

Genome annotation for clinical genomic diagnostics: strengths and weaknesses
- PMID: 28558813
- PMCID: PMC5448149
- DOI: 10.1186/s13073-017-0441-1
Genome annotation for clinical genomic diagnostics: strengths and weaknesses
Abstract
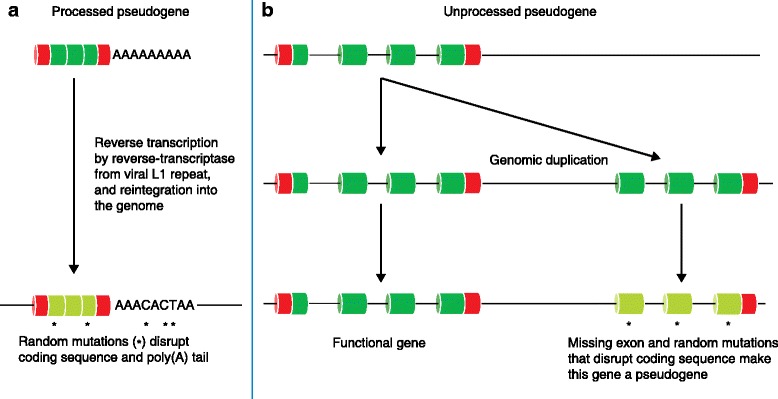
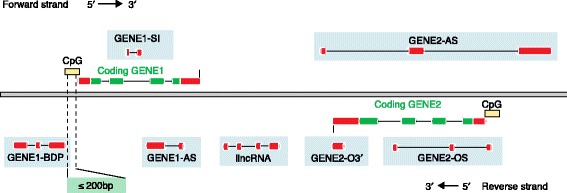
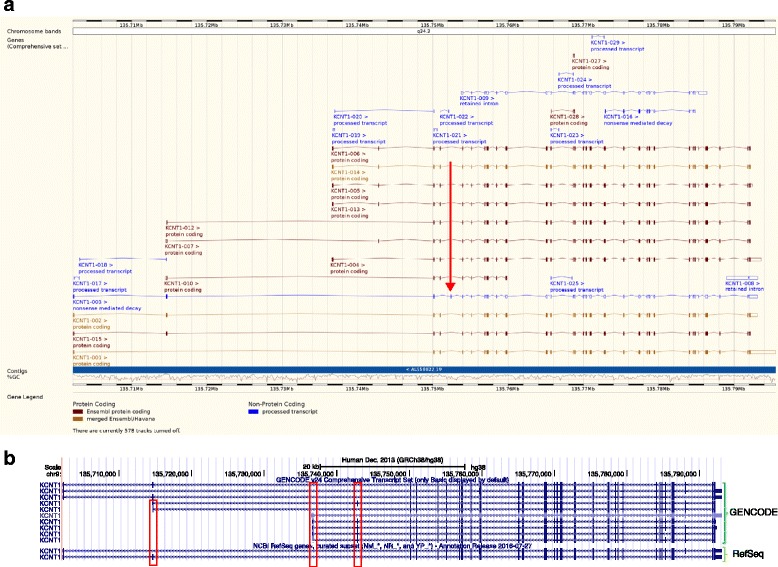
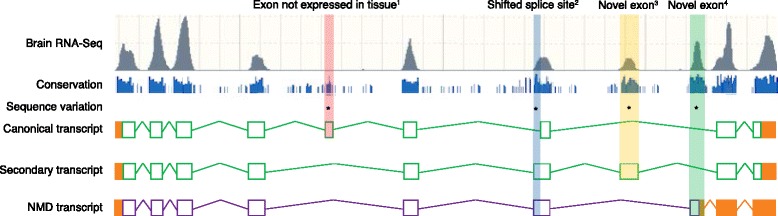
The Human Genome Project and advances in DNA sequencing technologies have revolutionized the identification of genetic disorders through the use of clinical exome sequencing. However, in a considerable number of patients, the genetic basis remains unclear. As clinicians begin to consider whole-genome sequencing, an understanding of the processes and tools involved and the factors to consider in the annotation of the structure and function of genomic elements that might influence variant identification is crucial. Here, we discuss and illustrate the strengths and weaknesses of approaches for the annotation and classification of important elements of protein-coding genes, other genomic elements such as pseudogenes and the non-coding genome, comparative-genomic approaches for inferring gene function, and new technologies for aiding genome annotation, as a practical guide for clinicians when considering pathogenic sequence variation. Complete and accurate annotation of structure and function of genome features has the potential to reduce both false-negative (from missing annotation) and false-positive (from incorrect annotation) errors in causal variant identification in exome and genome sequences. Re-analysis of unsolved cases will be necessary as newer technology improves genome annotation, potentially improving the rate of diagnosis.
