

Syllable-constituent perception by hearing-aid users: Common factors in quiet and noise
- PMID: 28464618
- PMCID: PMC5848866
- DOI: 10.1121/1.4979703
Syllable-constituent perception by hearing-aid users: Common factors in quiet and noise
Abstract
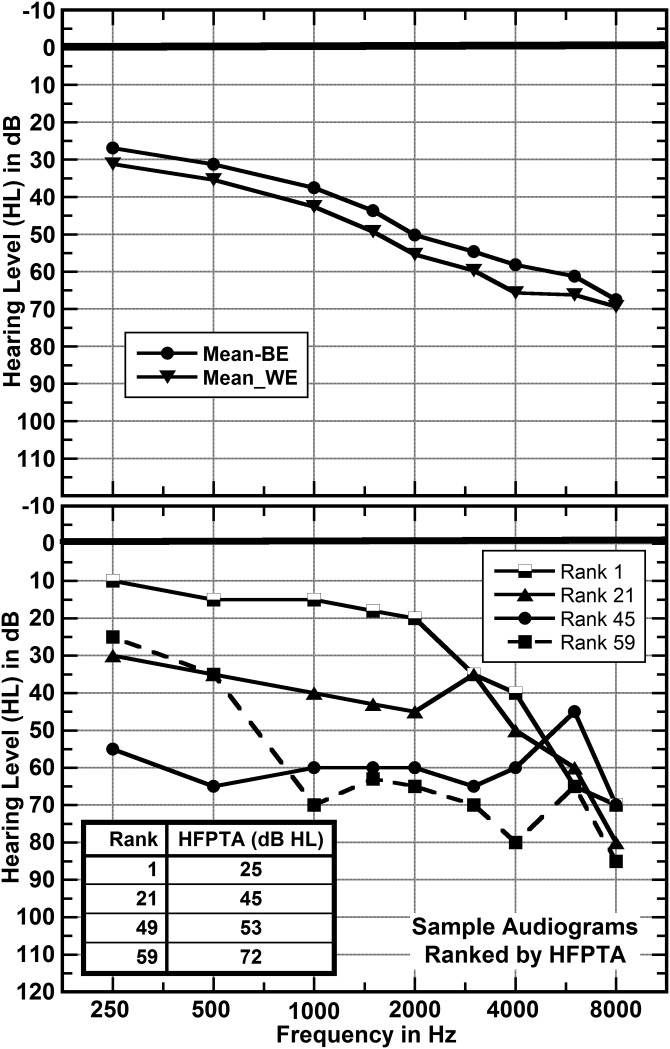
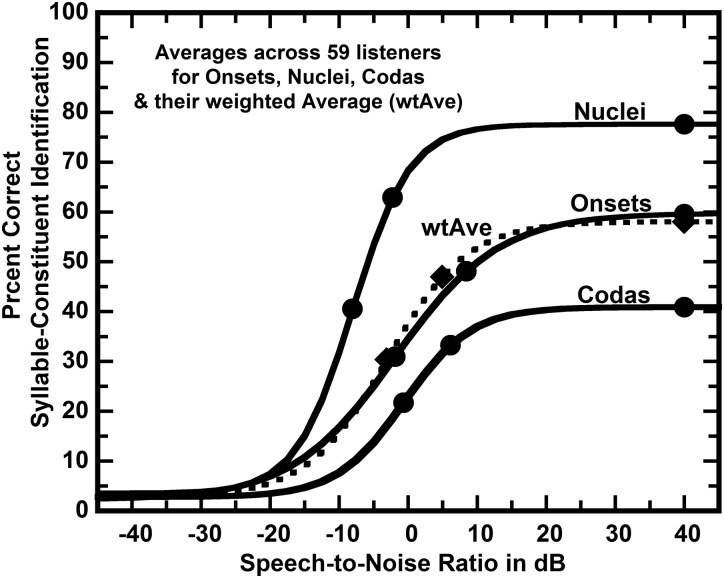
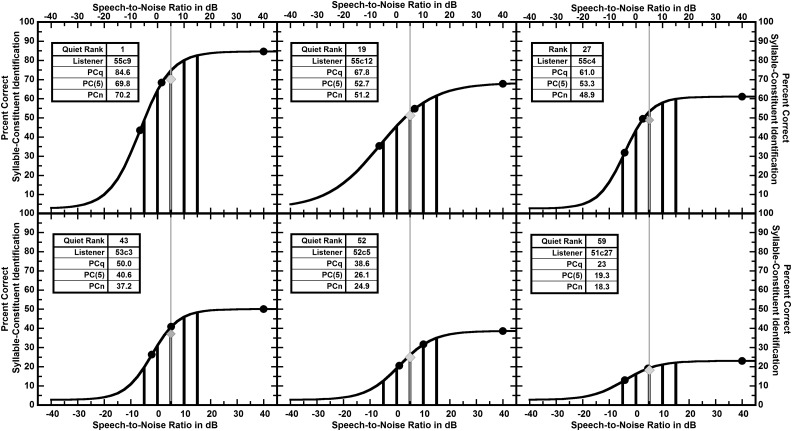
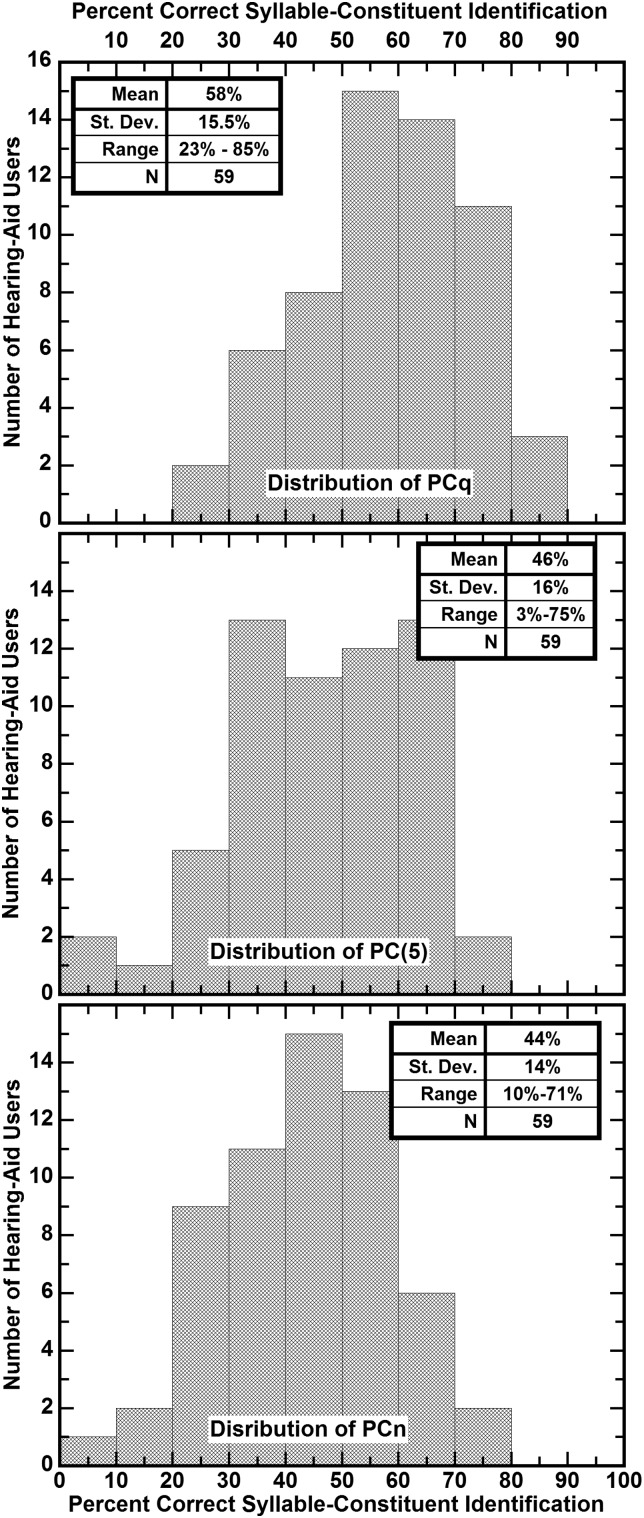
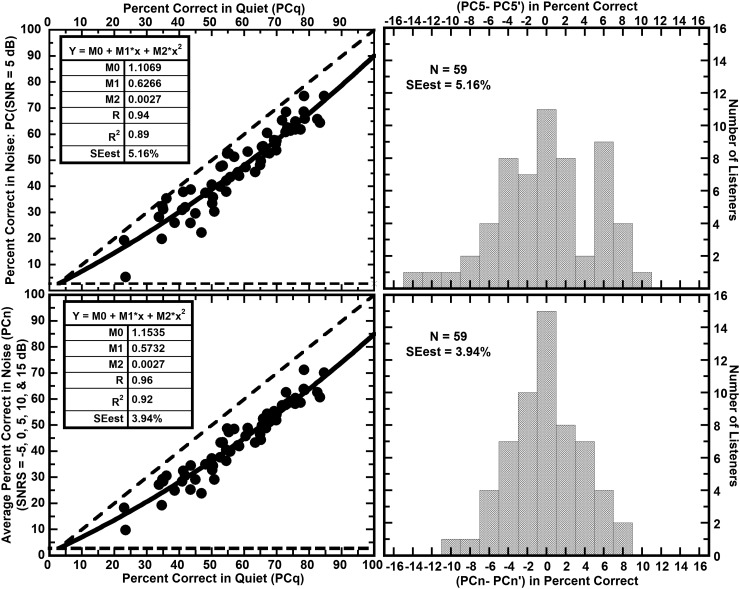
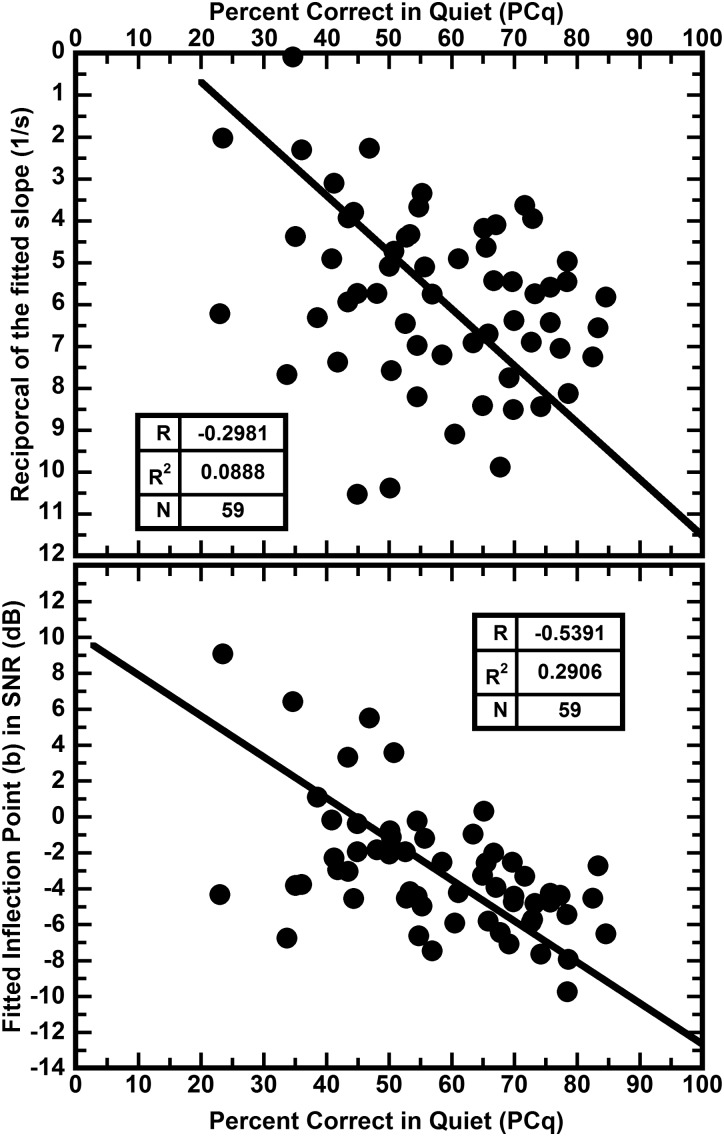
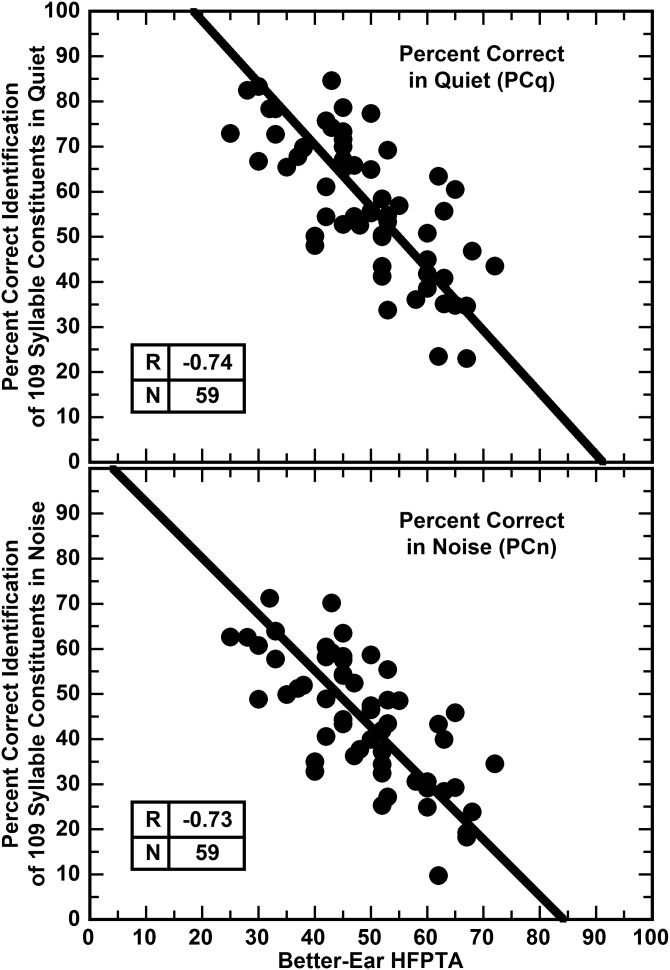
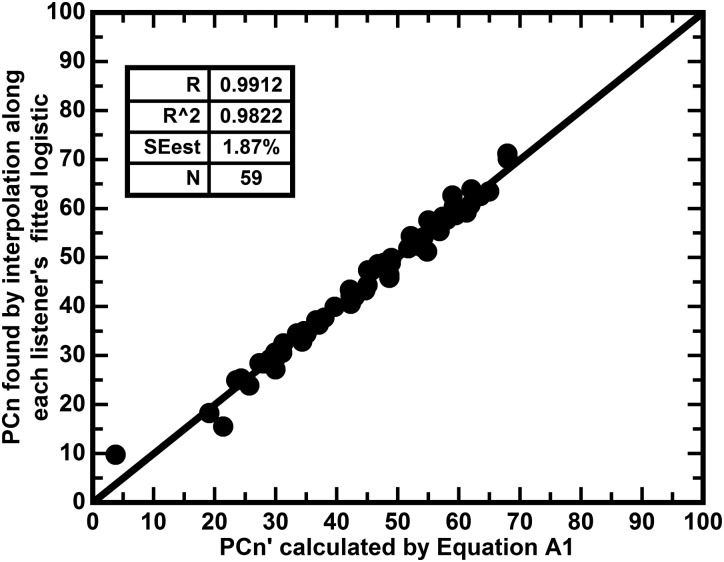
