

Multiagent cooperation and competition with deep reinforcement learning
- PMID: 28380078
- PMCID: PMC5381785
- DOI: 10.1371/journal.pone.0172395
Multiagent cooperation and competition with deep reinforcement learning
Abstract
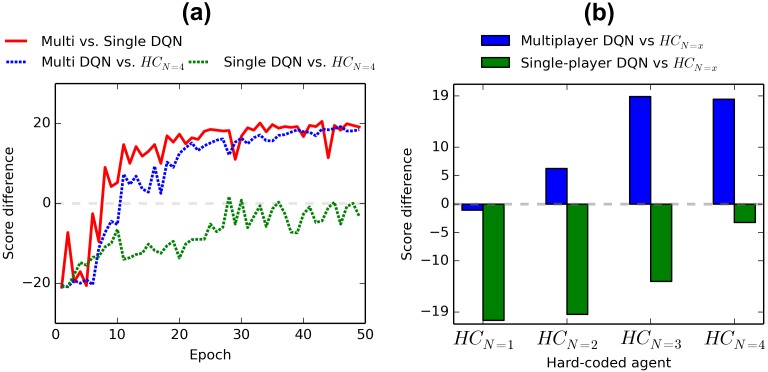
Evolution of cooperation and competition can appear when multiple adaptive agents share a biological, social, or technological niche. In the present work we study how cooperation and competition emerge between autonomous agents that learn by reinforcement while using only their raw visual input as the state representation. In particular, we extend the Deep Q-Learning framework to multiagent environments to investigate the interaction between two learning agents in the well-known video game Pong. By manipulating the classical rewarding scheme of Pong we show how competitive and collaborative behaviors emerge. We also describe the progression from competitive to collaborative behavior when the incentive to cooperate is increased. Finally we show how learning by playing against another adaptive agent, instead of against a hard-wired algorithm, results in more robust strategies. The present work shows that Deep Q-Networks can become a useful tool for studying decentralized learning of multiagent systems coping with high-dimensional environments.
Conflict of interest statement
Figures
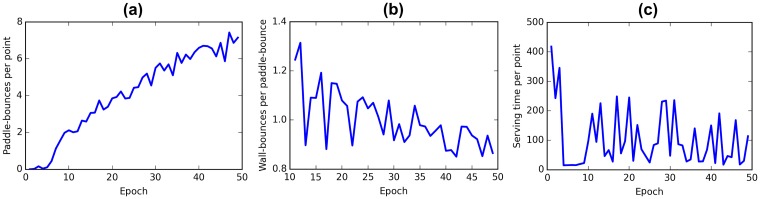
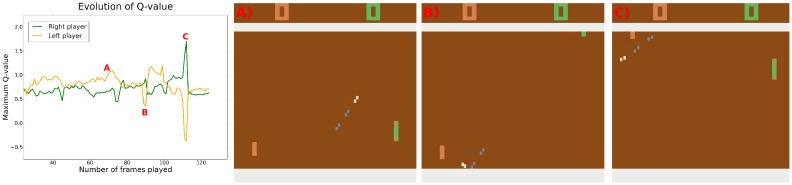
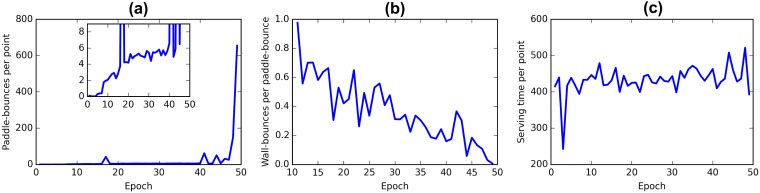

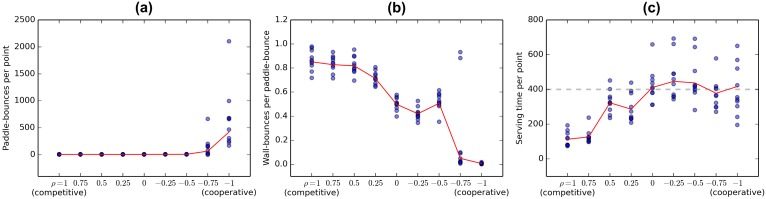
References
-
- Sutton RS, Barto AG. Reinforcement learning: An introduction. MIT press; Cambridge; 1998.
-
- Poole DL, Mackworth AK. Artificial Intelligence: foundations of computational agents. Cambridge University Press; 2010.
-
- Busoniu L, Babuska R, De Schutter B. A comprehensive survey of multiagent reinforcement learning. Systems, Man, and Cybernetics, Part C: Applications and Reviews, IEEE Transactions on. 2008;38(2):156–172. 10.1109/TSMCC.2007.913919 - DOI
-
- Sumpter DJ. Collective animal behavior. Princeton University Press; 2010.
-
- Schwartz HM. Multi-Agent Machine Learning: A Reinforcement Approach. John Wiley & Sons; 2014.
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
