

Inter-labeler and intra-labeler variability of condition severity classification models using active and passive learning methods
- PMID: 28456512
- PMCID: PMC5937023
- DOI: 10.1016/j.artmed.2017.03.003
Inter-labeler and intra-labeler variability of condition severity classification models using active and passive learning methods
Abstract
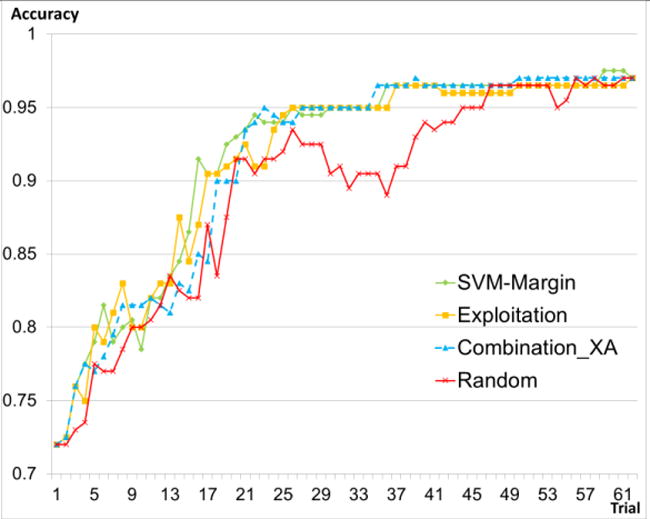
Background and objectives: Labeling instances by domain experts for classification is often time consuming and expensive. To reduce such labeling efforts, we had proposed the application of active learning (AL) methods, introduced our CAESAR-ALE framework for classifying the severity of clinical conditions, and shown its significant reduction of labeling efforts. The use of any of three AL methods (one well known [SVM-Margin], and two that we introduced [Exploitation and Combination_XA]) significantly reduced (by 48% to 64%) condition labeling efforts, compared to standard passive (random instance-selection) SVM learning. Furthermore, our new AL methods achieved maximal accuracy using 12% fewer labeled cases than the SVM-Margin AL method. However, because labelers have varying levels of expertise, a major issue associated with learning methods, and AL methods in particular, is how to