The abilities of 59 adult hearing-aid users to hear phonetic details were assessed by measuring their abilities to identify syllable constituents in quiet and in differing levels of noise (12-talker babble) while wearing their aids. The set of sounds consisted of 109 frequently occurring syllable constituents (45 onsets, 28 nuclei, and 36 codas) spoken in varied phonetic contexts by eight talkers. In nominal quiet, a speech-to-noise ratio (SNR) of 40 dB, scores of individual listeners ranged from about 23% to 85% correct. Averaged over the range of SNRs commonly encountered in noisy situations, scores of individual listeners ranged from about 10% to 71% correct. The scores in quiet and in noise were very strongly correlated, R = 0.96. This high correlation implies that common factors play primary roles in the perception of phonetic details in quiet and in noise. Otherwise said, hearing-aid users' problems perceiving phonetic details in noise appear to be tied to their problems perceiving phonetic details in quiet and vice versa.
Figures
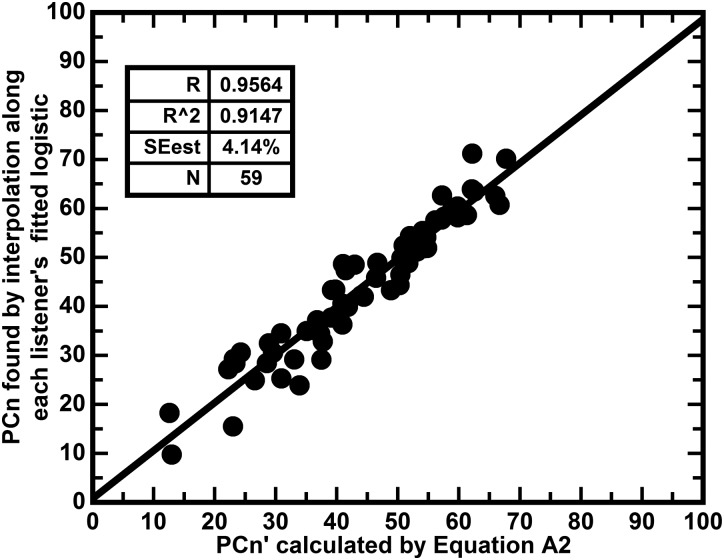
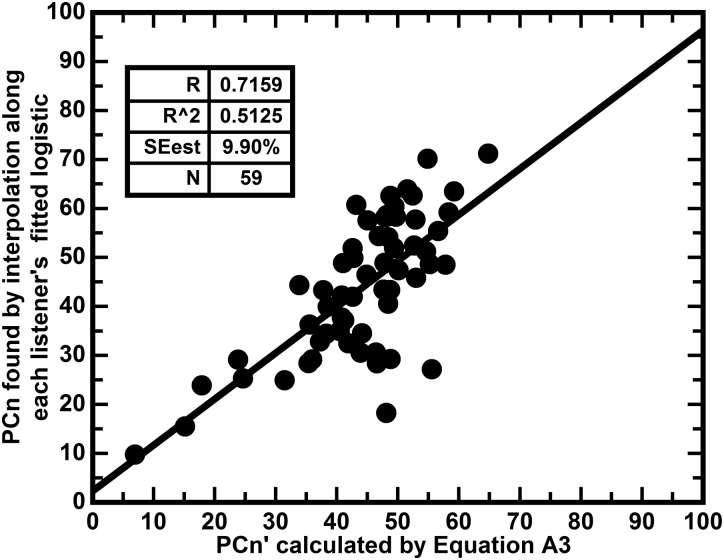
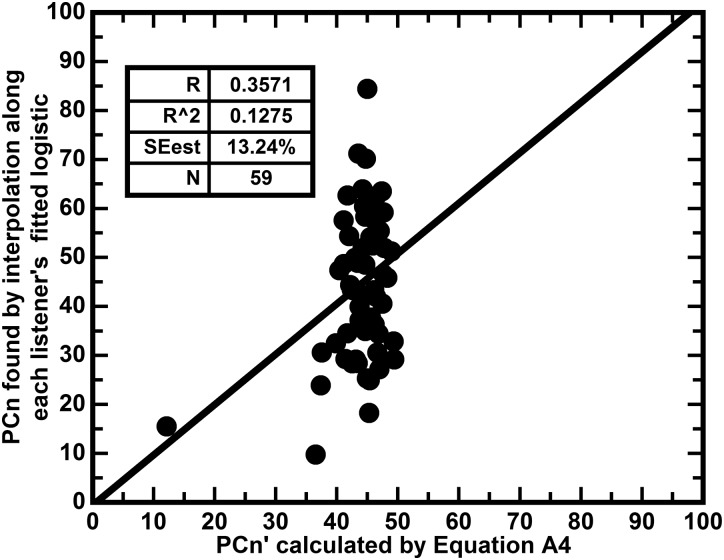
Similar articles
-
An algorithm to improve speech recognition in noise for hearing-impaired listeners.J Acoust Soc Am. 2013 Oct;134(4):3029-38. doi: 10.1121/1.4820893. J Acoust Soc Am. 2013. PMID: 24116438 Free PMC article.
