

Autoreject: Automated artifact rejection for MEG and EEG data
- PMID: 28645840
- PMCID: PMC7243972
- DOI: 10.1016/j.neuroimage.2017.06.030
Autoreject: Automated artifact rejection for MEG and EEG data
Abstract
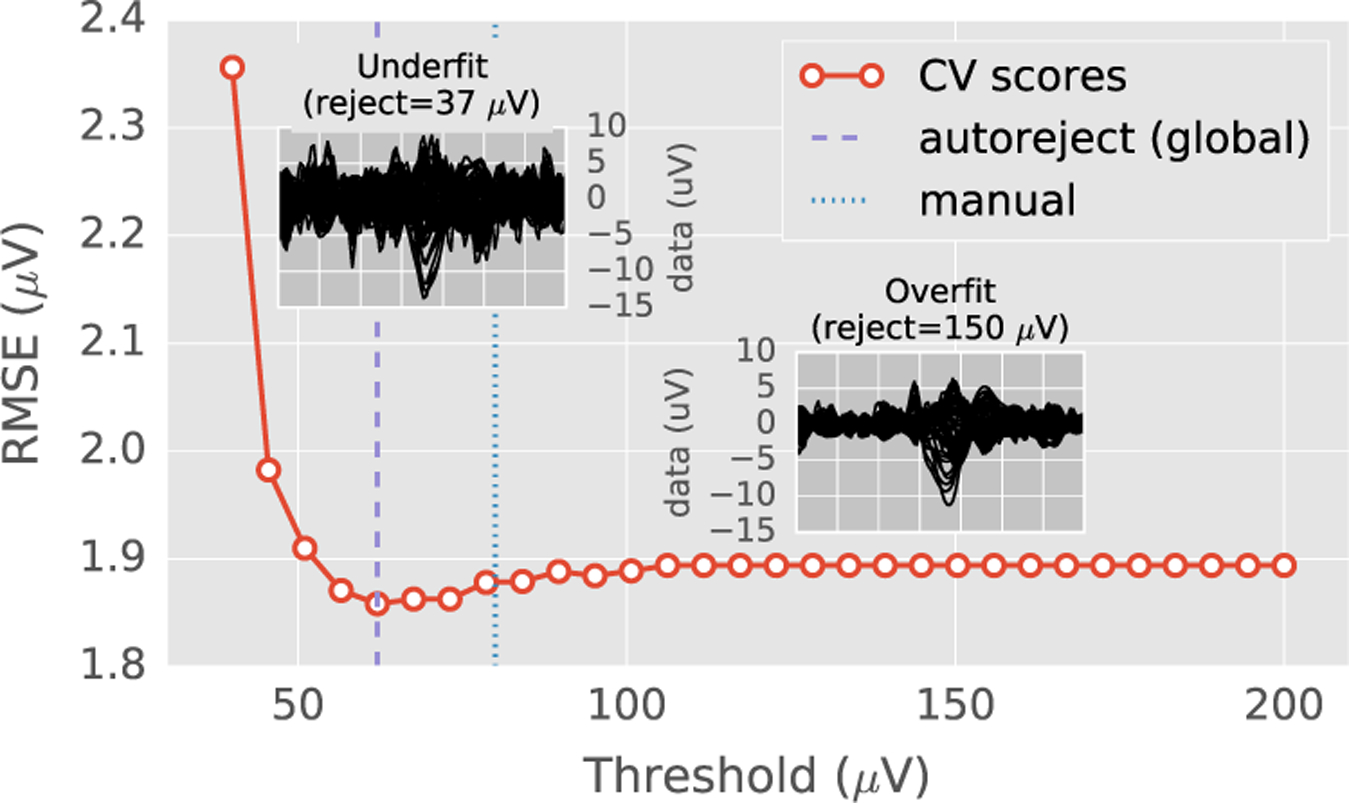
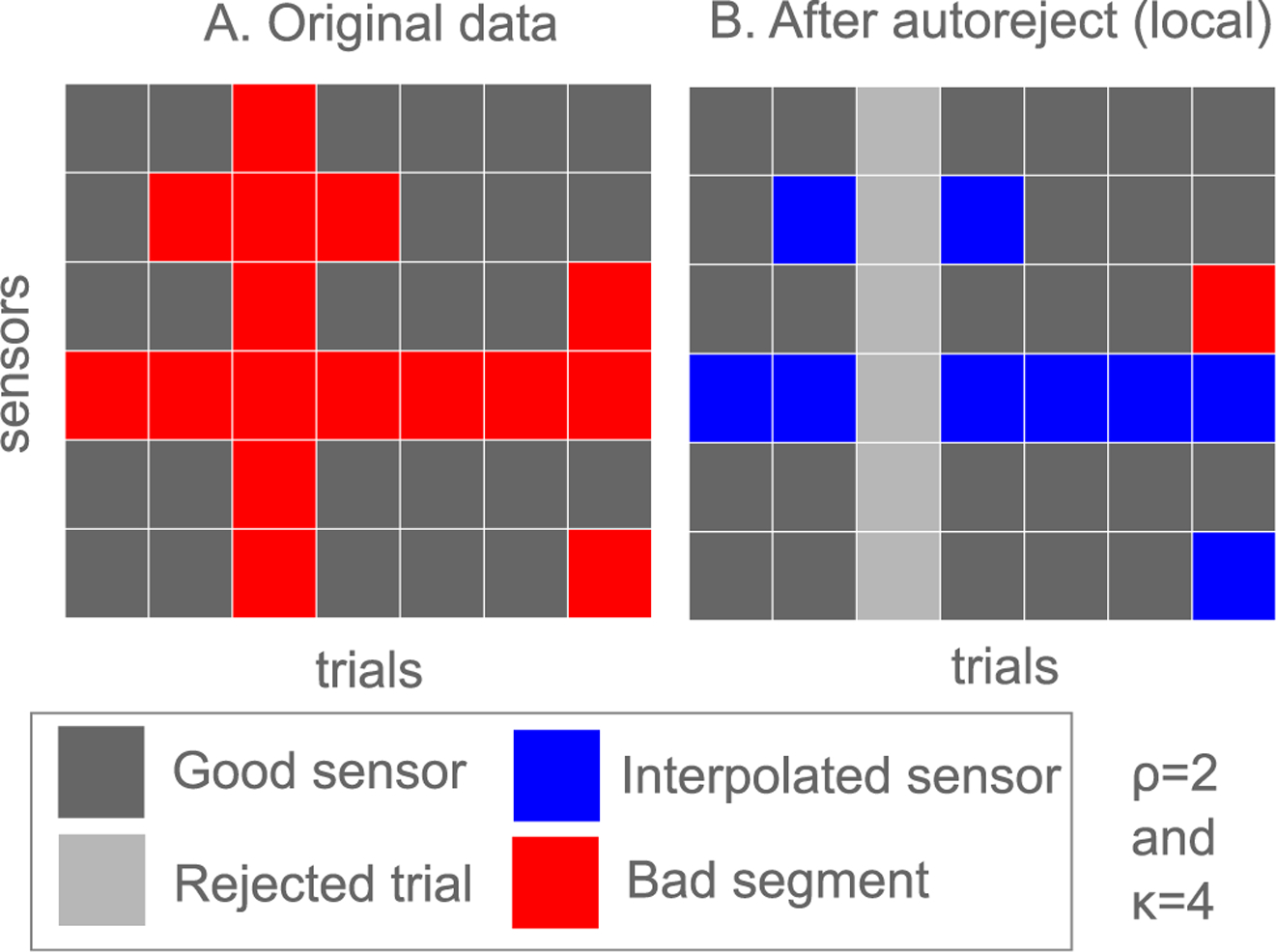
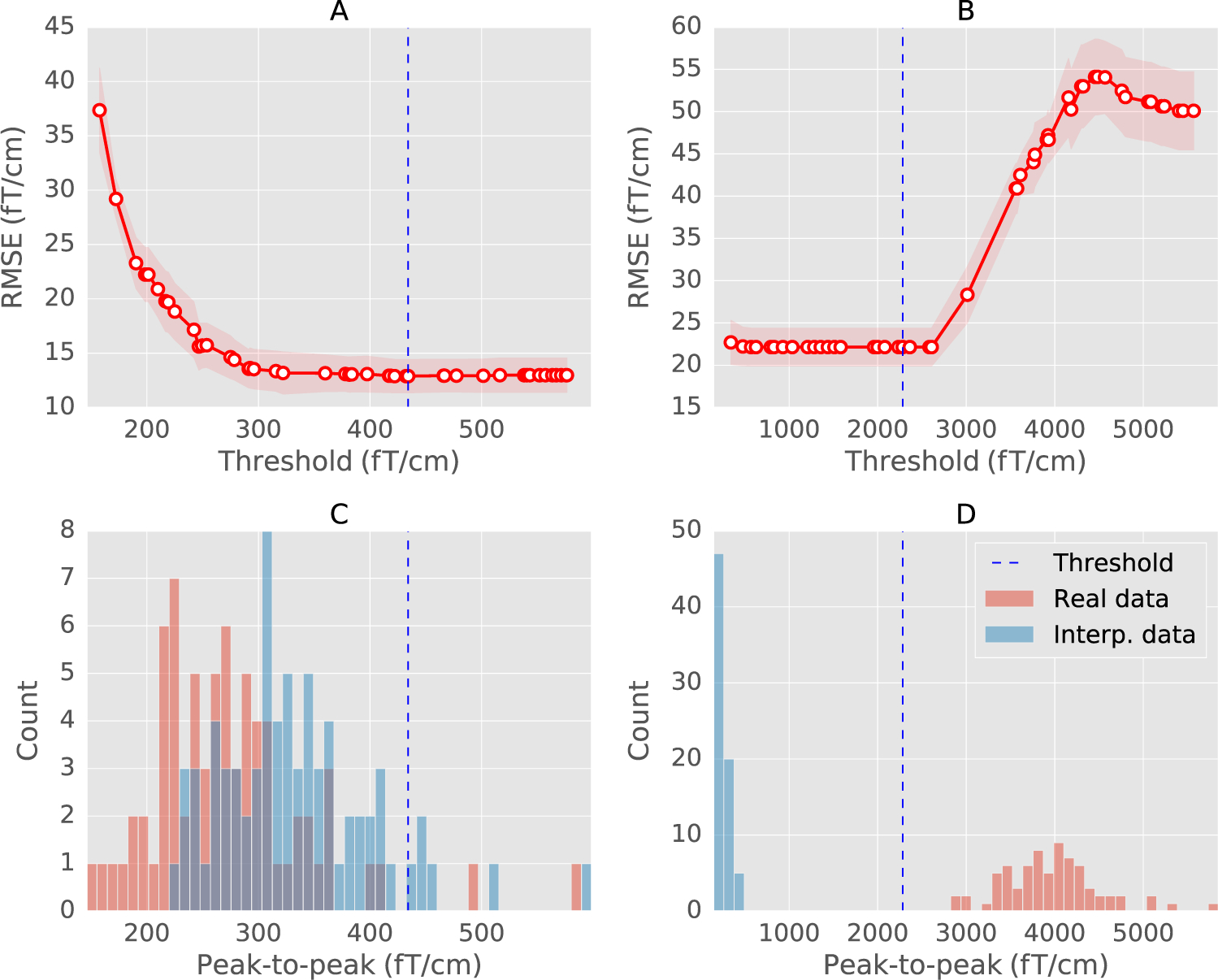
