

A Selective Role for Dopamine in Learning to Maximize Reward But Not to Minimize Effort: Evidence from Patients with Parkinson's Disease
- PMID: 28539420
- PMCID: PMC6596498
- DOI: 10.1523/JNEUROSCI.2081-16.2017
A Selective Role for Dopamine in Learning to Maximize Reward But Not to Minimize Effort: Evidence from Patients with Parkinson's Disease
Abstract
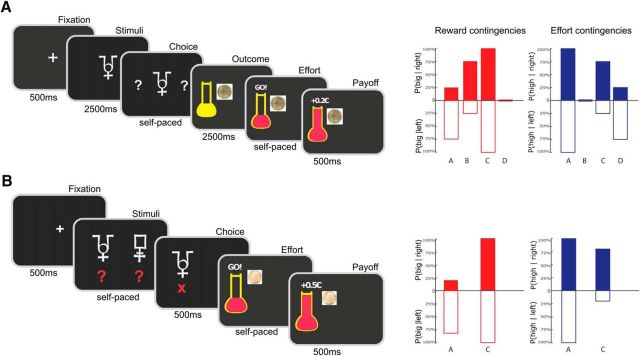
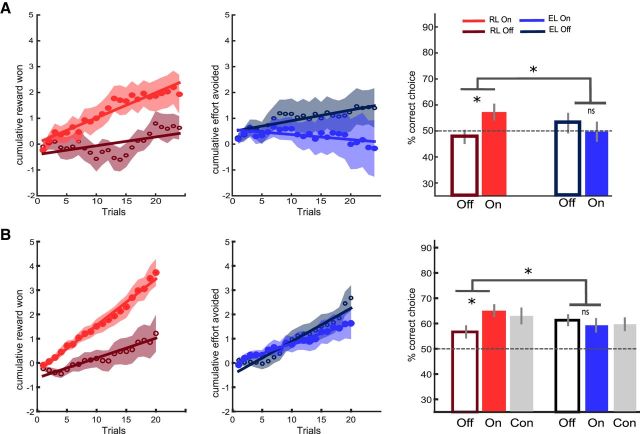
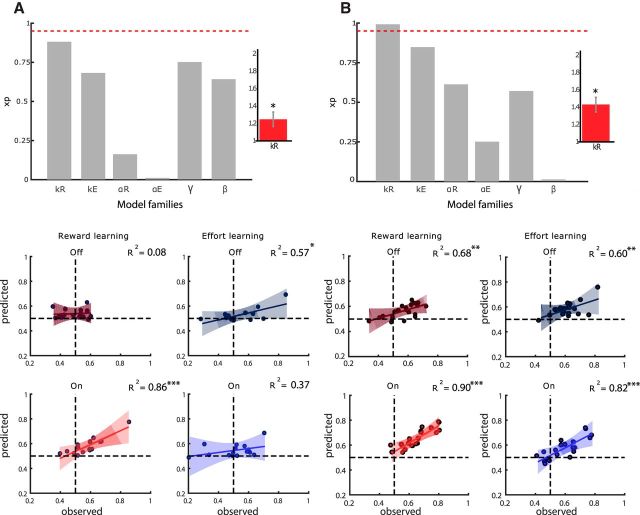
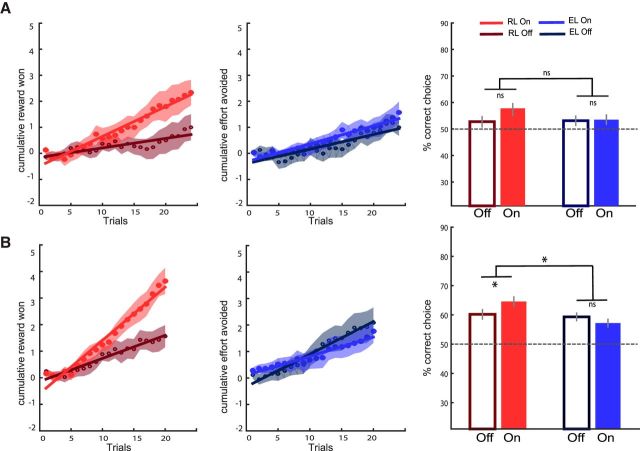
Instrumental learning is a fundamental process through which agents optimize their choices, taking into account various dimensions of available options such as the possible reward or punishment outcomes and the costs associated with potential actions. Although the implication of dopamine in learning from choice outcomes is well established, less is known about its role in learning the action costs such as effort. Here, we tested the ability of patients with Parkinson's disease (PD) to maximize monetary rewards and minimize physical efforts in a probabilistic instrumental learning task. The implication of dopamine was assessed by comparing performance ON and OFF prodopaminergic medication. In a first sample of PD patients (n = 15), we observed that reward learning, but not effort learning, was selectively impaired in the absence of treatment, with a significant interaction between learning condition (reward vs effort) and medication status (OFF vs ON). These results were replicated in a second, independent sample of PD patients (n = 20) using a simplified version of the task. According to Bayesian model selection, the best account for medication effects in both studies was a specific amplification of reward magnitude in a Q-learning algorithm. These results suggest that learning to avoid physical effort is independent from dopaminergic circuits and strengthen the general idea that dopaminergic signaling amplifies the effects of reward expectation or obtainment on instrumental behavior.SIGNIFICANCE STATEMENT Theoretically, maximizing reward and minimizing effort could involve the same computations and therefore rely on the same brain circuits. Here, we tested whether dopamine, a key component of reward-related circuitry, is also implicated in effort learning. We found that patients suffering from dopamine depletion due to Parkinson's disease were selectively impaired in reward learning, but not effort learning. Moreover, anti-parkinsonian medication restored the ability to maximize reward, but had no effect on effort minimization. This dissociation suggests that the brain has evolved separate, domain-specific systems for instrumental learning. These results help to disambiguate the motivational role of prodopaminergic medications: they amplify the impact of reward without affecting the integration of effort cost.
Keywords: Parkinson's disease; dopamine; effort learning; modeling; reinforcement learning; reward learning.
Copyright © 2017 the authors 0270-6474/17/376087-11$15.00/0.
Figures
References
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
Miscellaneous