-
The performance of an automatic acoustic-based program classifier compared to hearing aid users' manual selection of listening programs.Int J Audiol. 2018 Mar;57(3):201-212. doi: 10.1080/14992027.2017.1392048. Epub 2017 Oct 25. Int J Audiol. 2018. PMID: 29069954
-
Acoustic and perceptual effects of magnifying interaural difference cues in a simulated "binaural" hearing aid.Int J Audiol. 2018 Jun;57(sup3):S81-S91. doi: 10.1080/14992027.2017.1308564. Epub 2017 Apr 10. Int J Audiol. 2018. PMID: 28395561
-
Assessment of hearing aid algorithms using a master hearing aid: the influence of hearing aid experience on the relationship between speech recognition and cognitive capacity.Int J Audiol. 2018 Jun;57(sup3):S105-S111. doi: 10.1080/14992027.2017.1319079. Epub 2017 Apr 27. Int J Audiol. 2018. PMID: 28449597
-
An algorithm to increase intelligibility for hearing-impaired listeners in the presence of a competing talker.J Acoust Soc Am. 2017 Jun;141(6):4230. doi: 10.1121/1.4984271. J Acoust Soc Am. 2017. PMID: 28618817 Free PMC article.
Cited by
-
Sentence perception in noise by hearing-aid users predicted by syllable-constituent perception and the use of context.J Acoust Soc Am. 2020 Jan;147(1):273. doi: 10.1121/10.0000563. J Acoust Soc Am. 2020. PMID: 32006979 Free PMC article.
-
Ear Asymmetry and Contextual Influences on Speech Perception in Hearing-Impaired Patients.Front Neurosci. 2022 Mar 18;16:801699. doi: 10.3389/fnins.2022.801699. eCollection 2022. Front Neurosci. 2022. PMID: 35368258 Free PMC article.
-
Listening Effort Is Not the Same as Speech Intelligibility Score.Trends Hear. 2021 Jan-Dec;25:23312165211027688. doi: 10.1177/23312165211027688. Trends Hear. 2021. PMID: 34261392 Free PMC article.
References
-
- French, N. R. , and Steinberg, J. C. (1947). “ Factors governing the intelligibility of speech sounds,” J. Acoust. Soc. Am. 19, 90–119.10.1121/1.1916407 - DOI
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
Miscellaneous