

Hearing Scenes: A Neuromagnetic Signature of Auditory Source and Reverberant Space Separation
- PMID: 28451630
- PMCID: PMC5394928
- DOI: 10.1523/ENEURO.0007-17.2017
Hearing Scenes: A Neuromagnetic Signature of Auditory Source and Reverberant Space Separation
Abstract
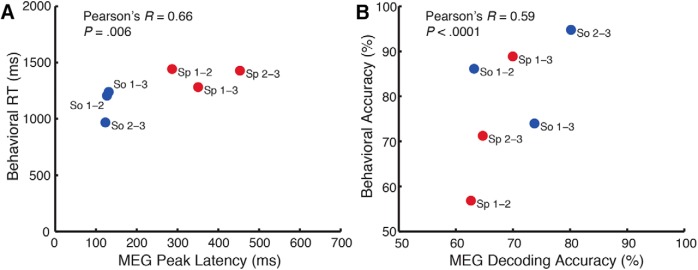
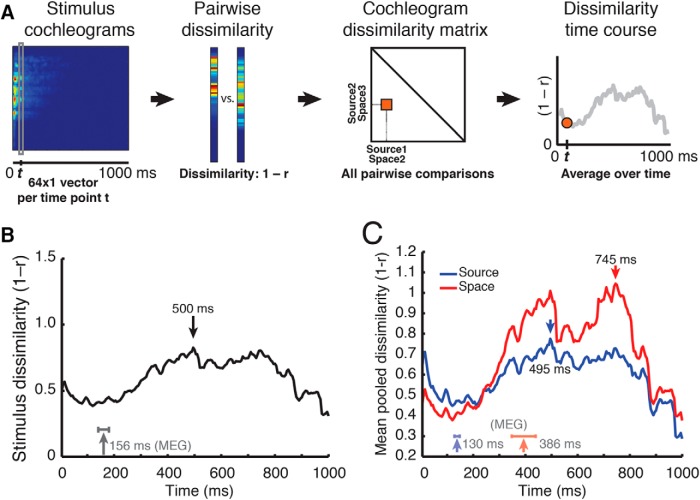
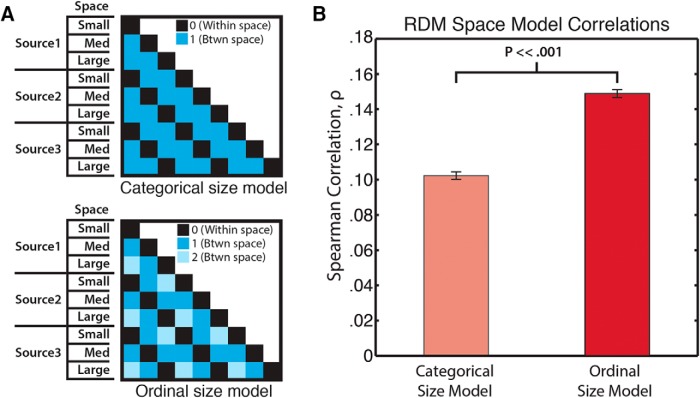
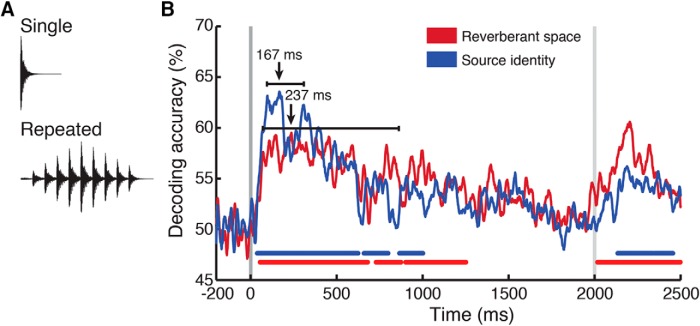
Perceiving the geometry of surrounding space is a multisensory process, crucial to contextualizing object perception and guiding navigation behavior. Humans can make judgments about surrounding spaces from reverberation cues, caused by sounds reflecting off multiple interior surfaces. However, it remains unclear how the brain represents reverberant spaces separately from sound sources. Here, we report separable neural signatures of auditory space and source perception during magnetoencephalography (MEG) recording as subjects listened to brief sounds convolved with monaural room impulse responses (RIRs). The decoding signature of sound sources began at 57 ms after stimulus onset and peaked at 130 ms, while space decoding started at 138 ms and peaked at 386 ms. Importantly, these neuromagnetic responses were readily dissociable in form and time: while sound source decoding exhibited an early and transient response, the neural signature of space was sustained and independent of the original source that produced it. The reverberant space response was robust to variations in sound source, and vice versa, indicating a generalized response not tied to specific source-space combinations. These results provide the first neuromagnetic evidence for robust, dissociable auditory source and reverberant space representations in the human brain and reveal the temporal dynamics of how auditory scene analysis extracts percepts from complex naturalistic auditory signals.
Keywords: audition; auditory scene analysis; magnetoencephalography; multivariate pattern analysis; reverberation.