best to use the labeling provided by a committee of labelers. First, we wanted to know, based on the labelers' learning curves, whether using AL methods (versus standard passive learning methods) has an effect on the Intra-labeler variability (within the learning curve of each labeler) and inter-labeler variability (among the learning curves of different labelers). Then, we wanted to examine the effect of learning (either passively or actively) from the labels created by the majority consensus of a group of labelers.
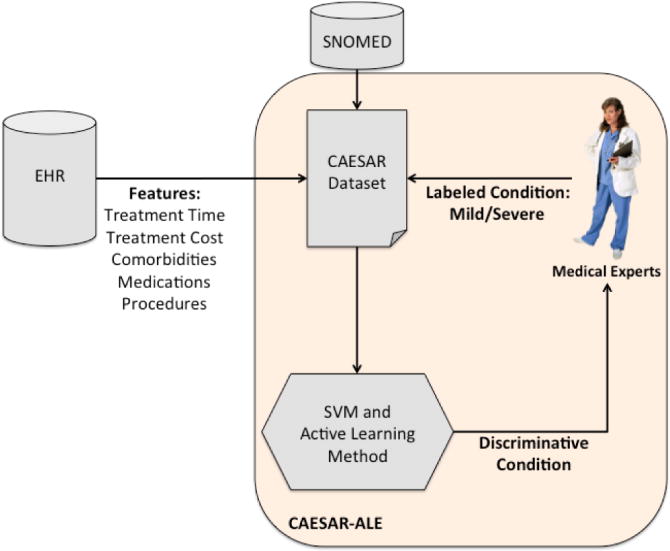
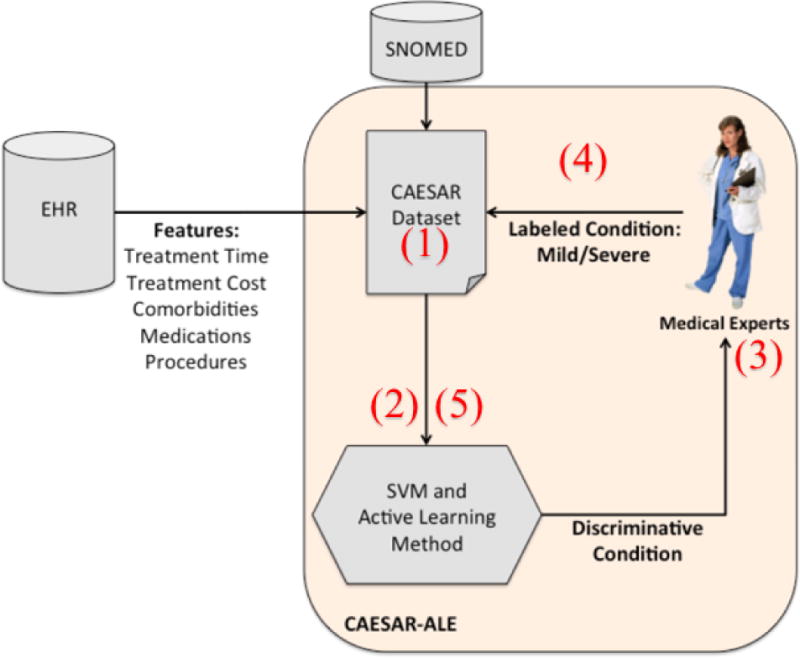
Methods: We used our CAESAR-ALE framework for classifying the severity of clinical conditions, the three AL methods and the passive learning method, as mentioned above, to induce the classifications models. We used a dataset of 516 clinical conditions and their severity labeling, represented by features aggregated from the medical records of 1.9 million patients treated at Columbia University Medical Center. We analyzed the variance of the classification performance within (intra-labeler), and especially among (inter-labeler) the classification models that were induced by using the labels provided by seven labelers. We also compared the performance of the passive and active learning models when using the consensus label.
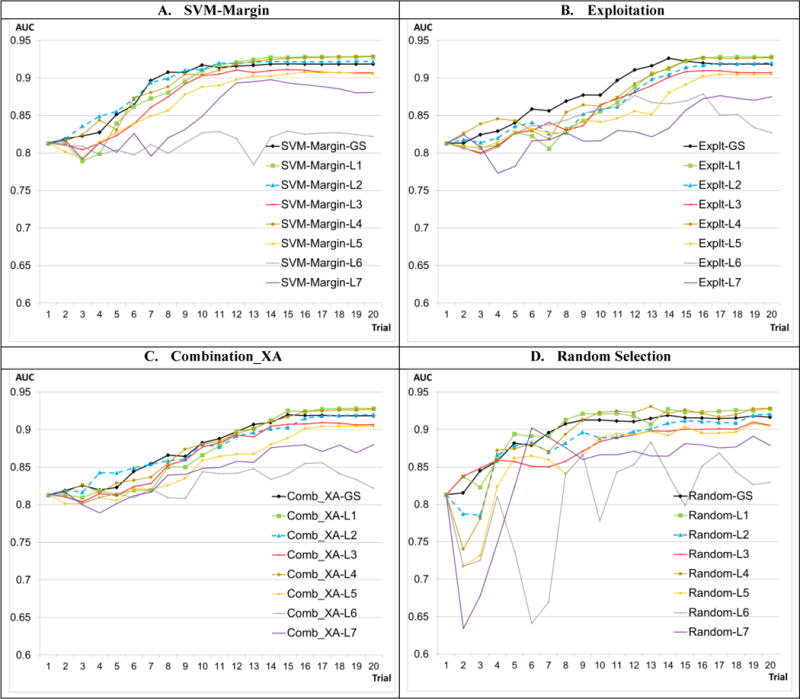
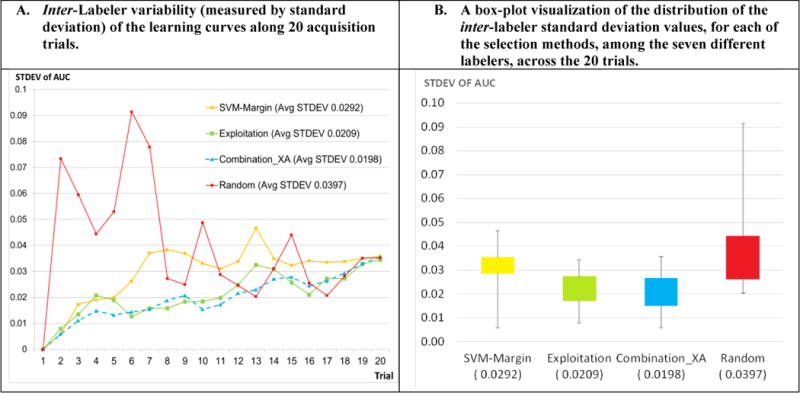
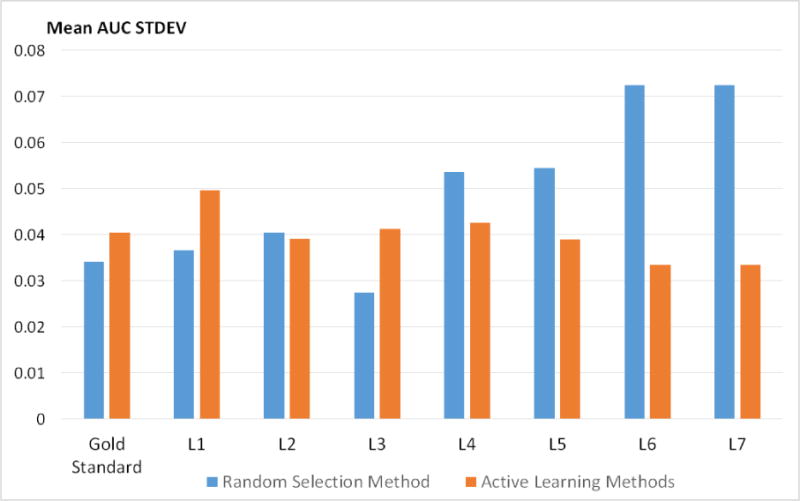
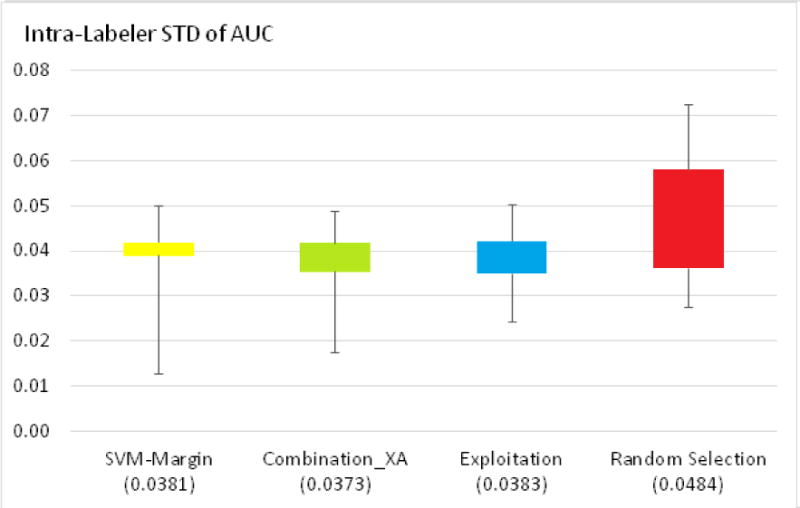
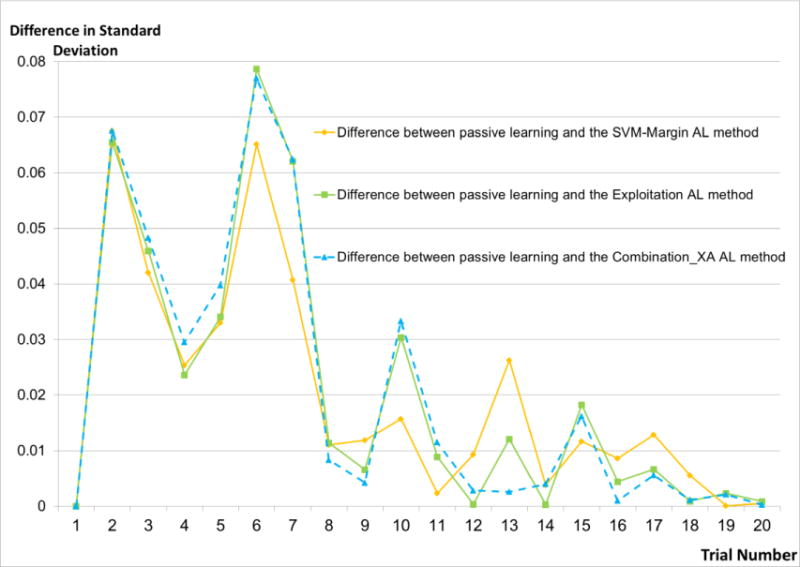
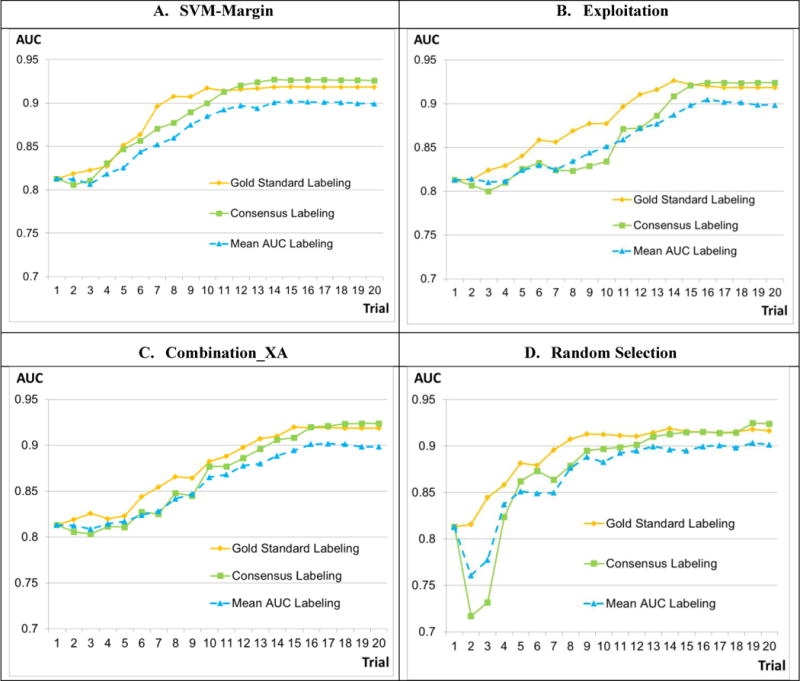
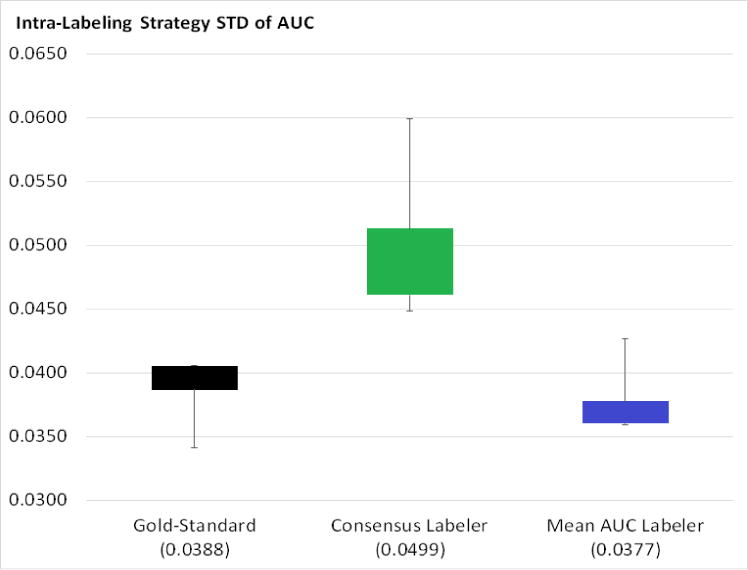
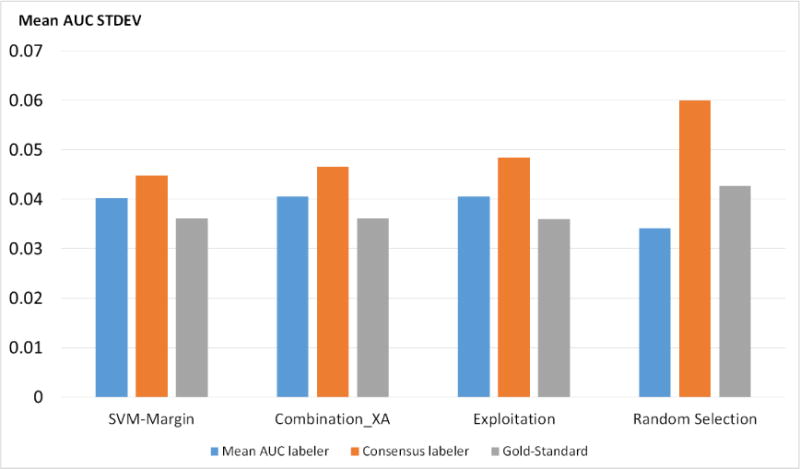
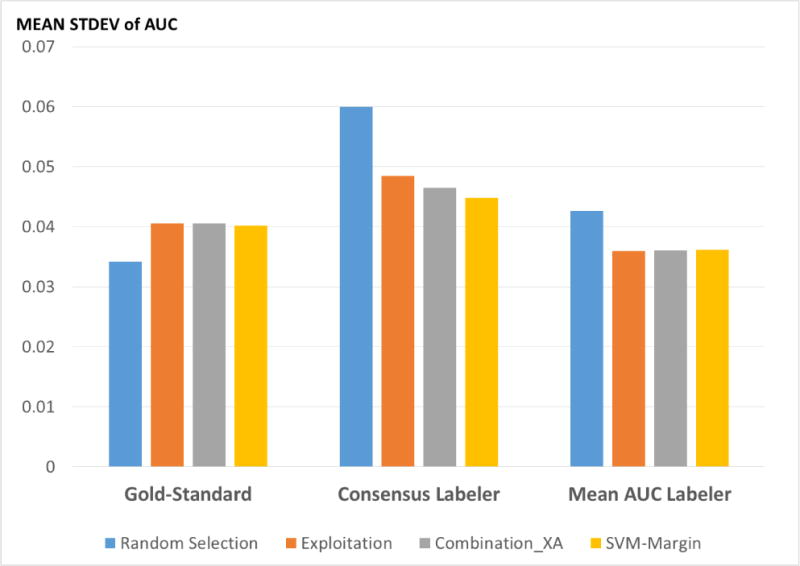
Results: The AL methods: produced, for the models induced from each labeler, smoother Intra-labeler learning curves during the training phase, compared to the models produced when using the passive learning method. The mean standard deviation of the learning curves of the three AL methods over all labelers (mean: 0.0379; range: [0.0182 to 0.0496]), was significantly lower (p=0.049) than the Intra-labeler standard deviation when using the passive learning method (mean: 0.0484; range: [0.0275-0.0724). Using the AL methods resulted in a lower mean Inter-labeler AUC standard deviation among the AUC values of the labelers' different models during the training phase, compared to the variance of the induced models' AUC values when using passive learning. The Inter-labeler AUC standard deviation, using the passive learning method (0.039), was almost twice as