

GSA: Genome Sequence Archive<sup/>
- PMID: 28387199
- PMCID: PMC5339404
- DOI: 10.1016/j.gpb.2017.01.001
GSA: Genome Sequence Archive<sup/>
Abstract
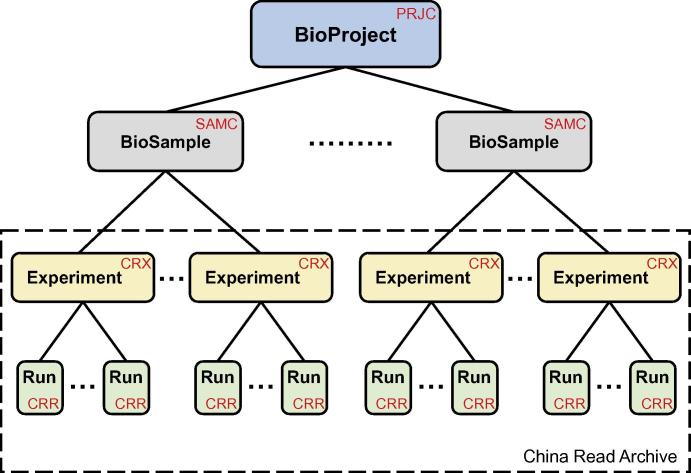
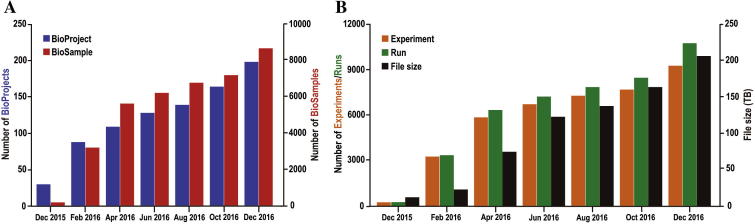
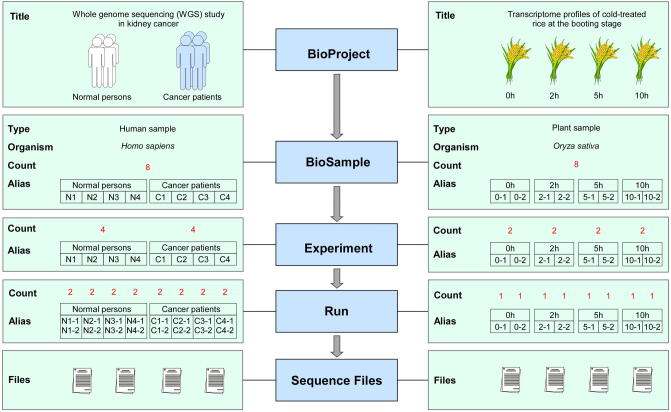
With the rapid development of sequencing technologies towards higher throughput and lower cost, sequence data are generated at an unprecedentedly explosive rate. To provide an efficient and easy-to-use platform for managing huge sequence data, here we present Genome Sequence Archive (GSA; http://bigd.big.ac.cn/gsa or http://gsa.big.ac.cn), a data repository for archiving raw sequence data. In compliance with data standards and structures of the International Nucleotide Sequence Database Collaboration (INSDC), GSA adopts four data objects (BioProject, BioSample, Experiment, and Run) for data organization, accepts raw sequence reads produced by a variety of sequencing platforms, stores both sequence reads and metadata submitted from all over the world, and makes all these data publicly available to worldwide scientific communities. In the era of big data, GSA is not only an important complement to existing INSDC members by alleviating the increasing burdens of handling sequence data deluge, but also takes the significant responsibility for global big data archive and provides free unrestricted access to all publicly available data in support of research activities throughout the world.
Keywords: Big data; GSA; Genome Sequence Archive; INSDC; Raw sequence data.
Copyright © 2017. Production and hosting by Elsevier Ltd.
Figures
References
-
- Gudbjartsson D.F., Helgason H., Gudjonsson S.A., Zink F., Oddson A., Gylfason A. Large-scale whole-genome sequencing of the Icelandic population. Nat Genet. 2015;47:435–444. - PubMed
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
