

Structural and Functional Insights into WRKY3 and WRKY4 Transcription Factors to Unravel the WRKY-DNA (W-Box) Complex Interaction in Tomato (Solanum lycopersicum L.). A Computational Approach
- PMID: 28611792
- PMCID: PMC5447077
- DOI: 10.3389/fpls.2017.00819
Structural and Functional Insights into WRKY3 and WRKY4 Transcription Factors to Unravel the WRKY-DNA (W-Box) Complex Interaction in Tomato (Solanum lycopersicum L.). A Computational Approach
Abstract
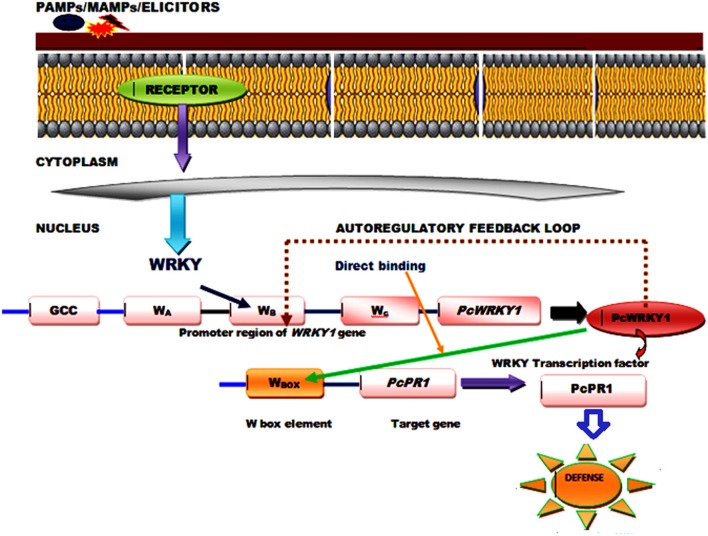
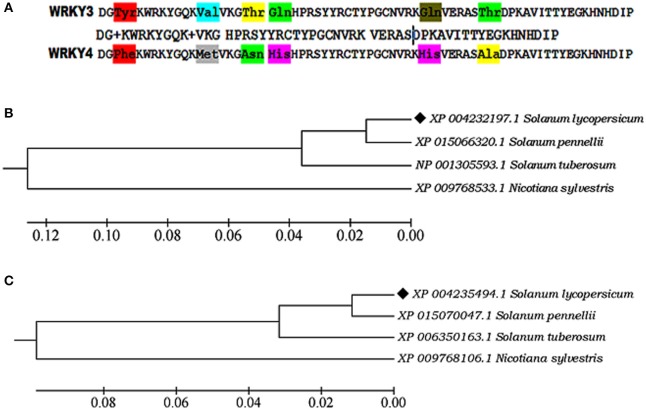
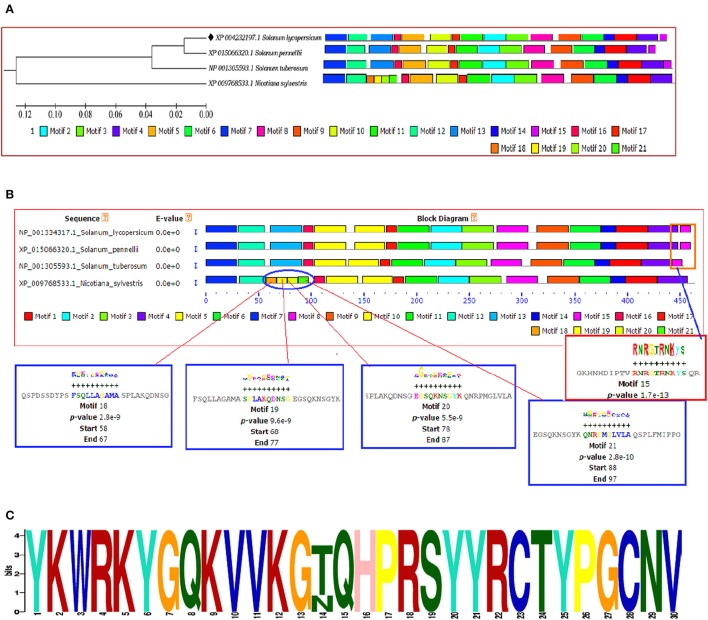
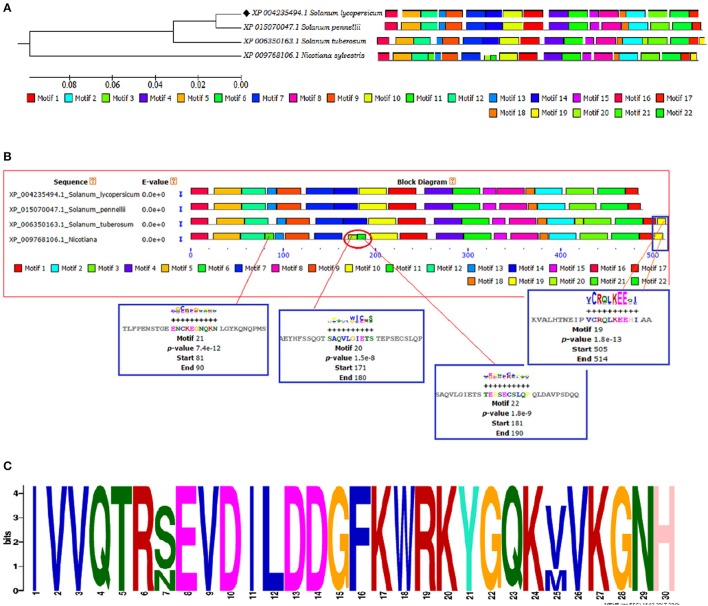
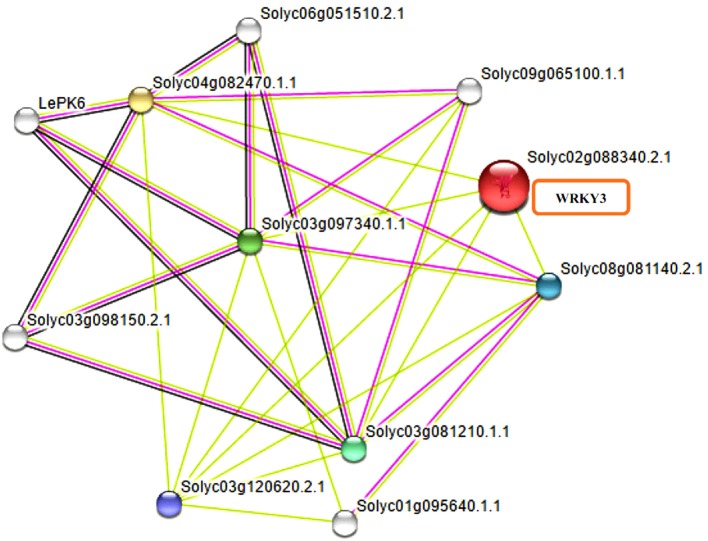
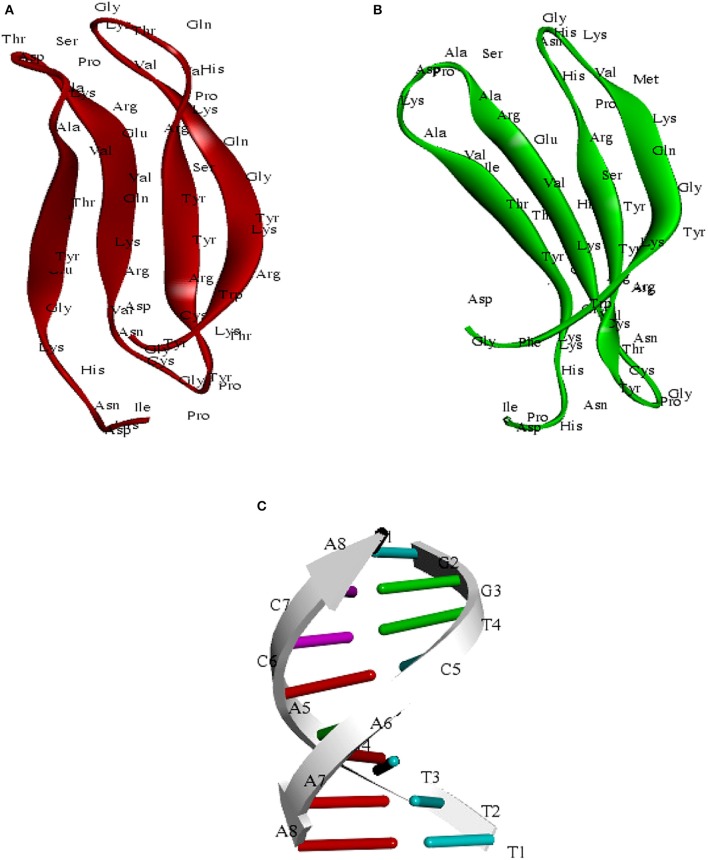
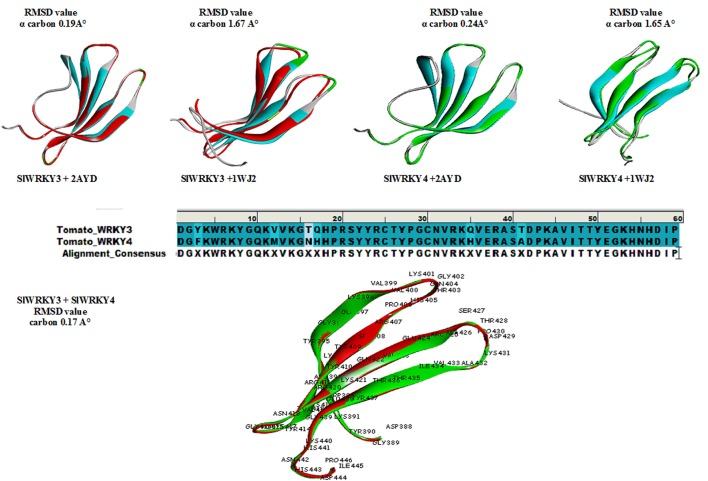
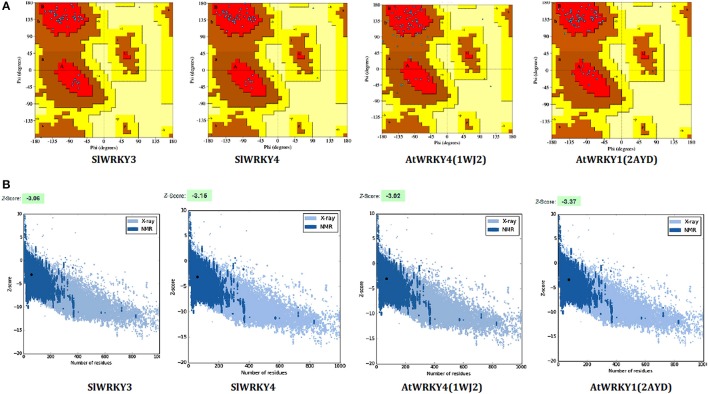
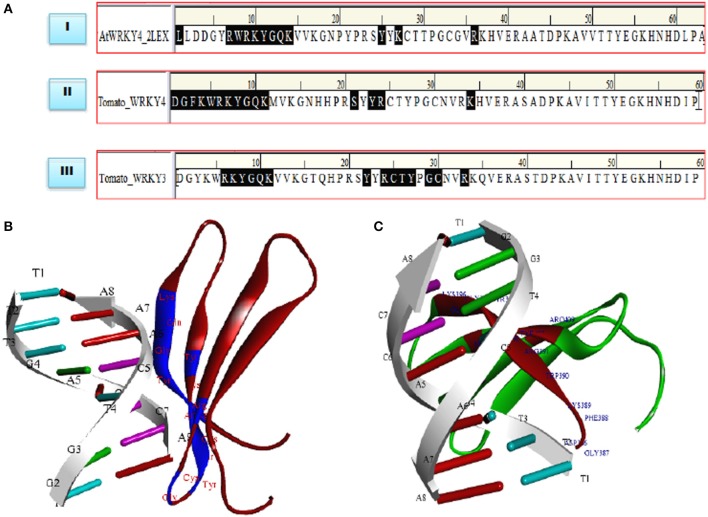
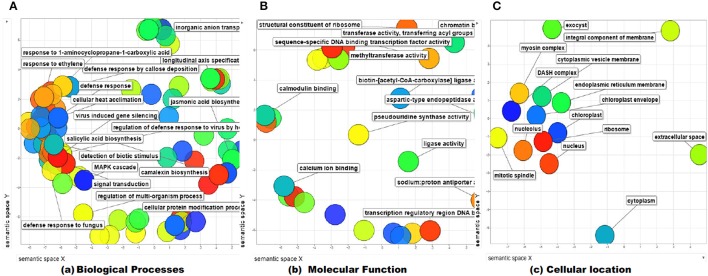
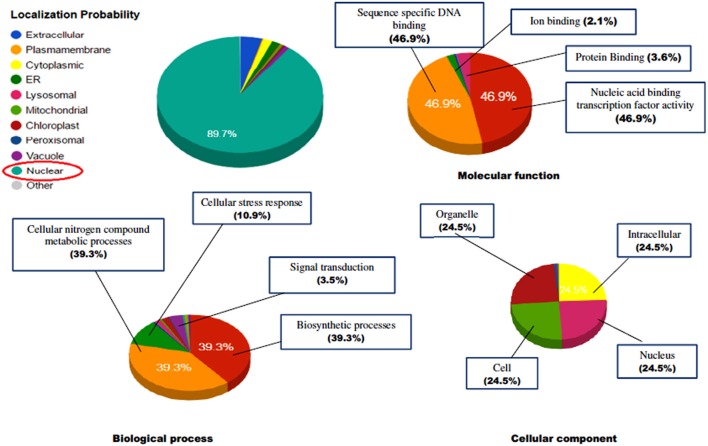