high as the Inter-labeler standard deviation using our two new AL methods (0.02 and 0.019, respectively). The SVM-Margin AL method resulted in an Inter-labeler standard deviation (0.029) that was higher by almost 50% than that of our two AL methods The difference in the inter-labeler standard deviation between the passive learning method and the SVM-Margin learning method was significant (p=0.042). The difference between the SVM-Margin and Exploitation method was insignificant (p=0.29), as was the difference between the Combination_XA and Exploitation methods (p=0.67). Finally, using the consensus label led to a learning curve that had a higher mean intra-labeler variance, but resulted eventually in an AUC that was at least as high as the AUC achieved using the gold standard label and that was always higher than the expected mean AUC of a randomly selected labeler, regardless of the choice of learning method (including a passive learning method). Using a paired t-test, the difference between the intra-labeler AUC standard deviation when using the consensus label, versus that value when using the other two labeling strategies, was significant only when using the passive learning method (p=0.014), but not when using any of the three AL methods.
Conclusions: The use of AL methods, (a) reduces intra-labeler variability in the performance of the induced models during the training phase, and thus reduces the risk of halting the process at a local minimum that is significantly different in performance from the rest of the learned models; and (b) reduces Inter-labeler performance variance, and thus reduces the dependence on the use of a particular labeler. In addition, the use of a consensus label, agreed upon by a rather uneven group of labelers, might be at least as good as using the gold standard labeler, who might not be available, and certainly better than randomly selecting one of the group's individual labelers. Finally, using the AL methods: when provided by the consensus label reduced the intra-labeler AUC variance during the learning phase, compared to using passive learning.
Keywords: Active learning; Condition; Electronic health records; Labeling; Phenotyping; Severity; Variance.
Copyright © 2017 Elsevier B.V. All rights reserved.
Figures







References
-
- Stang PE, Ryan PB, Racoosin JA, et al. Advancing the science for active surveillance: rationale and design for the Observational Medical Outcomes Partnership. Ann Intern Med. 2010 Nov 2;153(9):600–6. - PubMed
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
