

Bioinformatics in translational drug discovery
- PMID: 28487472
- PMCID: PMC6448364
- DOI: 10.1042/BSR20160180
Bioinformatics in translational drug discovery
Abstract
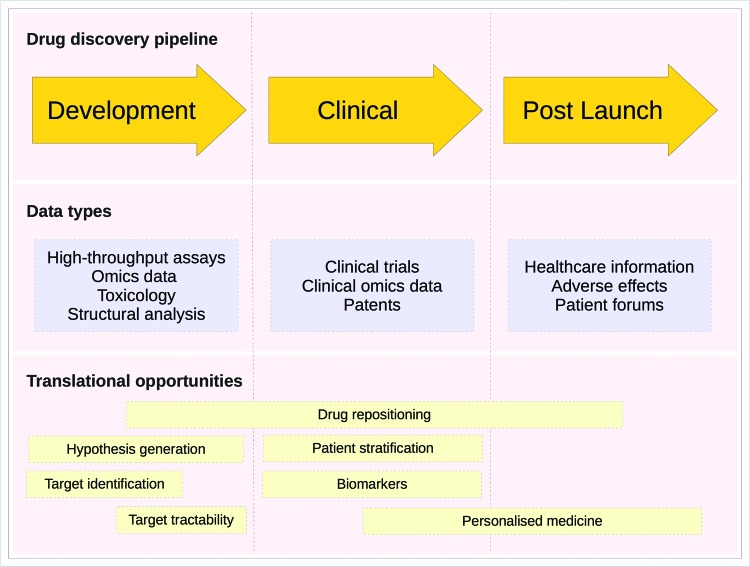
Bioinformatics approaches are becoming ever more essential in translational drug discovery both in academia and within the pharmaceutical industry. Computational exploitation of the increasing volumes of data generated during all phases of drug discovery is enabling key challenges of the process to be addressed. Here, we highlight some of the areas in which bioinformatics resources and methods are being developed to support the drug discovery pipeline. These include the creation of large data warehouses, bioinformatics algorithms to analyse 'big data' that identify novel drug targets and/or biomarkers, programs to assess the tractability of targets, and prediction of repositioning opportunities that use licensed drugs to treat additional indications.
Keywords: computational biochemistry; drug discovery and design; genomics.
© 2017 The Author(s).
Conflict of interest statement
The authors declare that there are no competing interests associated with the manuscript.
Figures
References
-
- Paul S.M., Mytelka D.S., Dunwiddie C.T., Persinger C.C., Munos B.H., Lindborg S.R. et al. (2010) How to improve R &D productivity: the pharmaceutical industry's grand challenge. Nat. Rev. Drug Discov. 9, 203–214 - PubMed
-
- Kola I. and Landis J. (2004) Can the pharmaceutical industry reduce attrition rates? Nat. Rev. Drug Discov. 3, 711–715 - PubMed
-
- Loging W., Harland L. and William-Jones B. (2007) High-throughput electronic biology: mining information for drug discovery. Nat. Rev. Drug Discov. 6, 220–230 - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources