

DeepDive: Declarative Knowledge Base Construction
- PMID: 28344371
- PMCID: PMC5361060
DeepDive: Declarative Knowledge Base Construction
Abstract
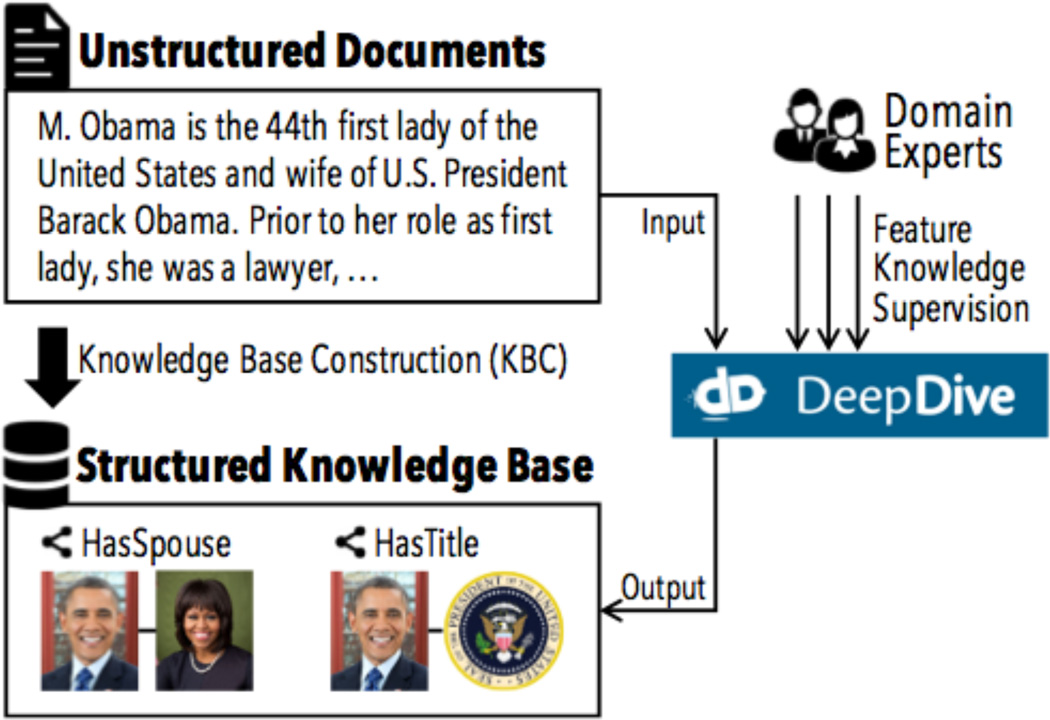
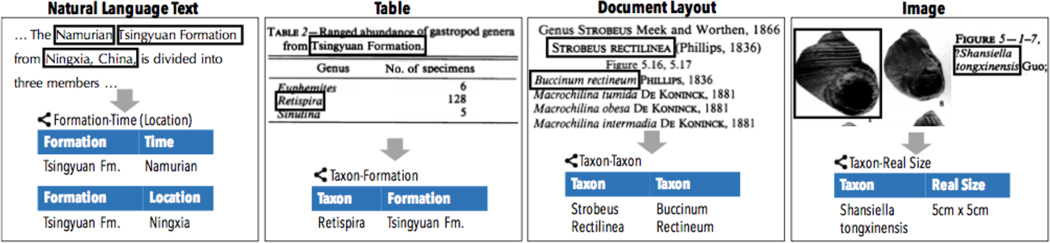
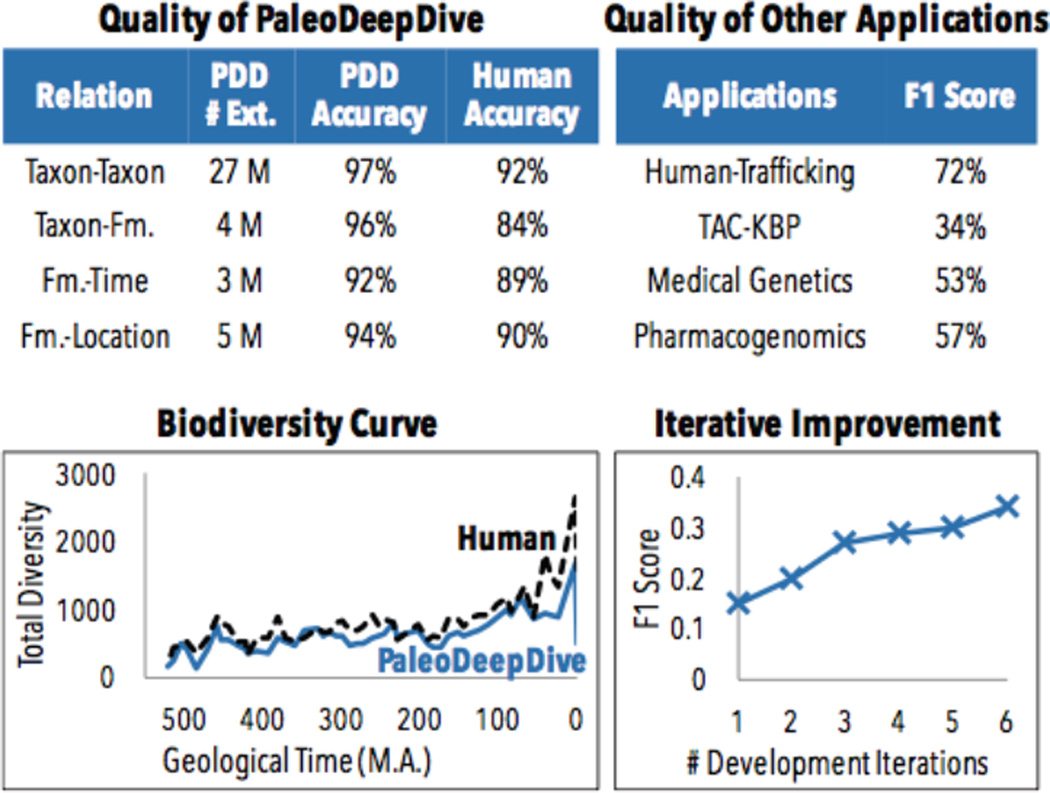
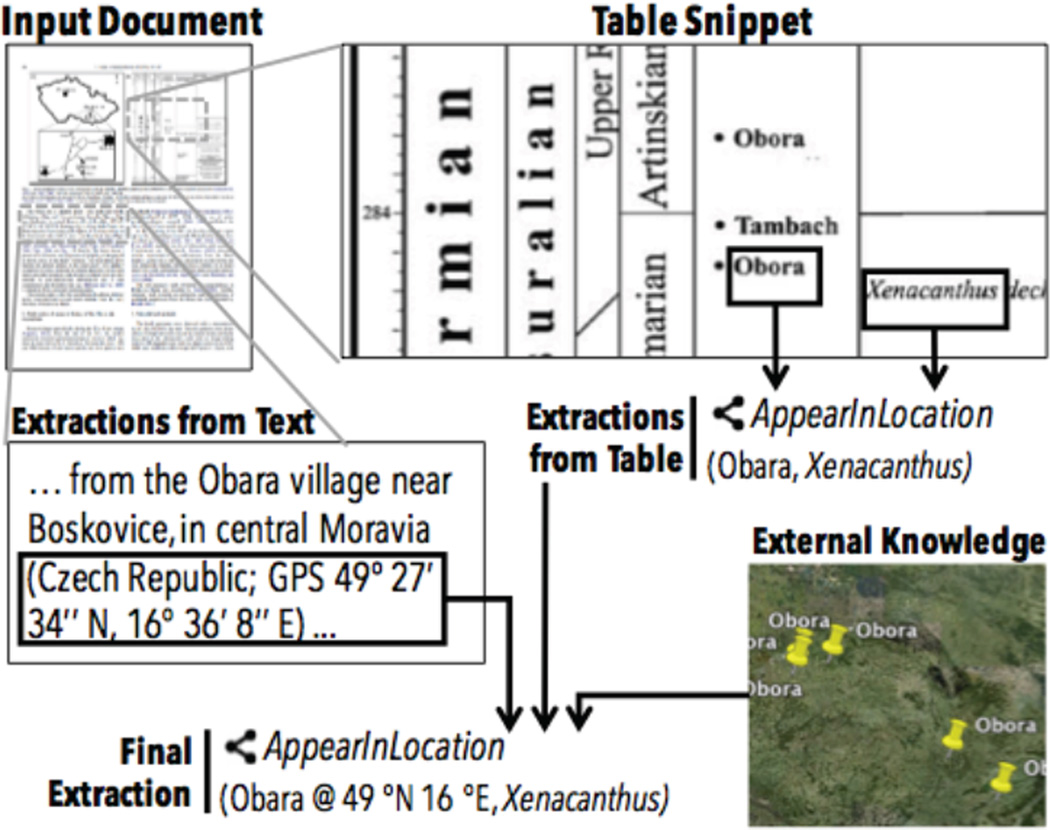
The dark data extraction or knowledge base construction (KBC) problem is to populate a SQL database with information from unstructured data sources including emails, webpages, and pdf reports. KBC is a long-standing problem in industry and research that encompasses problems of data extraction, cleaning, and integration. We describe DeepDive, a system that combines database and machine learning ideas to help develop KBC systems. The key idea in DeepDive is that statistical inference and machine learning are key tools to attack classical data problems in extraction, cleaning, and integration in a unified and more effective manner. DeepDive programs are declarative in that one cannot write probabilistic inference algorithms; instead, one interacts by defining features or rules about the domain. A key reason for this design choice is to enable domain experts to build their own KBC systems. We present the applications, abstractions, and techniques of DeepDive employed to accelerate construction of KBC systems.
Figures
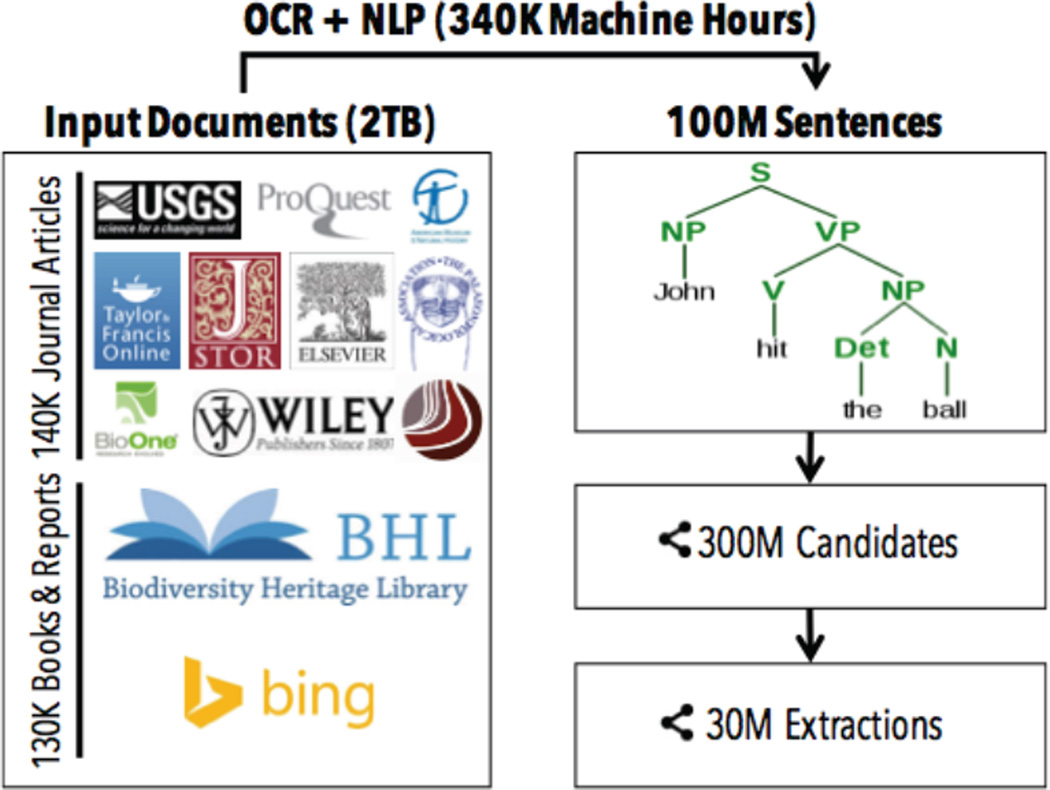
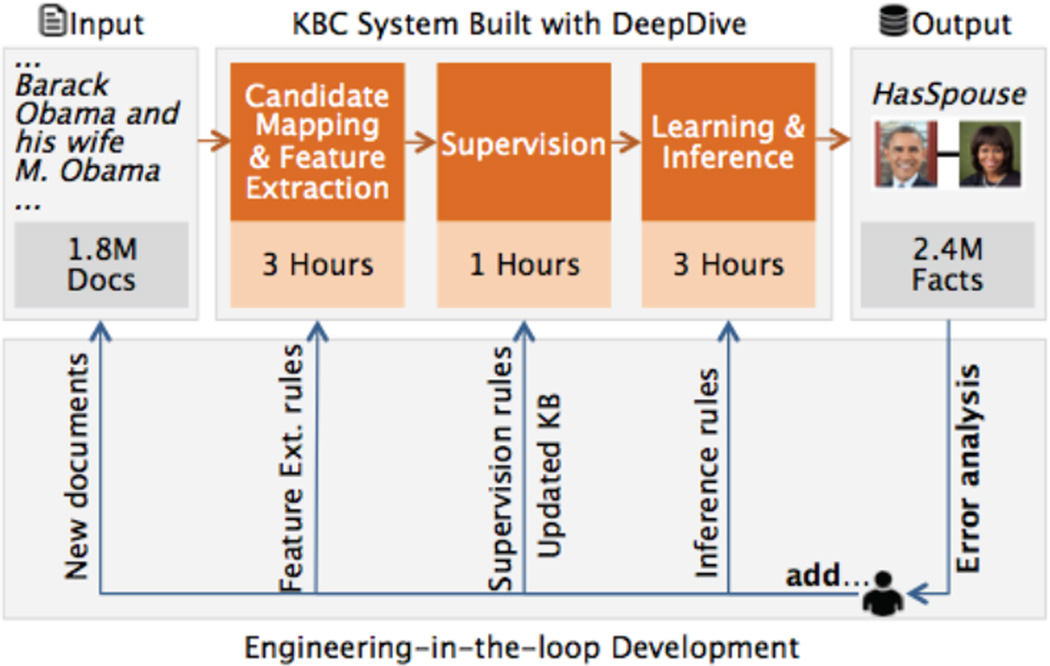
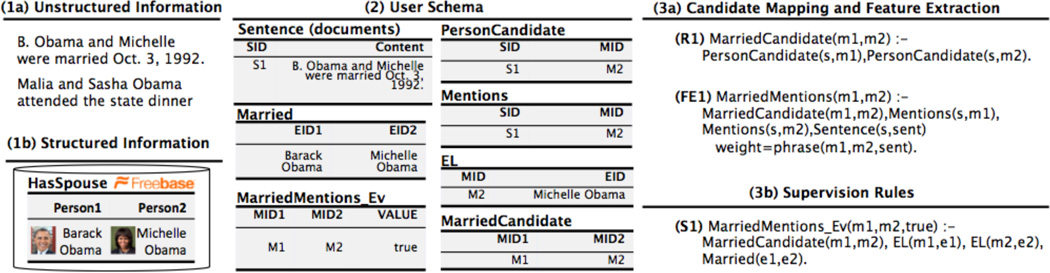

References
-
- Angeli G, et al. Stanford’s 2014 slot filling systems. TAC KBP. 2014
-
- Banko M, et al. Open information extraction from the Web. IJCAI. 2007
-
- Betteridge J, Carlson A, Hong SA, Hruschka ER, Jr, Law EL, Mitchell TM, Wang SH. Toward never ending language learning. AAAI Spring Symposium. 2009
-
- Brin S. Extracting patterns and relations from the world wide web. WebDB. 1999
-
- Brown E, et al. Tools and methods for building watson. IBM Research Report. 2013
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources