

Dopamine reward prediction errors reflect hidden-state inference across time
- PMID: 28263301
- PMCID: PMC5374025
- DOI: 10.1038/nn.4520
Dopamine reward prediction errors reflect hidden-state inference across time
Abstract
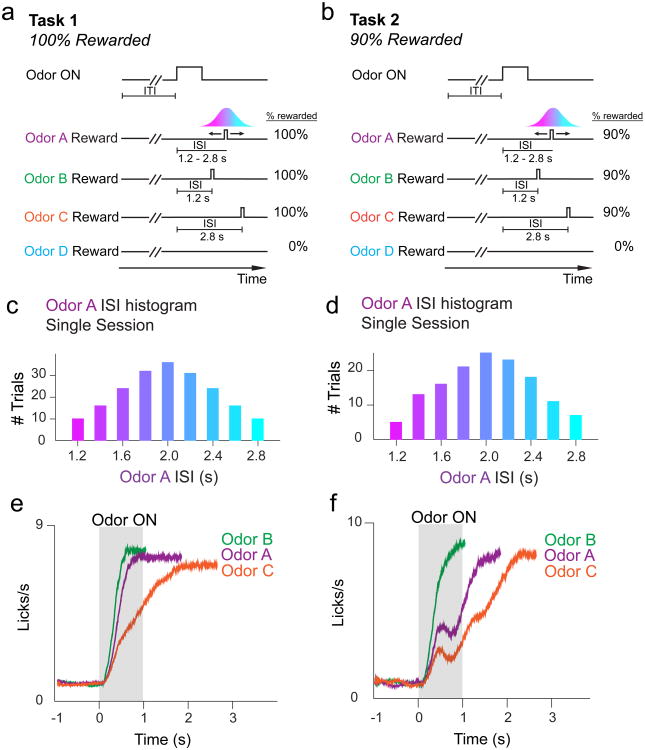
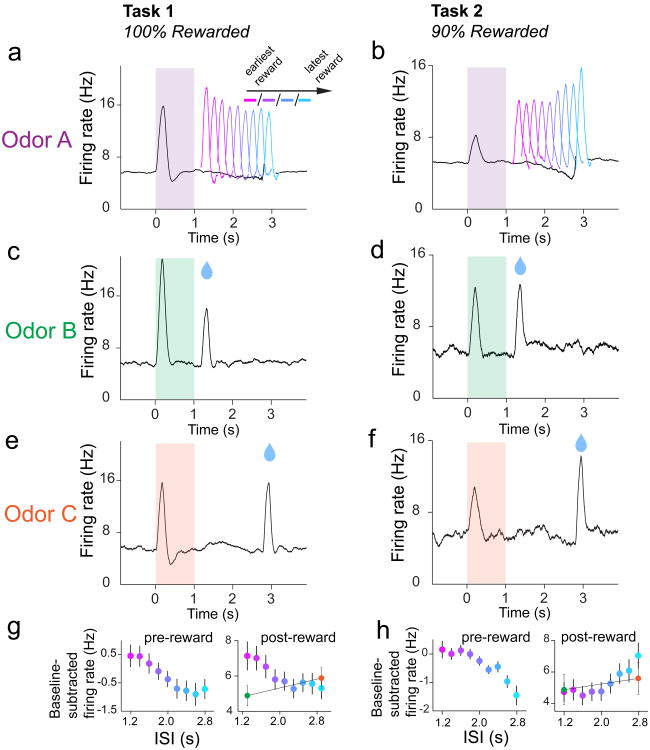
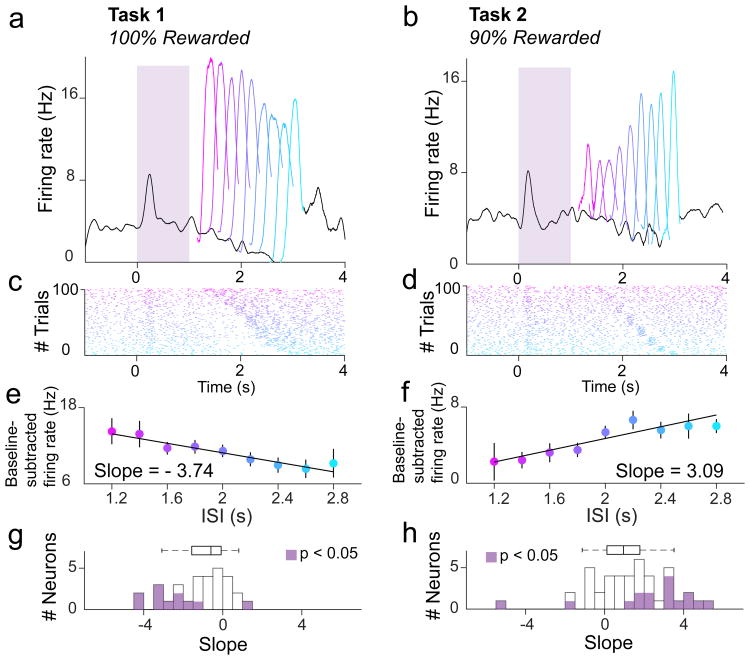
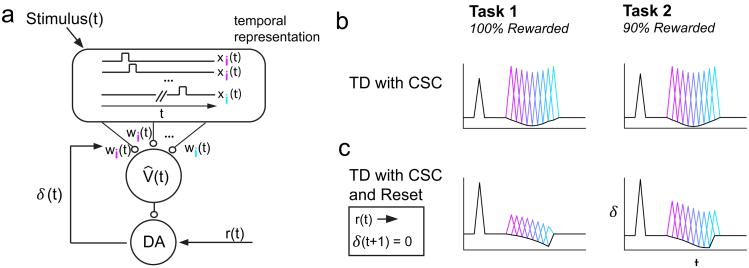
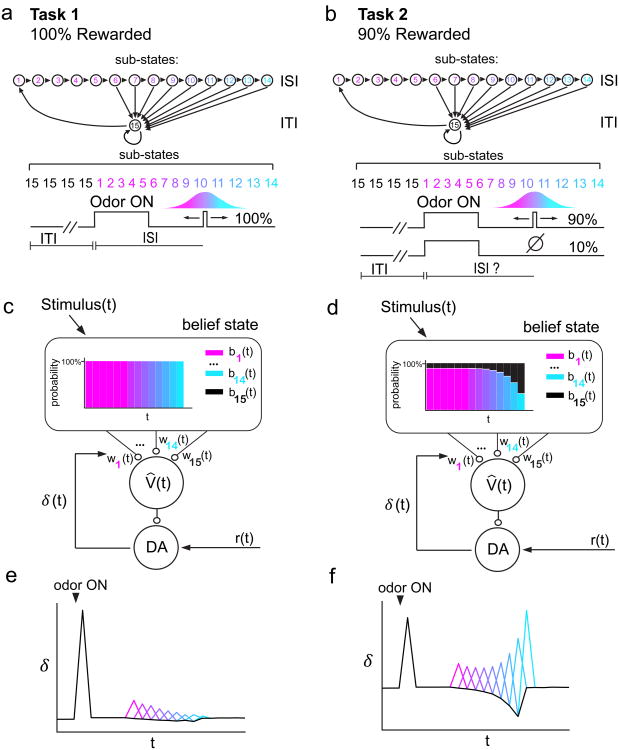
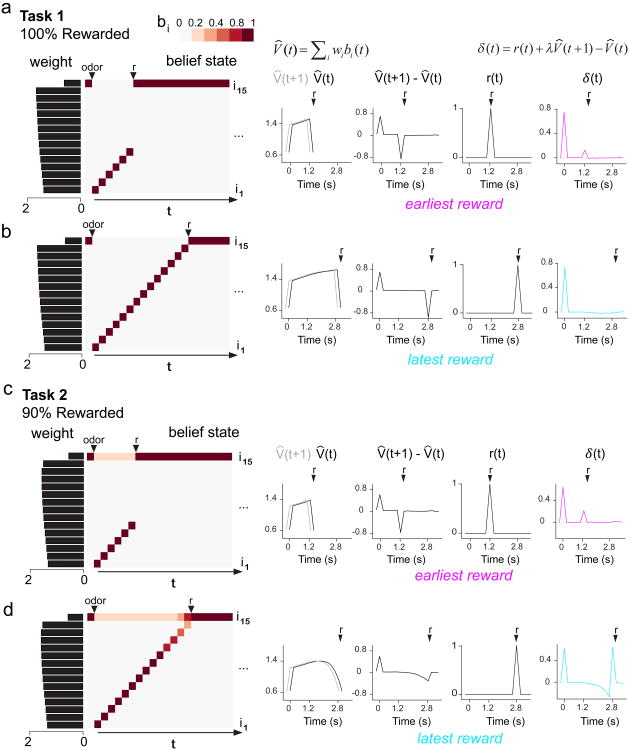
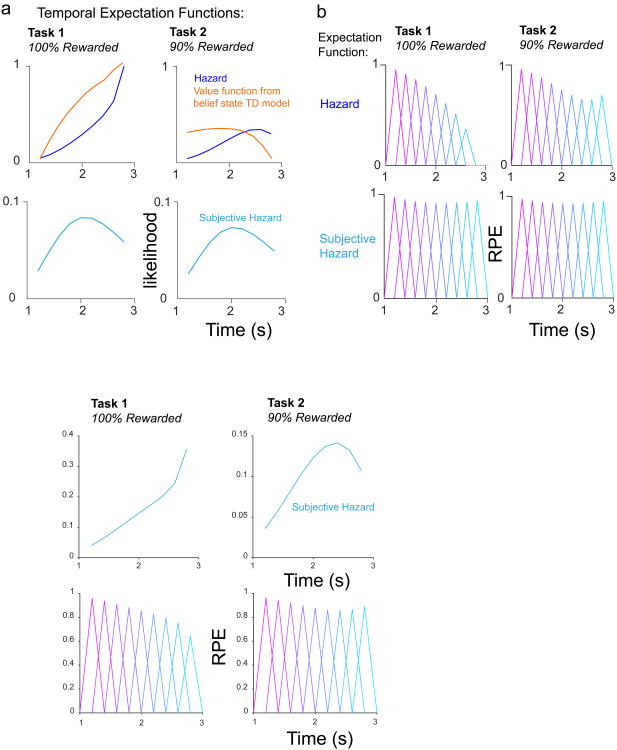
Midbrain dopamine neurons signal reward prediction error (RPE), or actual minus expected reward. The temporal difference (TD) learning model has been a cornerstone in understanding how dopamine RPEs could drive associative learning. Classically, TD learning imparts value to features that serially track elapsed