

Working Memory Load Strengthens Reward Prediction Errors
- PMID: 28320846
- PMCID: PMC5413179
- DOI: 10.1523/JNEUROSCI.2700-16.2017
Working Memory Load Strengthens Reward Prediction Errors
Abstract
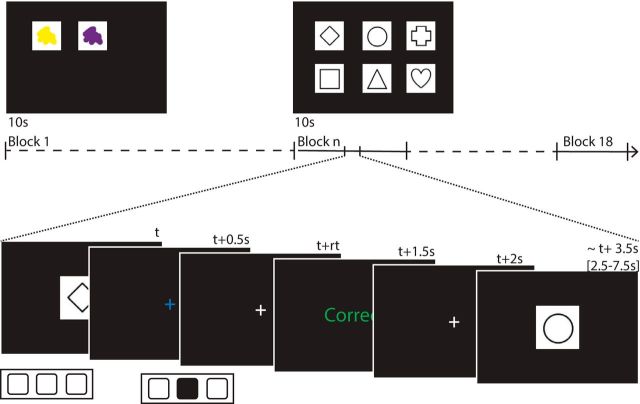
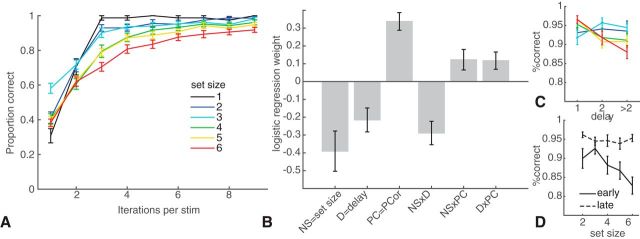
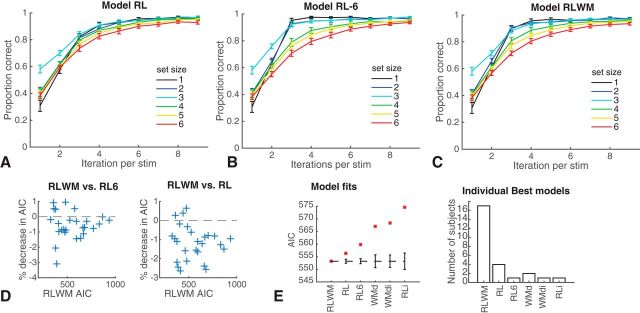
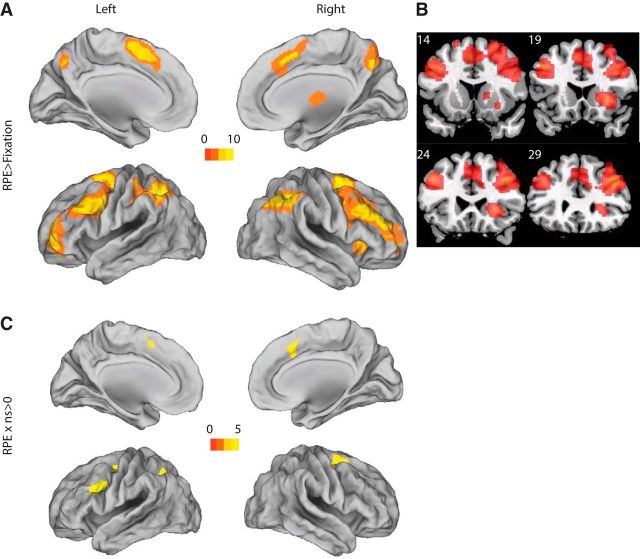
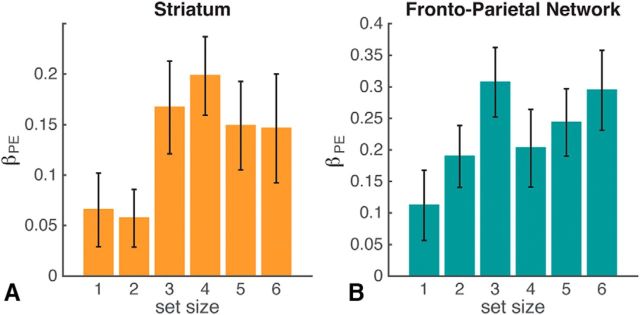
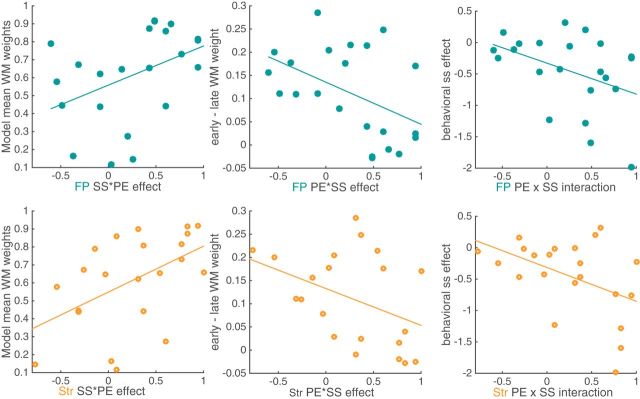
Reinforcement learning (RL) in simple instrumental tasks is usually modeled as a monolithic process in which reward prediction errors (RPEs) are used to update expected values of choice options. This modeling ignores the different contributions of different memory and decision-making systems thought to contribute even to simple learning. In an fMRI experiment, we investigated how working memory (WM) and incremental RL processes interact to guide human learning. WM load was manipulated by varying the number of stimuli to be learned across blocks. Behavioral results and computational modeling confirmed that learning was best explained as a mixture of two mechanisms: a fast, capacity-limited, and delay-sensitive WM process together with slower RL. Model-based analysis of fMRI data showed that striatum and lateral prefrontal cortex were sensitive to RPE, as shown previously, but, critically, these signals were reduced when the learning problem was within capacity of WM. The degree of this neural interaction related to individual differences in the use of WM to guide behavioral learning. These results indicate that the two systems do not process information independently, but rather interact during learning.SIGNIFICANCE STATEMENT Reinforcement learning (RL) theory has been remarkably productive at improving our understanding of instrumental learning as well as dopaminergic and striatal network function across many mammalian species. However, this neural network is only one contributor to human learning and other mechanisms such as prefrontal cortex working memory also play a key role. Our results also show that these other players interact with the dopaminergic RL system, interfering with its key computation of reward prediction errors.
Keywords: fMRI; reinforcement learning; reward prediction error; working memory.
Copyright © 2017 the authors 0270-6474/17/374332-11$15.00/0.
Figures
References
-
- Badre D, D'Esposito M (2007) Functional magnetic resonance imaging evidence for a hierarchical organization of the prefrontal cortex. J Cogn Neurosci 19:2082–2099. - PubMed
-
- Burnham KP, Anderson DR (2002) Model selection and multi-model inference: a practical information-theoretic approach. New York: Springer.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources