

Conducting Privacy-Preserving Multivariable Propensity Score Analysis When Patient Covariate Information Is Stored in Separate Locations
- PMID: 28399565
- PMCID: PMC5391702
- DOI: 10.1093/aje/kww155
Conducting Privacy-Preserving Multivariable Propensity Score Analysis When Patient Covariate Information Is Stored in Separate Locations
Abstract
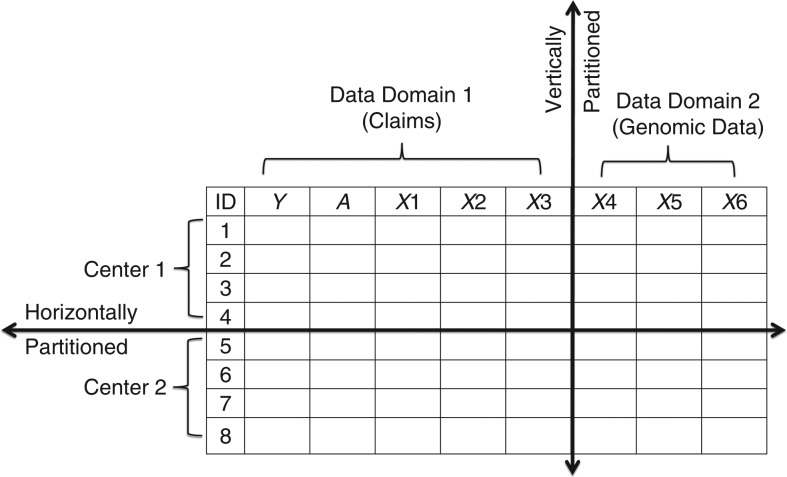
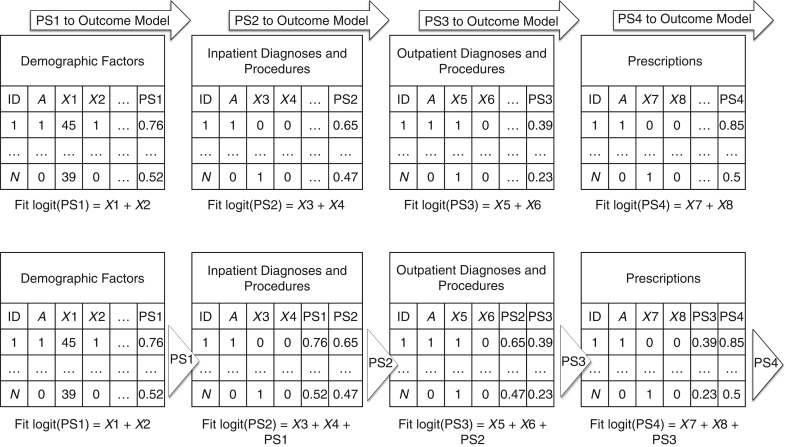
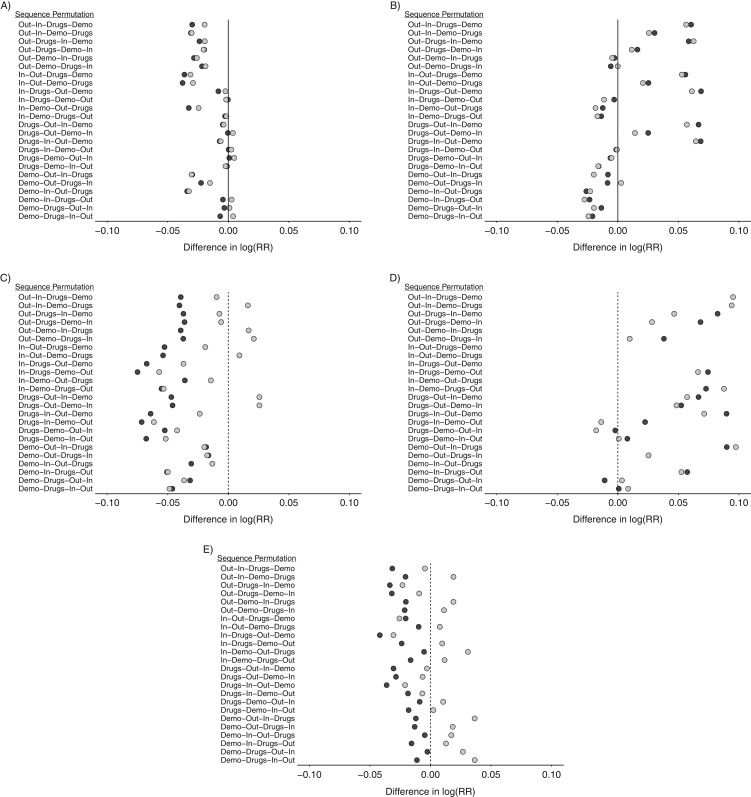
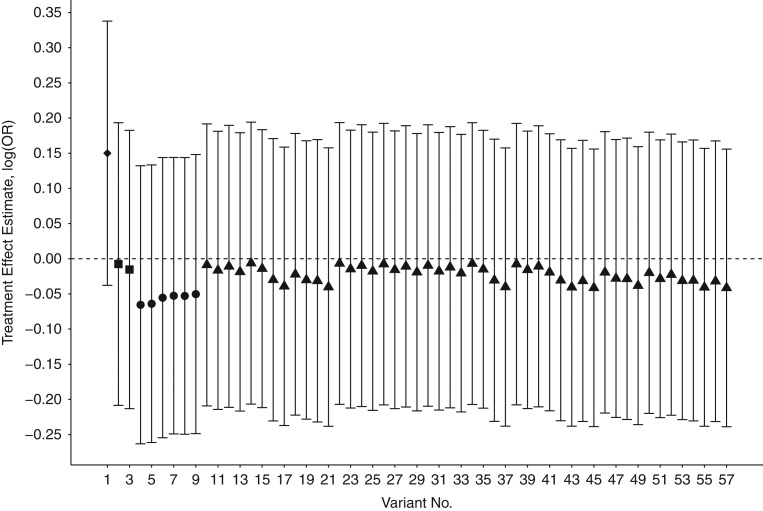
Distributed networks of health-care data sources are increasingly being utilized to conduct pharmacoepidemiologic database studies. Such networks may contain data that are not physically pooled but instead are distributed horizontally (separate patients within each data source) or vertically (separate measures within each data source) in order to preserve patient privacy. While multivariable methods for the analysis of horizontally distributed data are frequently employed, few practical approaches have been put forth to deal with vertically distributed health-care databases. In this paper, we propose 2 propensity score-based approaches to vertically distributed data analysis and test their performance using 5 example studies. We found that these approaches produced point estimates close to what could be achieved without partitioning. We further found a performance benefit (i.e., lower mean squared error) for sequentially passing a propensity score through each data domain (called the "sequential approach") as compared with fitting separate domain-specific propensity scores (called the "parallel approach"). These results were validated in a small simulation study. This proof-of-concept study suggests a new multivariable analysis approach to vertically distributed health-care databases that is practical, preserves patient privacy, and warrants further investigation for use in clinical research applications that rely on health-care databases.
Keywords: database linkage; database studies; databases; epidemiologic methods; pharmacoepidemiology; propensity scores.
© The Author 2017. Published by Oxford University Press on behalf of the Johns Hopkins Bloomberg School of Public Health. All rights reserved. For permissions, please e-mail: journals.permissions@oup.com.
Figures
References
-
- Platt R, Carnahan RM, Brown JS, et al. The US Food and Drug Administration's Mini-Sentinel program: status and direction. Pharmacoepidemiol Drug Saf. 2012;21(suppl 1):1–8. - PubMed
-
- Califf RM. The Patient-Centered Outcomes Research Network: a national infrastructure for comparative effectiveness research. NC Med J. 2014;75(3):204–210. - PubMed
-
- Oliveira JL, Lopes P, Nunes T, et al. The EU-ADR Web Platform: delivering advanced pharmacovigilance tools. Pharmacoepidemiol Drug Saf. 2013;22(5):459–467. - PubMed
-
- Trifirò G, Coloma PM, Rijnbeek PR, et al. Combining multiple healthcare databases for postmarketing drug and vaccine safety surveillance: why and how. J Intern Med. 2014;275(6):551–561. - PubMed
-
- Curtis LH, Weiner MG, Boudreau DM, et al. Design considerations, architecture, and use of the Mini-Sentinel distributed data system. Pharmacoepidemiol Drug Saf. 2012;21(suppl 1):23–31. - PubMed
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
