

Identifying reports of randomized controlled trials (RCTs) via a hybrid machine learning and crowdsourcing approach
- PMID: 28541493
- PMCID: PMC5975623
- DOI: 10.1093/jamia/ocx053
Identifying reports of randomized controlled trials (RCTs) via a hybrid machine learning and crowdsourcing approach
Abstract
Objectives: Identifying all published reports of randomized controlled trials (RCTs) is an important aim, but it requires extensive manual effort to separate RCTs from non-RCTs, even using current machine learning (ML) approaches. We aimed to make this process more efficient via a hybrid approach using both crowdsourcing and ML.
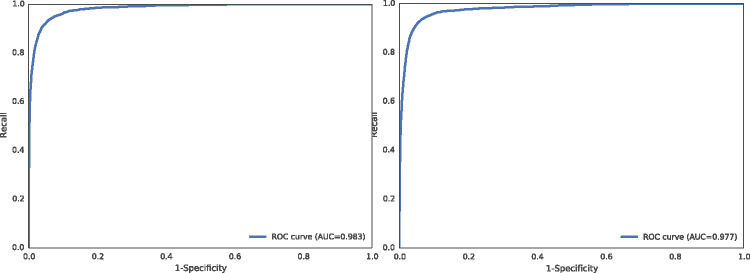
Methods: We trained a classifier to discriminate between citations that describe RCTs and those that do not. We then adopted a simple strategy of automatically excluding citations deemed very unlikely to be RCTs by the classifier and deferring to crowdworkers otherwise.
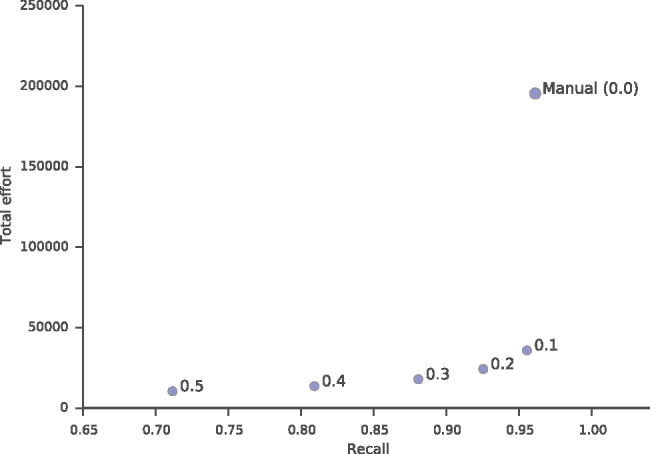
Results: Combining ML and crowdsourcing provides a highly sensitive RCT identification strategy (our estimates suggest 95%-99% recall) with substantially less effort (we observed a reduction of around 60%-80%) than relying on manual screening alone.
Conclusions: Hybrid crowd-ML strategies warrant further exploration for biomedical curation/annotation tasks.
Keywords: crowdsourcing; evidence-based medicine; human computation; machine learning; natural language processing.
© The Author 2017. Published by Oxford University Press on behalf of the American Medical Informatics Association.
Figures
References
-
- Chalmers I. The Cochrane collaboration: preparing, maintaining, and disseminating systematic reviews of the effects of health care. Ann NY Acad Sci. 1993;7031:156–65. - PubMed
-
- McKibbon KA, Wilczynskil NL, Haynes RB. Retrieving randomized controlled trials from Medline: a comparison of 38 published search filters. Health Info Libr J. 2009;263:187–202. - PubMed
-
- Wieland LS, Robinson KA, Dickersin K. Understanding why evidence from randomised clinical trials may not be retrieved from Medline: comparison of indexed and non-indexed records. Brit Med J. 2012;344:2008–12. - PubMed
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
