

A dataset of stereoscopic images and ground-truth disparity mimicking human fixations in peripersonal space
- PMID: 28350382
- PMCID: PMC5369322
- DOI: 10.1038/sdata.2017.34
A dataset of stereoscopic images and ground-truth disparity mimicking human fixations in peripersonal space
Abstract
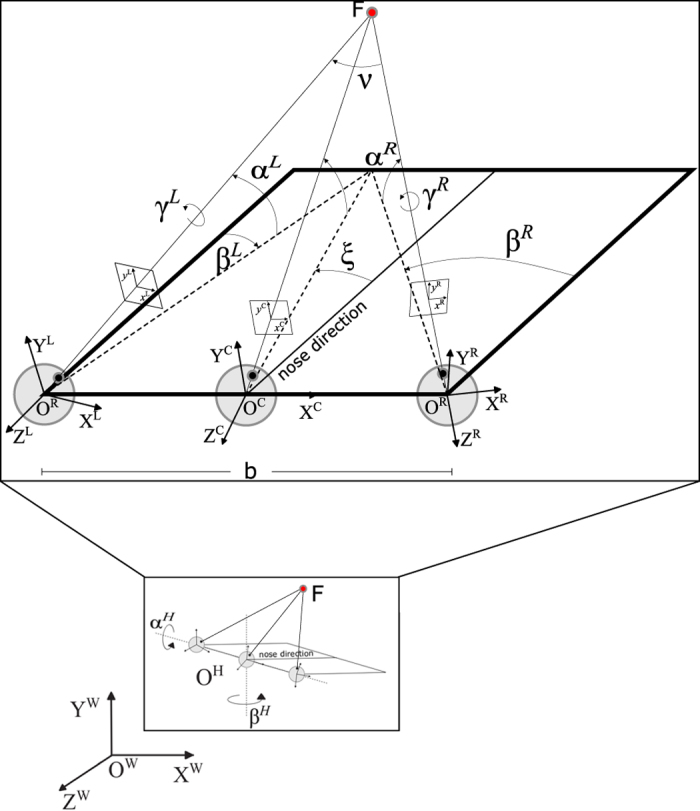
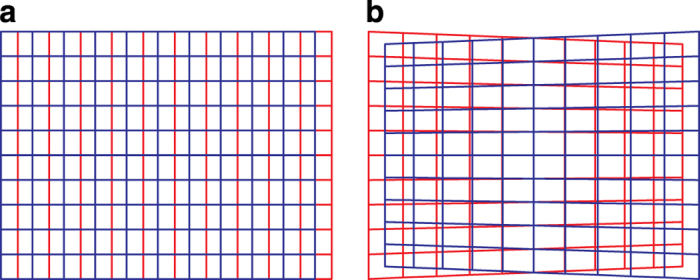
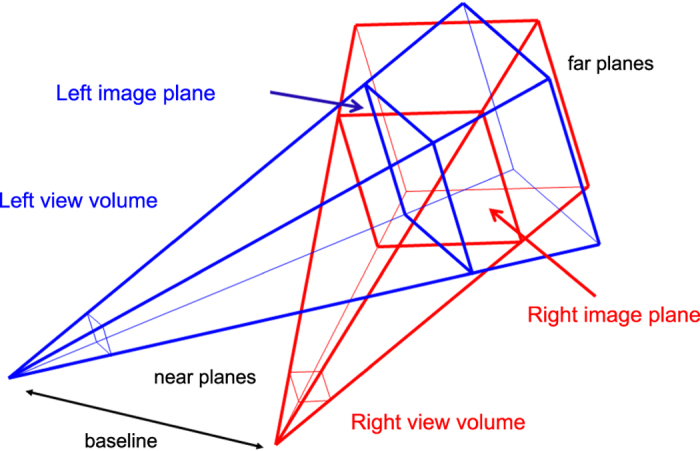
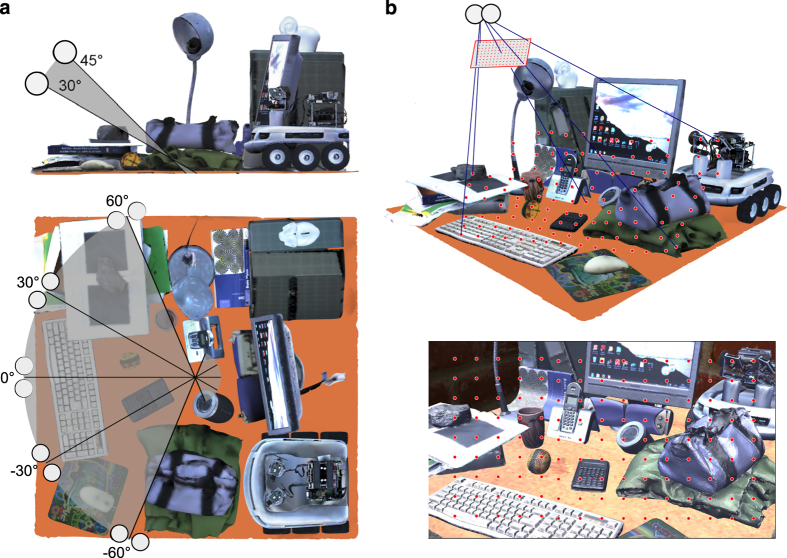
Binocular stereopsis is the ability of a visual system, belonging to a live being or a machine, to interpret the different visual information deriving from two eyes/cameras for depth perception. From this perspective, the ground-truth information about three-dimensional visual space, which is hardly available, is an ideal tool both for evaluating human performance and for benchmarking machine vision algorithms. In the present work, we implemented a rendering methodology in which the camera pose mimics realistic eye pose for a fixating observer, thus including convergent eye geometry and cyclotorsion. The virtual environment we developed relies on highly accurate 3D virtual models, and its full controllability allows us to obtain the stereoscopic pairs together with the ground-truth depth and camera pose information. We thus created a stereoscopic dataset: GENUA PESTO-GENoa hUman Active fixation database: PEripersonal space STereoscopic images and grOund truth disparity. The dataset aims to provide a unified framework useful for a number of problems relevant to human and computer vision, from scene exploration and eye movement studies to 3D scene reconstruction.
Conflict of interest statement
The authors declare no competing financial interests.
Figures


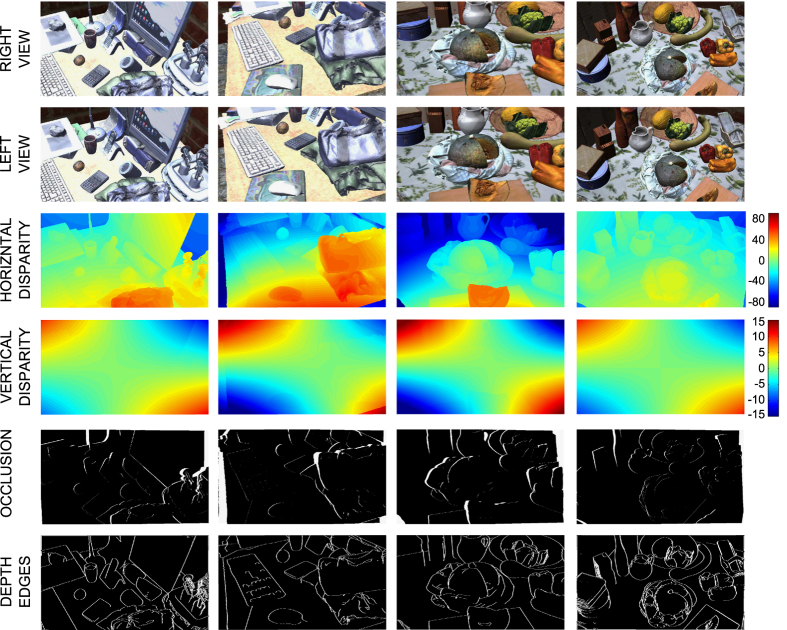
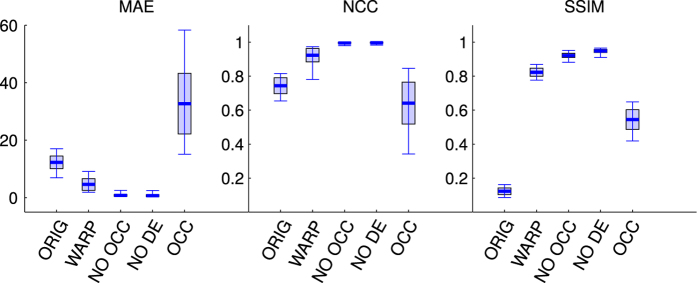
Comment in
-
The Active Side of Stereopsis: Fixation Strategy and Adaptation to Natural Environments.Sci Rep. 2017 Mar 20;7:44800. doi: 10.1038/srep44800. Sci Rep. 2017. PMID: 28317909 Free PMC article.
References
Data Citations
-
- Canessa A. 2016. Dryad Digital Repository . http://dx.doi.org/10.5061/dryad.6t8vq - DOI
References
-
- Mian A. S., Bennamoun M. & Owens R. Three-dimensional model-based object recognition and segmentation in cluttered scenes. IEEE Transactions on Pattern Analysis and Machine Intelligence 28, 1584–1601 (2006). - PubMed
-
- Browatzki B., Fischer J., Graf B., Bülthoff H. H. & Wallraven C. Going into depth: Evaluating 2d and 3d cues for object classification on a new, large-scale object dataset. In Computer Vision Workshops (ICCV Workshops), 2011 IEEE International Conference on, pages 1189–1195 (IEEE, 2011).
-
- Anand A., Koppula H. S., Joachims T. & Saxena A. Contextually guided semantic labeling and search for three-dimensional point clouds. The International Journal of Robotics Research, 32, 19–34 (2012).
-
- Koppula H. S., Anand A., Joachims T. & Saxena A. Semantic labeling of 3d point clouds for indoor scenes. In Advances in Neural Information Processing Systems, pages 244–252 (2011).
-
- Su C., Bovik A. C. & Cormack L. K. Natural scene statistics of color and rangeIn 2011 18th IEEE International Conference on Image Processing, pages 257–260 (IEEE, 2011).
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