Figures
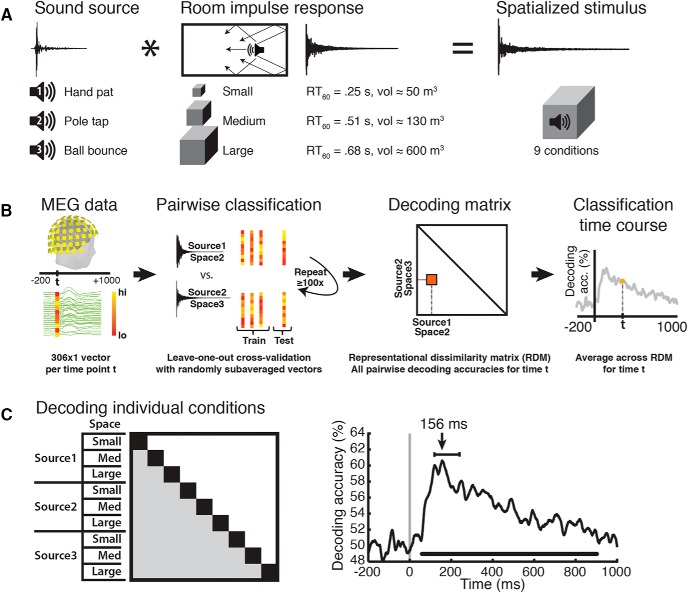
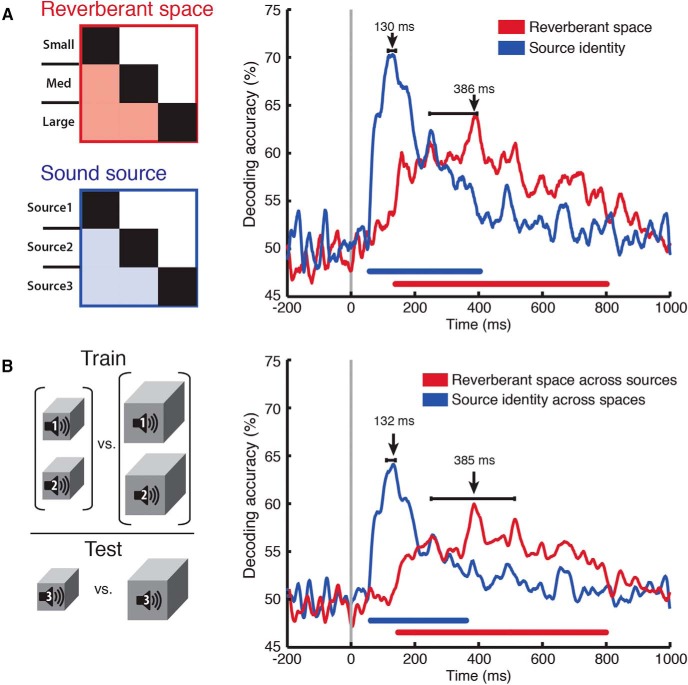
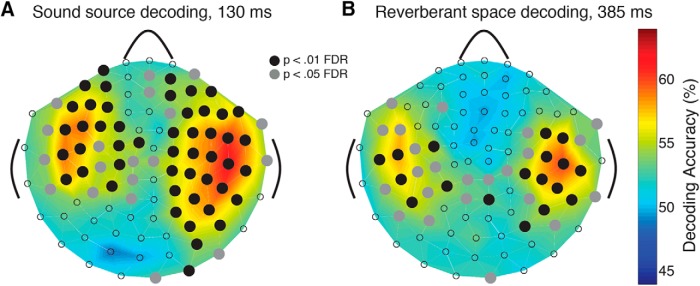
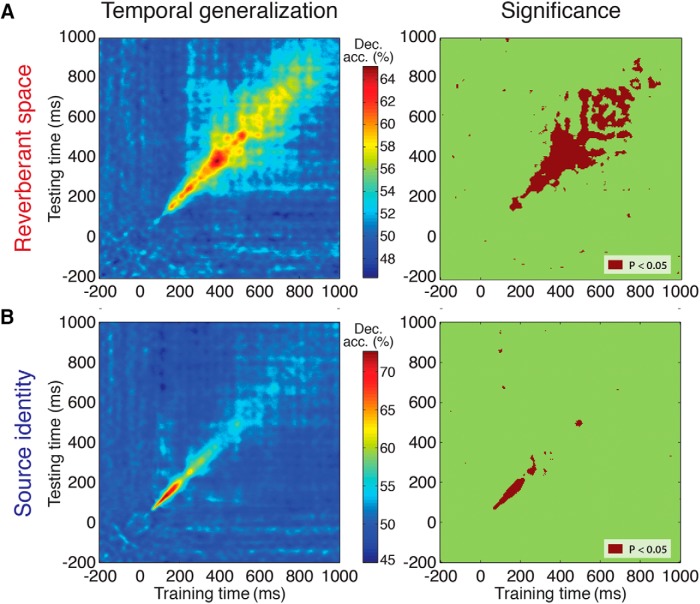
References
-
- Ahveninen J, Jääskeläinen IP, Raij T, Bonmassar G, Devore S, Hämäläinen M, Levänen S, Lin F-H, Sams M, Shinn-Cunningham BG, Witzel T, Belliveau JW (2006) Task-modulated "what" and "where" pathways in human auditory cortex. Proc Natl Acad Sci USA 103:14608–14613. 10.1073/pnas.0510480103 - DOI - PMC - PubMed
-
- Berkley DA, Allen JB (1993) Normal listening in typical rooms: the physical and psychophysical correlates of reverberation In: Acoustical factors affecting hearing aid performance (Studebaker GA, Hockberg I, eds), pp 3–14. Boston: Allyn and Bacon.
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources