

doi: 10.1038/nbt.3790.
Discovering and linking public omics data sets using the Omics Discovery Index
Affiliations
- PMID: 28486464
- PMCID: PMC5831141
- DOI: 10.1038/nbt.3790
Item in Clipboard
Discovering and linking public omics data sets using the Omics Discovery Index
Nat Biotechnol.
.
No abstract available
Figures
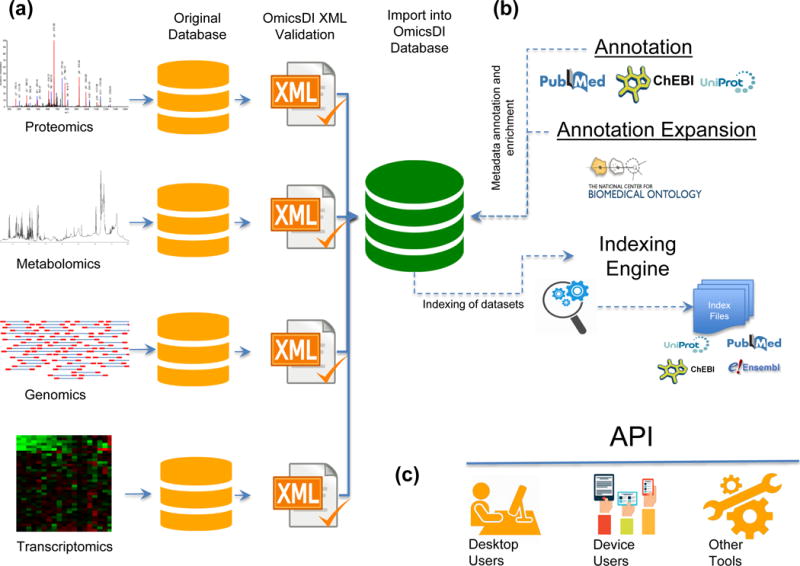
Omics Discovery Index: data standardization, annotation, index and presentation. (a) The datasets stored in public repositories are converted to a common data representation including all metadata and biological entities. The OmicsDI XML files are validated using the OmicsDI XML validator. (b) The OmicsDI XML files are then annotated using public services and databases like UniProt, ChEBI, and PubMed, and the metadata is enriched using the Annotator service. The EBI search engine generates the indexes including other related resources such as PubMed, UniProt, Ensembl and ChEBI. (c) Different clients can use the OmicsDI API to retrieve data from the resource including the web interface and the ddiR package.
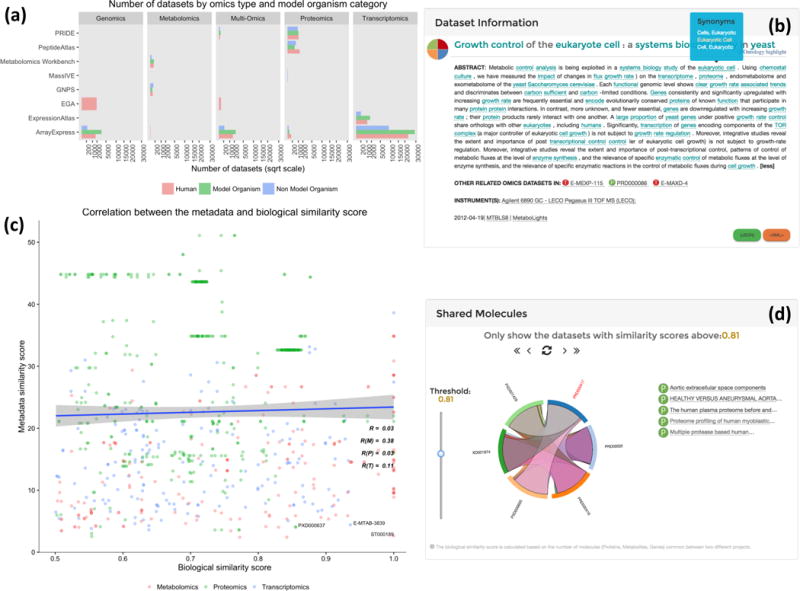
Distributions of OmicsDI datasets. (a) Distribution of datasets per omics type and organism category including model organisms, non-model organisms (excluding human) and human. (b) The dataset view showing the other related omics datasets, including the ontology highlighting option to extract the most relevant terms in the metadata. (c) Pearson-correlation plot between the metadata similarity score and the biological similarity score, across transcriptomics (T), proteomics (P) and metabolomics (M) datasets. (d) The shared molecules box shows all datasets with a biological similarity score of more than 0.5, with a slider allowing a user to increase the cutoff value (here set to 0.81).
References
Publication types
MeSH terms
Grants and funding
- U01 CA198941/CA/NCI NIH HHS/United States
- BB/L024225/1/BB_/Biotechnology and Biological Sciences Research Council/United Kingdom
- U24 CA210967/CA/NCI NIH HHS/United States
- P41 GM103484/GM/NIGMS NIH HHS/United States
- U54 GM114833/GM/NIGMS NIH HHS/United States
- BB/I000771/1/BB_/Biotechnology and Biological Sciences Research Council/United Kingdom
- R01 GM094231/GM/NIGMS NIH HHS/United States
- WT_/Wellcome Trust/United Kingdom
- WT101477MA/WT_/Wellcome Trust/United Kingdom
- BB/E025080/1/BB_/Biotechnology and Biological Sciences Research Council/United Kingdom
- BB/K01997X/1/BB_/Biotechnology and Biological Sciences Research Council/United Kingdom
- U24 AI117966/AI/NIAID NIH HHS/United States
- U01 DK097430/DK/NIDDK NIH HHS/United States
LinkOut - more resources
Full Text Sources
Other Literature Sources