Figures
Similar articles
-
How to Identify Pathogenic Mutations among All Those Variations: Variant Annotation and Filtration in the Genome Sequencing Era.Hum Mutat. 2016 Dec;37(12):1272-1282. doi: 10.1002/humu.23110. Epub 2016 Sep 26. Hum Mutat. 2016. PMID: 27599893 Review.
-
Gene and Variant Annotation for Mendelian Disorders in the Era of Advanced Sequencing Technologies.Annu Rev Genomics Hum Genet. 2017 Aug 31;18:229-256. doi: 10.1146/annurev-genom-083115-022545. Epub 2017 Apr 17. Annu Rev Genomics Hum Genet. 2017. PMID: 28415856 Review.
-
Computational Methods for Pseudogene Annotation Based on Sequence Homology.Methods Mol Biol. 2021;2324:35-48. doi: 10.1007/978-1-0716-1503-4_3. Methods Mol Biol. 2021. PMID: 34165707 Review.
-
[Analysis, identification and correction of some errors of model refseqs appeared in NCBI Human Gene Database by in silico cloning and experimental verification of novel human genes].Yi Chuan Xue Bao. 2004 May;31(5):431-43. Yi Chuan Xue Bao. 2004. PMID: 15478601 Chinese.
-
In Silico Functional Annotation of Genomic Variation.Curr Protoc Hum Genet. 2016 Jan 1;88:6.15.1-6.15.17. doi: 10.1002/0471142905.hg0615s88. Curr Protoc Hum Genet. 2016. PMID: 26724722 Free PMC article. Review.
Cited by
-
Three Rounds of Read Correction Significantly Improve Eukaryotic Protein Detection in ONT Reads.Microorganisms. 2024 Jan 24;12(2):247. doi: 10.3390/microorganisms12020247. Microorganisms. 2024. PMID: 38399651 Free PMC article.
-
Genome-Wide Sequencing Modalities for Children with Unexplained Global Developmental Delay and Intellectual Disabilities-A Narrative Review.Children (Basel). 2023 Mar 3;10(3):501. doi: 10.3390/children10030501. Children (Basel). 2023. PMID: 36980059 Free PMC article. Review.
-
Evolution of Sequence and Structure of SARS-CoV-2 Spike Protein: A Dynamic Perspective.ACS Omega. 2023 Jun 21;8(26):23283-23304. doi: 10.1021/acsomega.3c00944. eCollection 2023 Jul 4. ACS Omega. 2023. PMID: 37426203 Free PMC article. Review.
-
Review on the Computational Genome Annotation of Sequences Obtained by Next-Generation Sequencing.Biology (Basel). 2020 Sep 18;9(9):295. doi: 10.3390/biology9090295. Biology (Basel). 2020. PMID: 32962098 Free PMC article. Review.
-
The future of cystic fibrosis care: a global perspective.Lancet Respir Med. 2020 Jan;8(1):65-124. doi: 10.1016/S2213-2600(19)30337-6. Epub 2019 Sep 27. Lancet Respir Med. 2020. PMID: 31570318 Free PMC article. Review.
References
-
- GENCODE. Human GENCODE version 24. 2016. http://www.gencodegenes.org/stats/current.html. Accessed 14 Feb 2017.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Research Materials