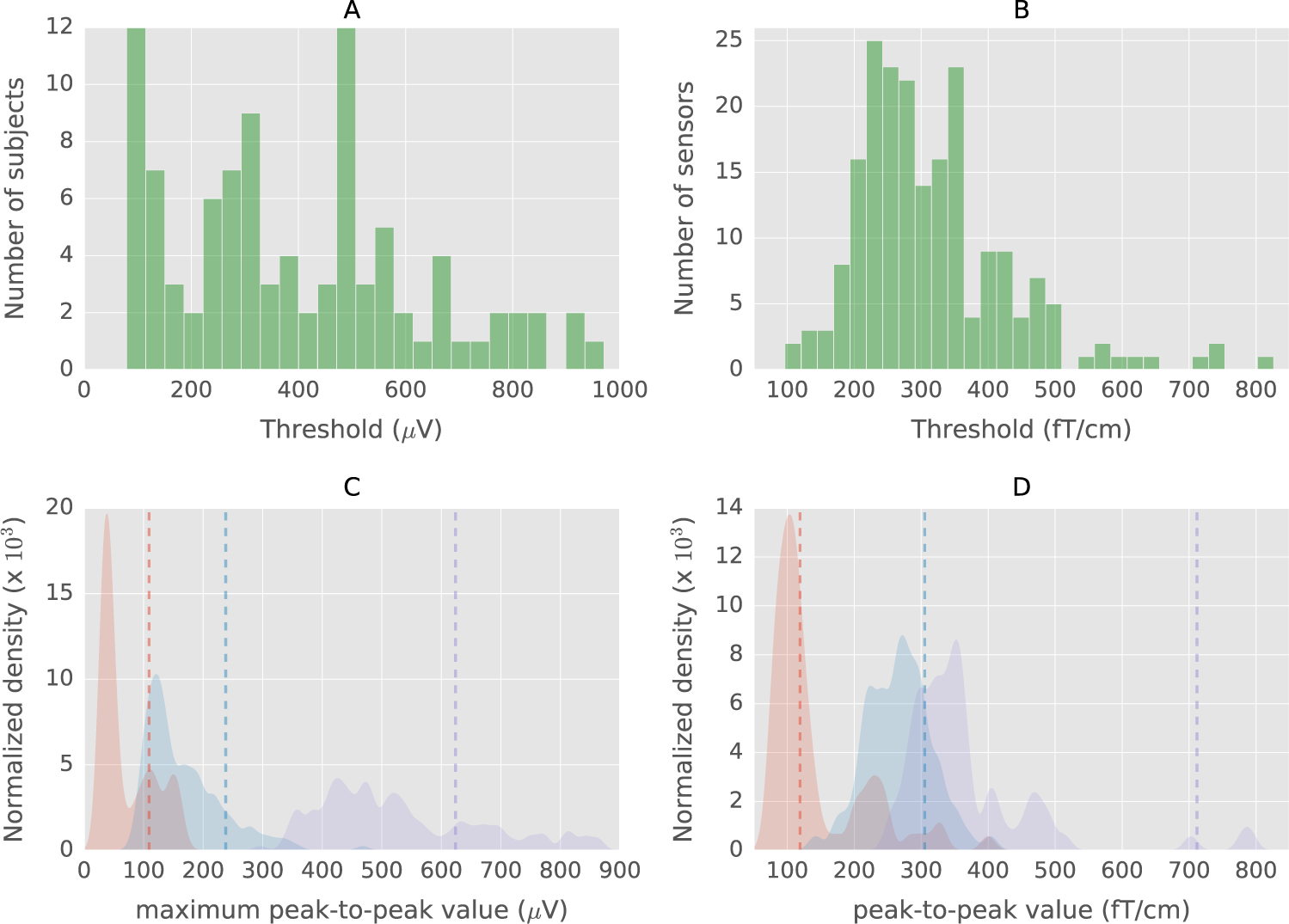
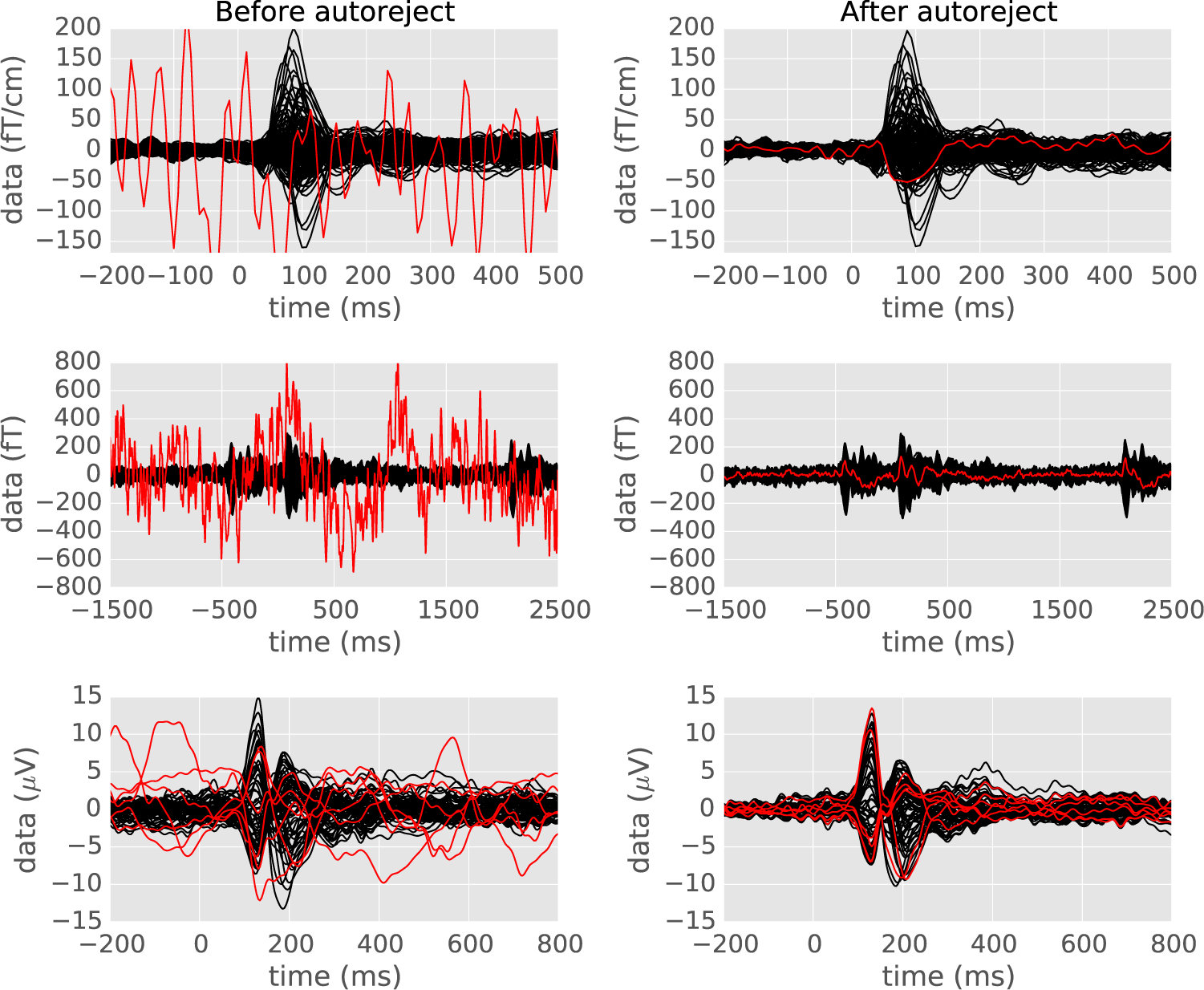
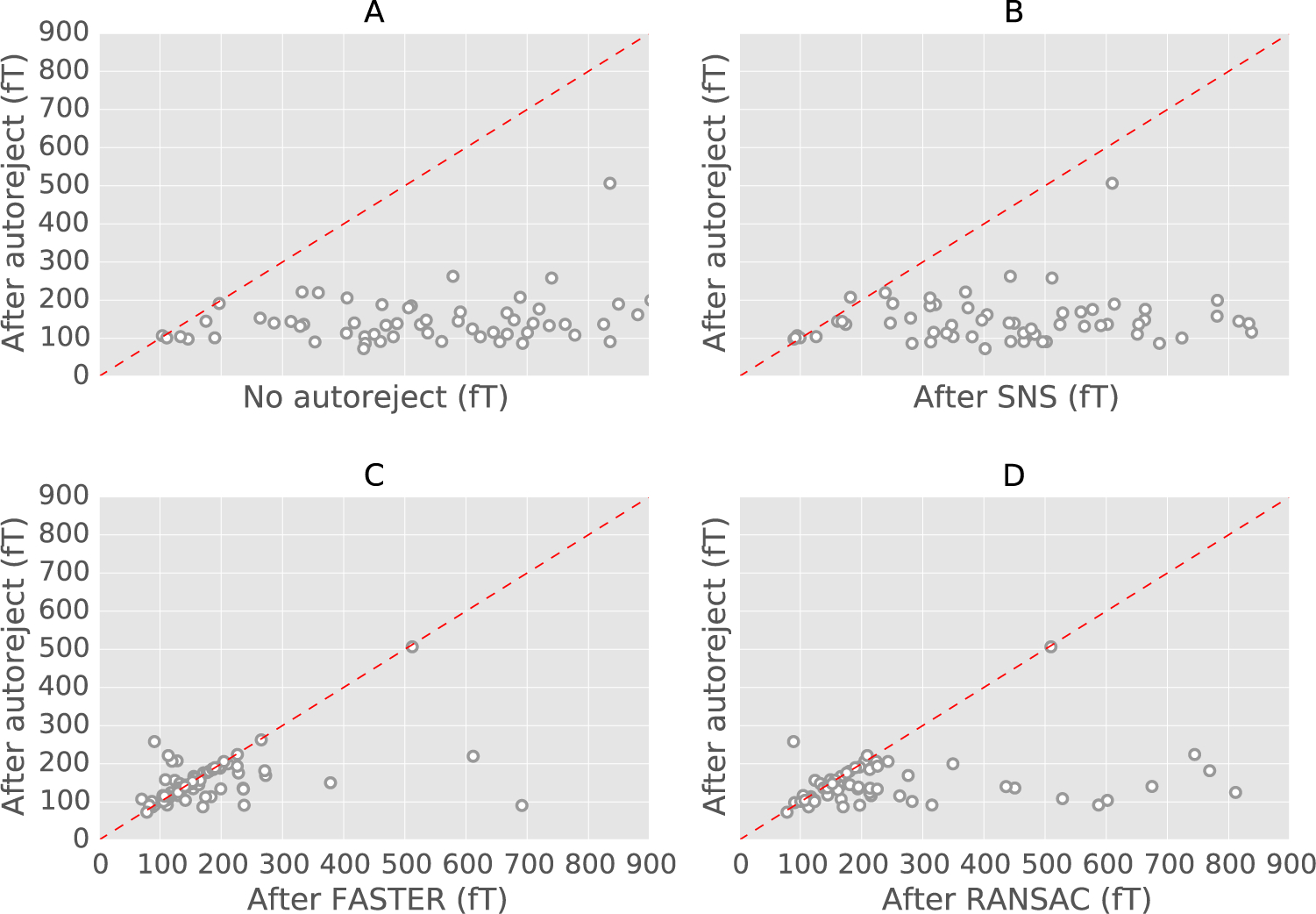
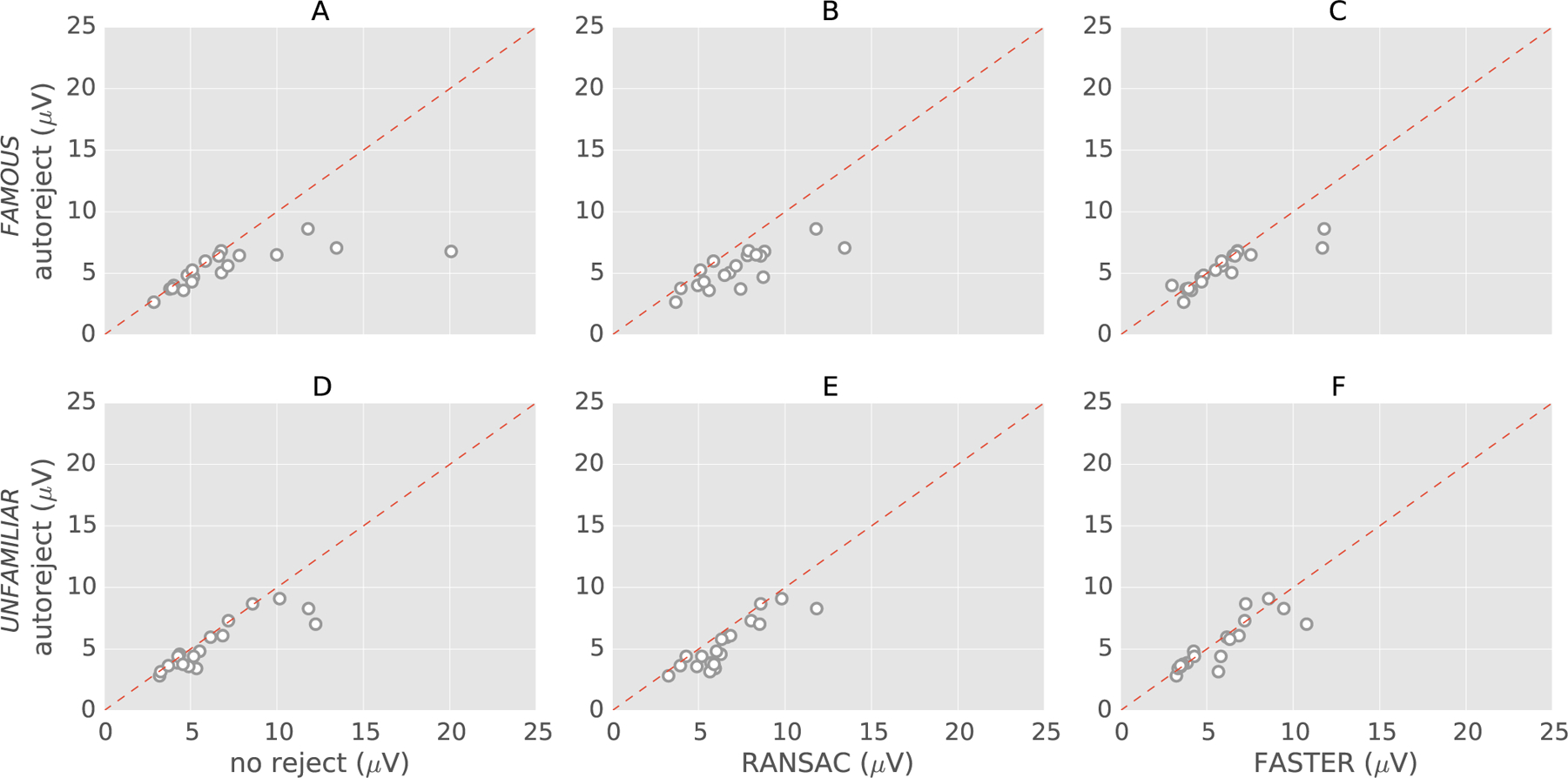
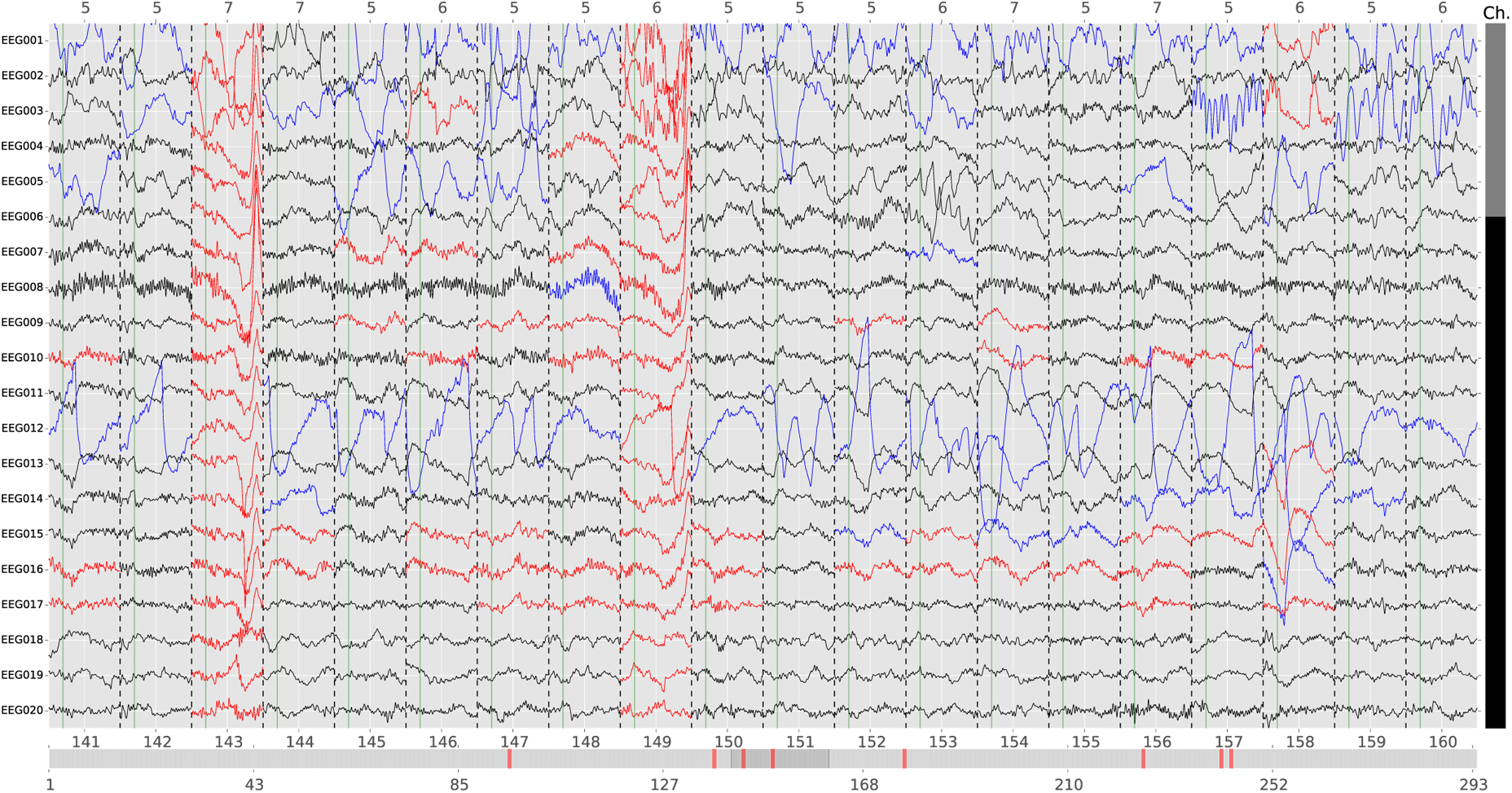
We present an automated algorithm for unified rejection and repair of bad trials in magnetoencephalography (MEG) and