou A, et al. Design and implementation of the online ILSP Greek Corpus. Paper presented at LREC 2000—the Second International Conference on Language Resources and Evaluation, Athens, Greece; 2000. Retrieved from http://www.lrec-conf.org/proceedings/lrec2000/pdf/336.pdf
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