time relative to observable stimuli. In the real world, however, sensory stimuli provide ambiguous information about the hidden state of the environment, leading to the proposal that TD learning might instead compute a value signal based on an inferred distribution of hidden states (a 'belief state'). Here we asked whether dopaminergic signaling supports a TD learning framework that operates over hidden states. We found that dopamine signaling showed a notable difference between two tasks that differed only with respect to whether reward was delivered in a deterministic manner. Our results favor an associative learning rule that combines cached values with hidden-state inference.
Figures
References
References for Main Text
-
- Schultz W, Dayan P, Montague PR. A neural substrate of prediction and reward. Science. 1997;275:1593–1599. - PubMed
-
- Sutton RS, Barto AG. Time-Derivative Models of Pavlovian Reinforcement. In: Gabriel M, Moore J, editors. Learning and Computational Neuroscience: Foundations of Adaptive Networks. Cambridge, MA: MIT Press; pp. 497–537.
Methods-Only References
-
- Backman C, et al. Characterization of a Mouse Strain Expressing Cre Recombinase From the 30 Untranslated Region of the Dopamine Transporter Locus. Genesis. 2007;45:418–426. - PubMed
-
- Uchida N, Mainen ZF. Speed and accuracy of olfactory discrimination in the rat. Nat Neurosci. 2003;6:1224–1229. - PubMed
-
- Schmitzer-Torbert N, Jackson J, Henze D, Harris K, Redish AD. Quantitative measures of cluster quality for use in extracellular recordings. Neuroscience. 2005;131:1–11. - PubMed
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