electroencephalography (EEG) signals. Our method capitalizes on cross-validation in conjunction with a robust evaluation metric to estimate the optimal peak-to-peak threshold - a quantity commonly used for identifying bad trials in M/EEG. This approach is then extended to a more sophisticated algorithm which estimates this threshold for each sensor yielding trial-wise bad sensors. Depending on the number of bad sensors, the trial is then repaired by interpolation or by excluding it from subsequent analysis. All steps of the algorithm are fully automated thus lending itself to the name Autoreject. In order to assess the practical significance of the algorithm, we conducted extensive validation and comparisons with state-of-the-art methods on four public datasets containing MEG and EEG recordings from more than 200 subjects. The comparisons include purely qualitative efforts as well as quantitatively benchmarking against human supervised and semi-automated preprocessing pipelines. The algorithm allowed us to automate the preprocessing of MEG data from the Human Connectome Project (HCP) going up to the computation of the evoked responses. The automated nature of our method minimizes the burden of human inspection, hence supporting scalability and reliability demanded by data analysis in modern neuroscience.
Keywords: Automated analysis; Cross-validation; Electroencephalogram (EEG); Human Connectome Project (HCP); Magnetoencephalography (MEG); Preprocessing; Statistical learning.
Copyright © 2017 Elsevier Inc. All rights reserved.
Figures
References
-
- Barachant A, Andreev A, Congedo M, 2013. The Riemannian Potato: an automatic and adaptive artifact detection method for online experiments using Riemannian geometry. in: TOBI Workshop lV, pp. 19–20.
-
- Basirat A, Dehaene S, Dehaene-Lambertz G, 2014. A hierarchy of cortical responses to sequence violations in three-month-old infants. Cognition 132, 137–150. - PubMed
-
- Bergstra JS, Bardenet R, Bengio Y, Kégl B, 2011. