

Doctor AI: Predicting Clinical Events via Recurrent Neural Networks
- PMID: 28286600
- PMCID: PMC5341604
Doctor AI: Predicting Clinical Events via Recurrent Neural Networks
Abstract
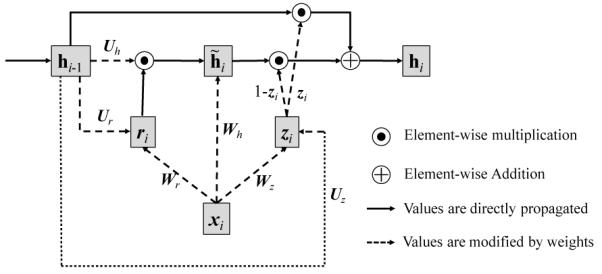
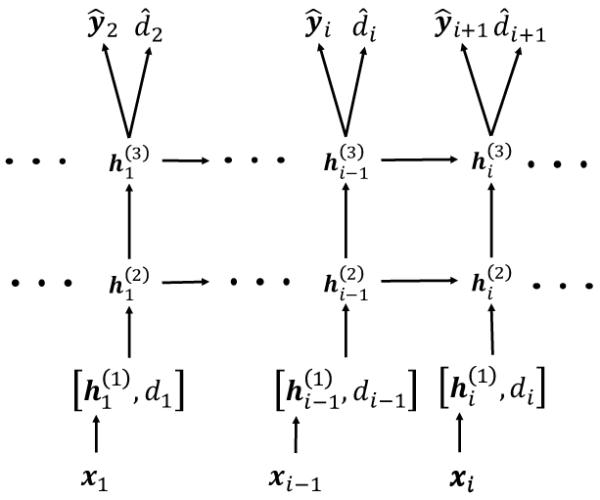
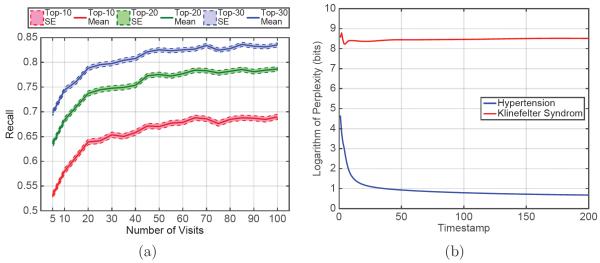
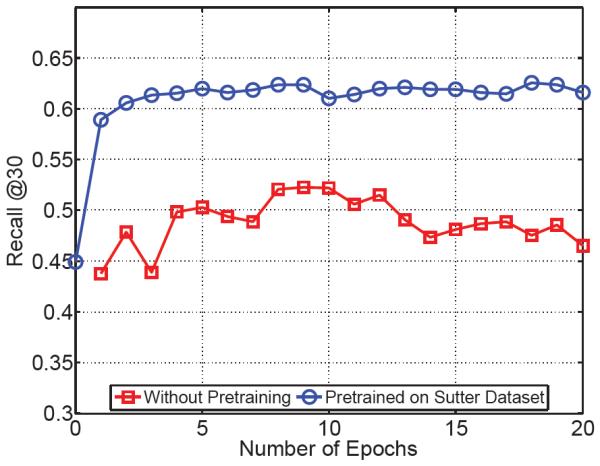
Leveraging large historical data in electronic health record (EHR), we developed Doctor AI, a generic predictive model that covers observed medical conditions and medication uses. Doctor AI is a temporal model using recurrent neural networks (RNN) and was developed and applied to longitudinal time stamped EHR data from 260K patients over 8 years. Encounter records (e.g. diagnosis codes, medication codes or procedure codes) were input to RNN to predict (all) the diagnosis and medication categories for a subsequent visit. Doctor AI assesses the history of patients to make multilabel predictions (one label for each diagnosis or medication category). Based on separate blind test set evaluation, Doctor AI can perform differential diagnosis with up to 79% recall@30, significantly higher than several baselines. Moreover, we demonstrate great generalizability of Doctor AI by adapting the resulting models from one institution to another without losing substantial accuracy.
Figures
References
-
- Bahadori Mohammad Taha, Liu Yan, Xing Eric P. Fast structure learning in generalized stochastic processes with latent factors. KDD. 2013:284–292.
-
- Bastien Frédéric, Lamblin Pascal, Pascanu Razvan, Bergstra James, Goodfellow Ian J., Bergeron Arnaud, Bouchard Nicolas, Bengio Yoshua. Theano: new features and speed improvements. Deep Learning and Unsupervised Feature Learning NIPS 2012 Workshop. 2012
-
- Bengio Yoshua. Deep learning of representations for unsupervised and transfer learning. Unsupervised and Transfer Learning Challenges in Machine Learning. 2012;7:19.
-
- Bengio Yoshua, Courville Aaron, Vincent Pierre. Representation learning: A review and new perspectives. Pattern Analysis and Machine Intelligence, IEEE Transactions on. 2013;35(8):1798–1828. - PubMed
-
- Che Zhengping, Kale David, Li Wenzhe, Bahadori Mohammad Taha, Liu Yan. Deep computational phenotyping. Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining; ACM; 2015. pp. 507–516.
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical