

TwiMed: Twitter and PubMed Comparable Corpus of Drugs, Diseases, Symptoms, and Their Relations
- PMID: 28468748
- PMCID: PMC5438461
- DOI: 10.2196/publichealth.6396
TwiMed: Twitter and PubMed Comparable Corpus of Drugs, Diseases, Symptoms, and Their Relations
Abstract
Background: Work on pharmacovigilance systems using texts from PubMed and Twitter typically target at different elements and use different annotation guidelines resulting in a scenario where there is no comparable set of documents from both Twitter and PubMed annotated in the same manner.
Objective: This study aimed to provide a comparable corpus of texts from PubMed and Twitter that can be used to study drug reports from these two sources of information, allowing researchers in the area of pharmacovigilance using natural language processing (NLP) to perform experiments to better understand the similarities and differences between drug reports in Twitter and PubMed.
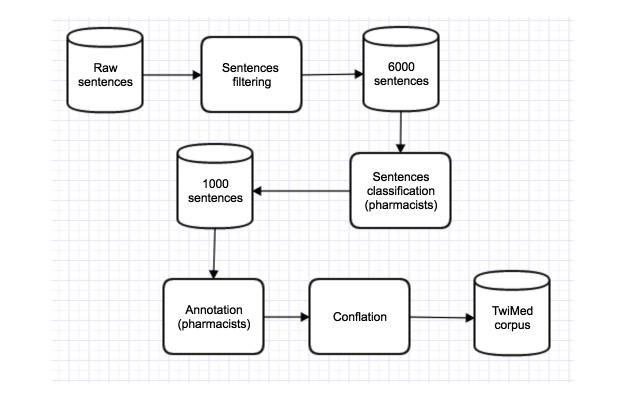
Methods: We produced a corpus comprising 1000 tweets and 1000 PubMed sentences selected using the same strategy and annotated at entity level by the same experts (pharmacists) using the same set of guidelines.
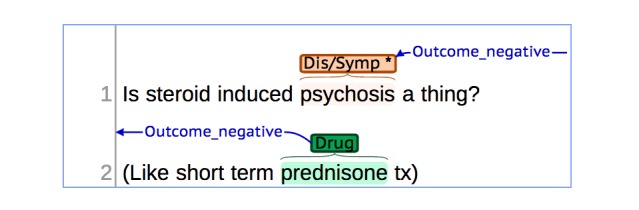
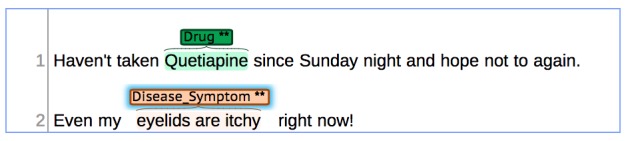
Results: The resulting corpus, annotated by two pharmacists, comprises semantically correct annotations for a set of drugs, diseases, and symptoms. This corpus contains the annotations for 3144 entities, 2749 relations, and 5003 attributes.
Conclusions: We present a corpus that is unique in its characteristics as this is the first corpus for pharmacovigilance curated from Twitter messages and PubMed sentences using the same data selection and annotation strategies. We believe this corpus will be of particular interest for researchers willing to compare results from pharmacovigilance systems (eg, classifiers and named entity recognition systems) when using data from Twitter and from PubMed. We hope that given the comprehensive set of drug names and the annotated entities and relations, this corpus becomes a standard resource to compare results from different pharmacovigilance studies in the area of NLP.
Keywords: PubMed; Twitter; annotation; corpus; natural language processing; pharmacovigilance; text mining.
©Nestor Alvaro, Yusuke Miyao, Nigel Collier. Originally published in JMIR Public Health and Surveillance (http://publichealth.jmir.org), 03.05.2017.
Conflict of interest statement
Conflicts of Interest: None declared.
Figures
References
-
- Hakala K, Van Landeghem S, Salakoski T, Van de Peer Y, Ginter F. Application of the EVEX resource to event extraction and network construction: Shared Task entry and result analysis. BMC Bioinformatics; BioNLP Shared Task 2013; August 9, 2013; Sofia, Bulgaria. 2015. p. S3. https://bmcbioinformatics.biomedcentral.com/articles/10.1186/1471-2105-1... - DOI - DOI - PMC - PubMed
-
- Sarker A, Ginn R, Nikfarjam A, O'Connor K, Smith K, Jayaraman S, Upadhaya T, Gonzalez G. Utilizing social media data for pharmacovigilance: a review. J Biomed Inform. 2015 Apr;54:202–12. doi: 10.1016/j.jbi.2015.02.004. http://linkinghub.elsevier.com/retrieve/pii/S1532-0464(15)00036-2 - DOI - PMC - PubMed
-
- Nikfarjam A, Sarker A, O'Connor K, Ginn R, Gonzalez G. Pharmacovigilance from social media: mining adverse drug reaction mentions using sequence labeling with word embedding cluster features. J Am Med Inform Assoc. 2015 May;22(3):671–81. doi: 10.1093/jamia/ocu041. http://europepmc.org/abstract/MED/25755127 - DOI - PMC - PubMed
LinkOut - more resources
Full Text Sources
Other Literature Sources
