

De-identification of psychiatric intake records: Overview of 2016 CEGS N-GRID shared tasks Track 1
- PMID: 28614702
- PMCID: PMC5705537
- DOI: 10.1016/j.jbi.2017.06.011
De-identification of psychiatric intake records: Overview of 2016 CEGS N-GRID shared tasks Track 1
Abstract
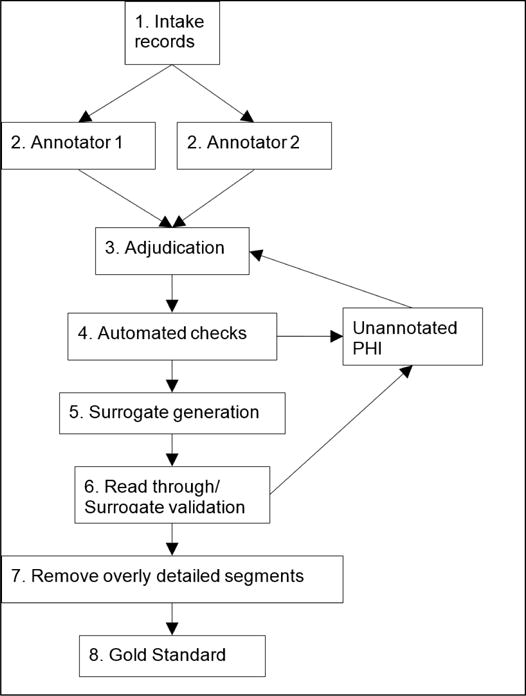
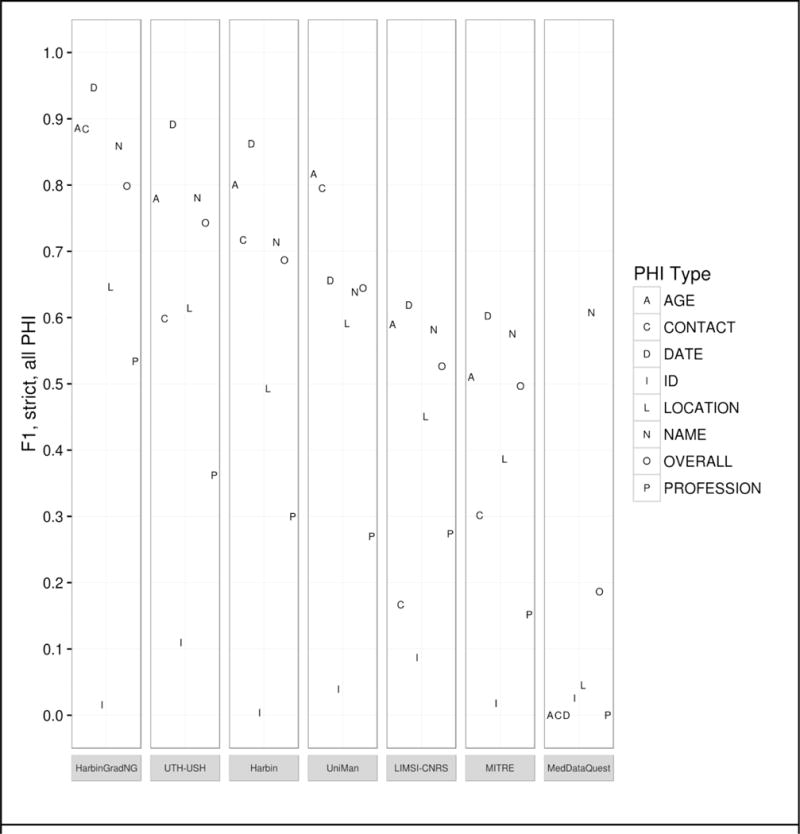
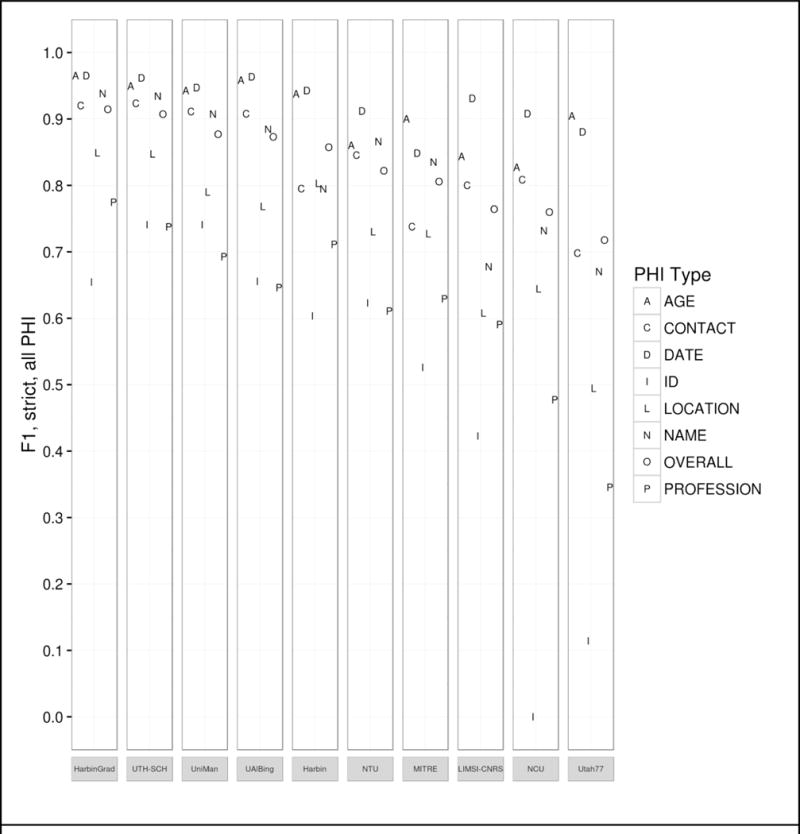
The 2016 CEGS N-GRID shared tasks for clinical records contained three tracks. Track 1 focused on de-identification of a new corpus of 1000 psychiatric intake records. This track tackled de-identification in two sub-tracks: Track 1.A was a "sight unseen" task, where nine teams ran existing de-identification systems, without any modifications or training, on 600 new records in order to gauge how well systems generalize to new data. The best-performing system for this track scored an F1 of 0.799. Track 1.B was a traditional Natural Language Processing (NLP) shared task on de-identification, where 15 teams had two months to train their systems on the new data, then test it on an unannotated test set. The best-performing system from this track scored an F1 of 0.914. The scores for Track 1.A show that unmodified existing systems do not generalize well to new data without the benefit of training data. The scores for Track 1.B are slightly lower than the 2014 de-identification shared task (which was almost identical to 2016 Track 1.B), indicating that these new psychiatric records pose a more difficult challenge to NLP systems. Overall, de-identification is still not a solved problem, though it is important to the future of clinical NLP.
Keywords: Clinical records; Machine learning; Natural language processing; Shared task.
Copyright © 2017 Elsevier Inc. All rights reserved.
Conflict of interest statement
Conflicts of Interest
The authors declare that there are no conflicts of interest.
Figures
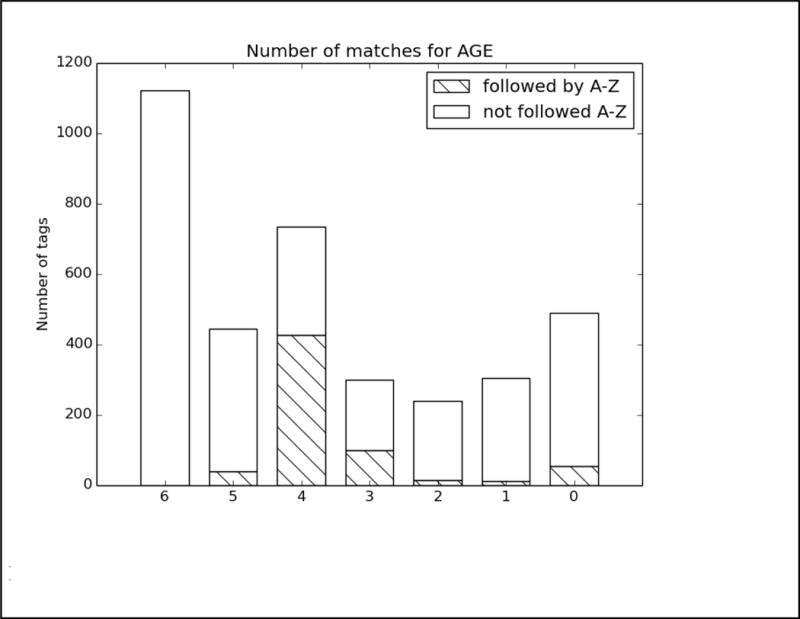
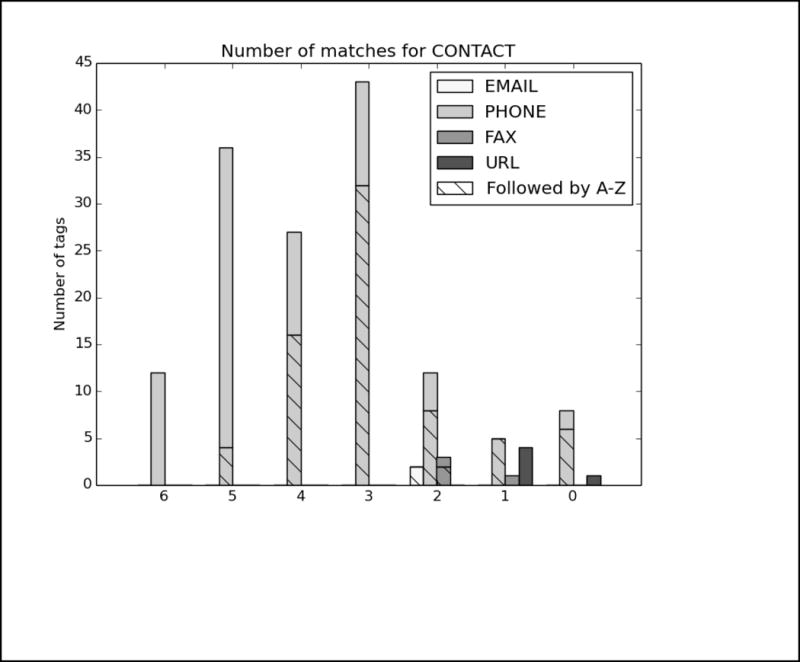
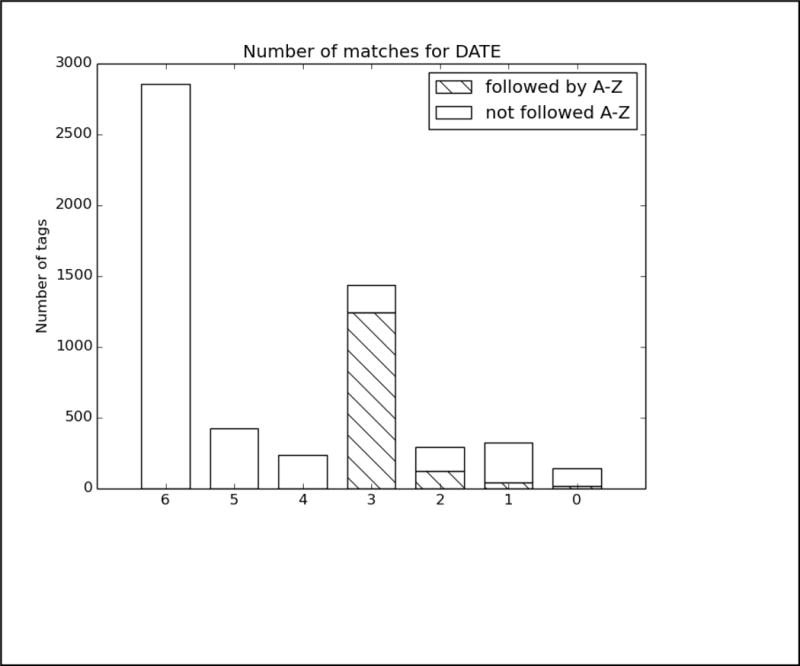
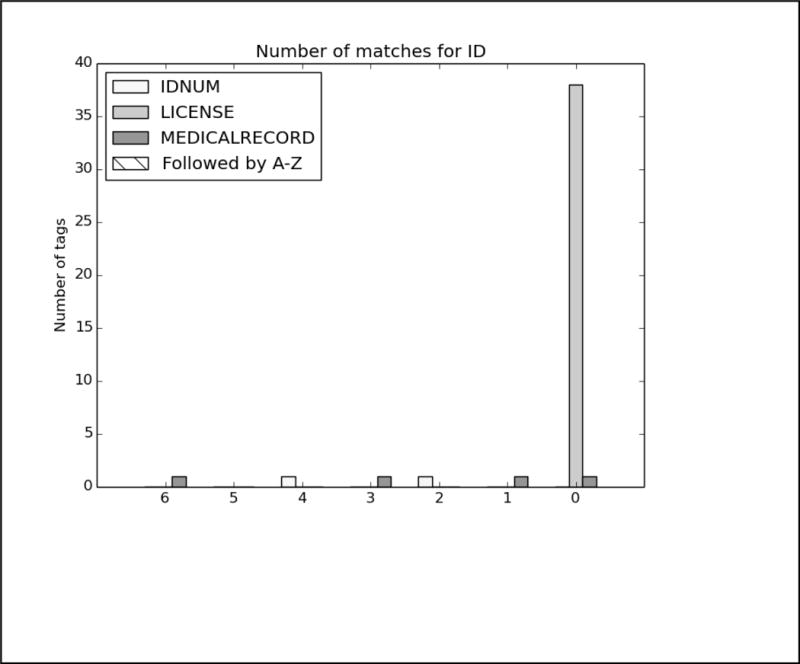
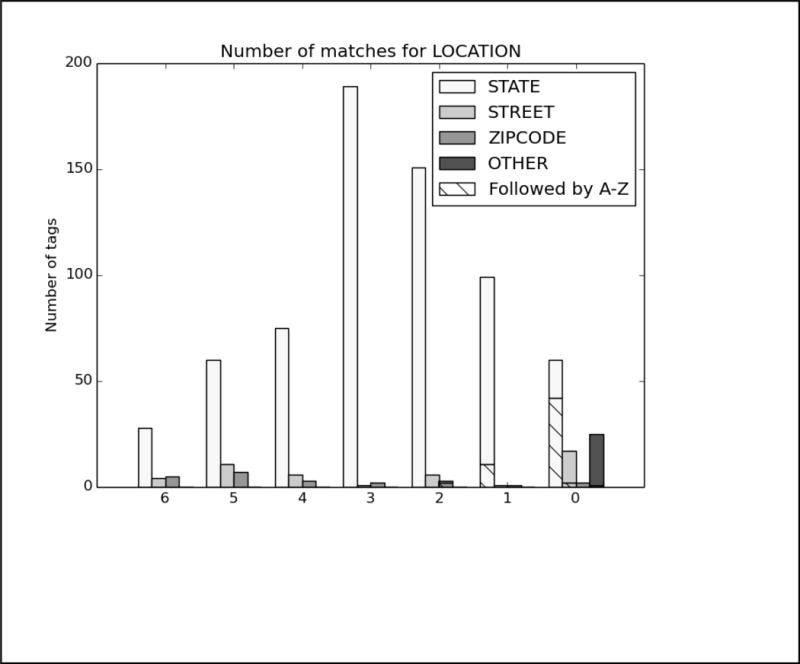
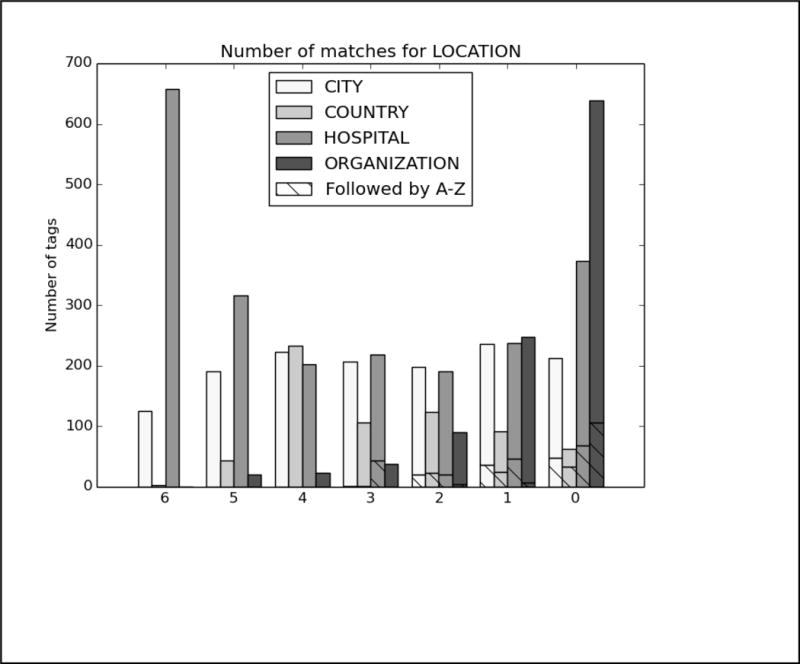
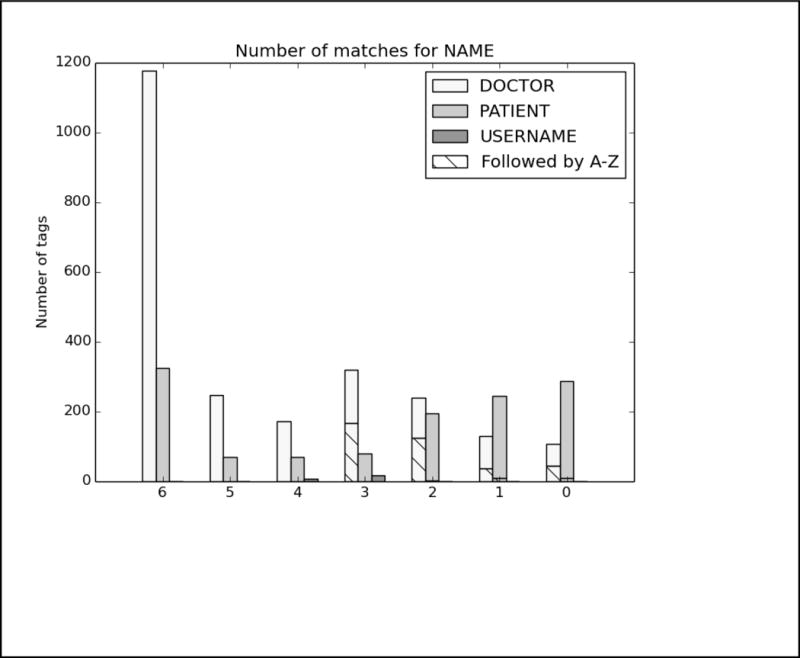
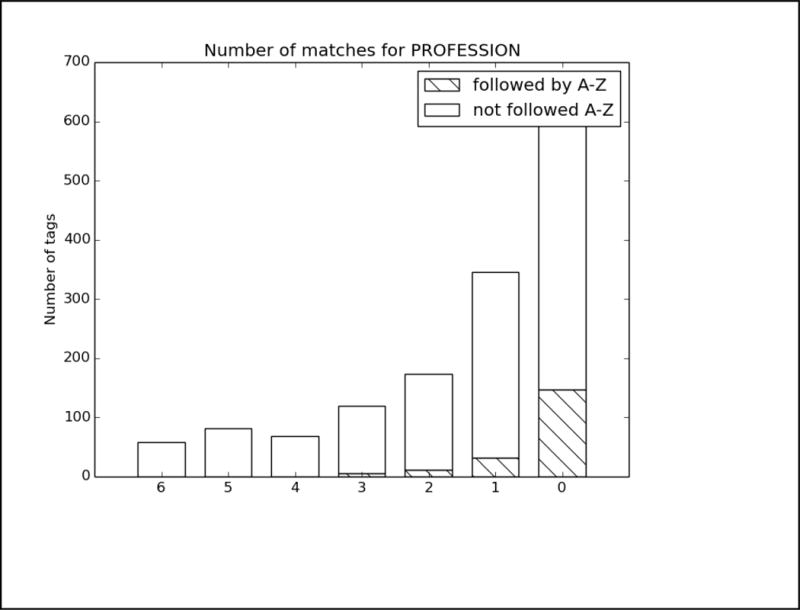
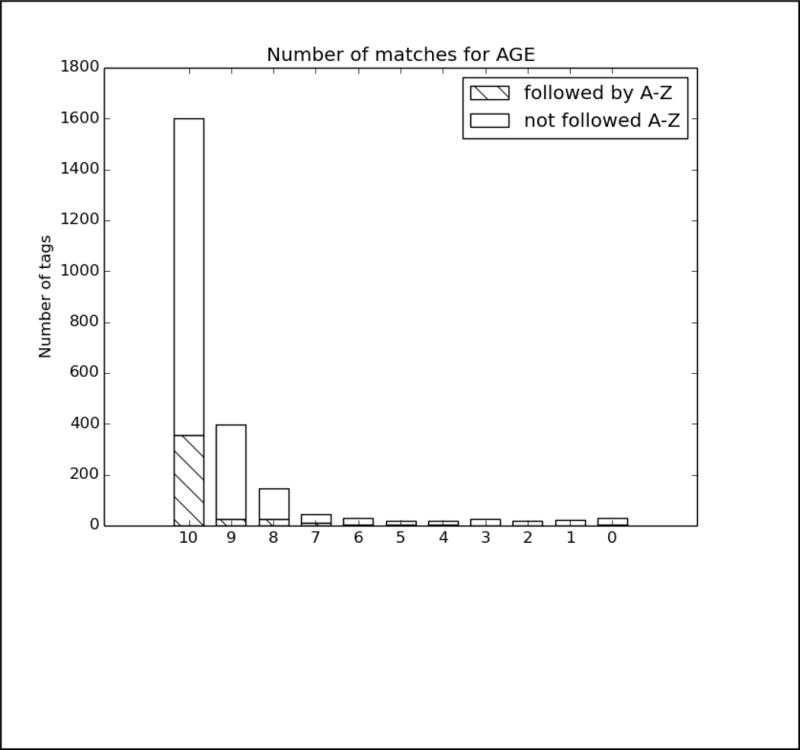
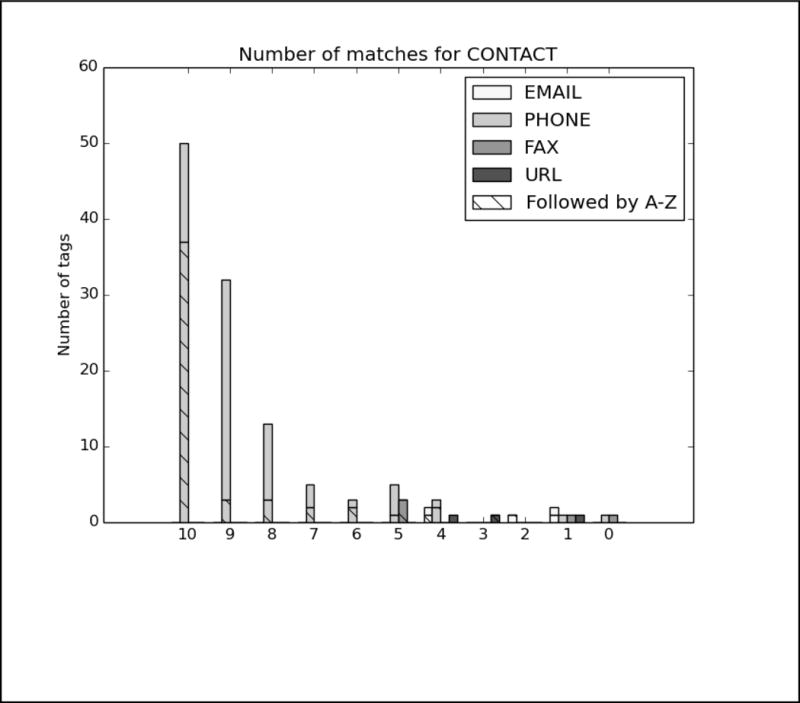
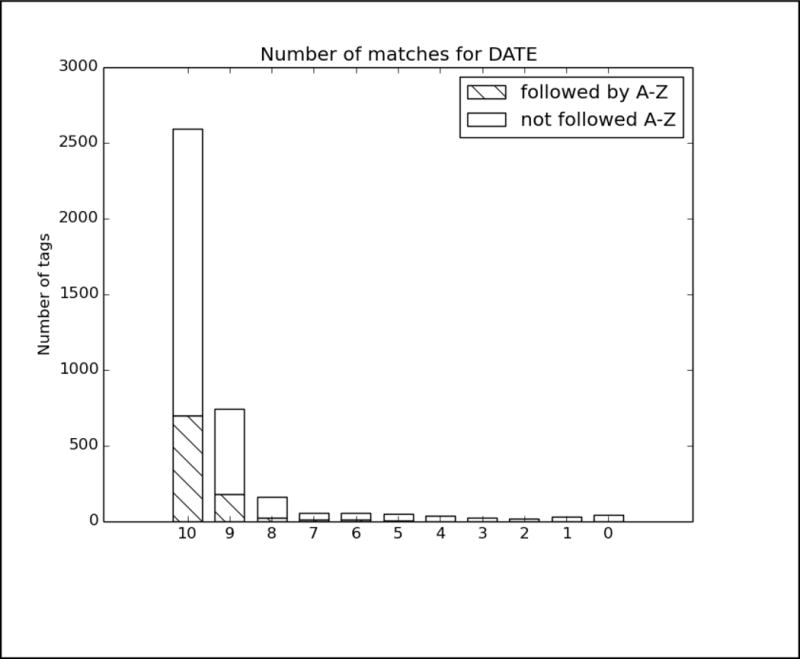
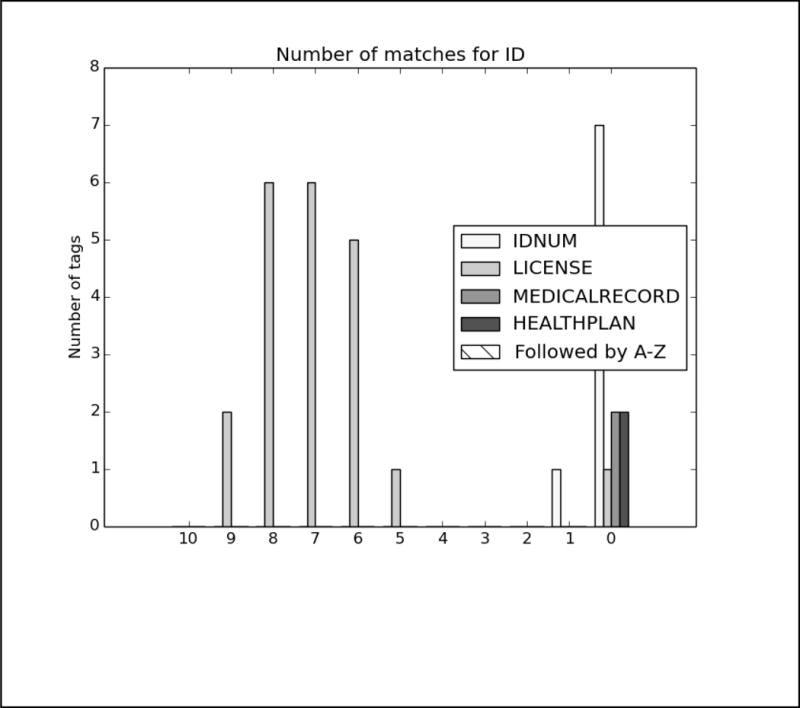

References
-
- AAlAbdulsalam Abdulrahman K, Meystre Stephane. Learning to De-Identify Clinical Text with Existing Hybrid Tools. Journal of Biomedical Informatics. n.d. this issue.
-
- Aberdeen John, Bayer Samuel, Clark Cheryl, Wellner Ben, Hirschman Lynette. De-Identification of Psychiatric Evaluation Notes with the MITRE Identification Scrubber Toolkit. Proceedings of the 2016 CEGS/N-GRID Shared Task in Clinical NLP 2016
-
- Carrell David, Malin Bradley, Aberdeen John, Bayer Samuel, Clark Cheryl, Wellner Ben, Hirschman Lynette. Hiding in Plain Sight: Use of Realistic Surrogates to Reduce Exposure of Protected Health Information in Clinical Text. Journal of the American Medical Informatics Association: JAMIA. 2013;20(2):342–48. - PMC - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
Miscellaneous