The WRKY transcription factors (TFs), play crucial role in plant defense response against various abiotic and biotic stresses. The role of WRKY3 and WRKY4 genes in plant defense response against necrotrophic pathogens is well-reported. However, their functional annotation in tomato is largely unknown. In the present work, we have characterized the structural and functional attributes of the two identified tomato WRKY transcription factors, WRKY3 (SlWRKY3), and WRKY4 (SlWRKY4) using computational approaches. Arabidopsis WRKY3 (AtWRKY3: NP_178433) and WRKY4 (AtWRKY4: NP_172849) protein sequences were retrieved from TAIR database and protein BLAST was done for finding their sequential homologs in tomato. Sequence alignment, phylogenetic classification, and motif composition analysis revealed the remarkable sequential variation between, these two WRKYs. The tomato WRKY3 and WRKY4 clusters with Solanum pennellii showing the monophyletic origin and evolution from their wild homolog. The functional domain region responsible for sequence specific DNA-binding occupied in both proteins were modeled [using AtWRKY4 (PDB ID:1WJ2) and AtWRKY1 (PDBID:2AYD) as template protein structures] through homology modeling using Discovery Studio 3.0. The generated models were further evaluated for their accuracy and reliability based on qualitative and quantitative parameters. The modeled proteins were found to satisfy all the crucial energy parameters and showed acceptable Ramachandran statistics when compared to the experimentally resolved NMR solution structures and/or X-Ray diffracted crystal structures (templates). The superimposition of the functional WRKY domains from SlWRKY3 and SlWRKY4 revealed remarkable structural similarity. The sequence specific DNA binding for two WRKYs was explored through DNA-protein interaction using Hex Docking server. The interaction studies found that SlWRKY4 binds with the W-box DNA through WRKYGQK with Tyr408, Arg409, and Lys419 with the initial flanking sequences also get involved in binding. In contrast, the SlWRKY3 made interaction with RKYGQK along with the residues from zinc finger motifs. Protein-protein interactions studies were done using STRING version 10.0 to explore all the possible protein partners involved in associative functional interaction networks. The Gene ontology enrichment analysis revealed the functional dimension and characterized the identified WRKYs based on their functional annotation.
Keywords: DNA binding domain; DNA-protein docking; homology modeling; monophyletic origin; transcription factors.
Figures


References
-
- Arnott S., Campbell-Smith P. J., Chandrasekaran R. (1976). Atomic coordinates and molecular conformations for DNA-DNA, RNA-RNA, and DNA-RNA helices, in Handbook of Biochemistry and Molecular Biology, 3rd Edn, Vol. 2, Nucleic Acids, ed Fasman G. P. (Cleveland, OH: CRC Press; ), 411–422.
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
Research Materials
Miscellaneous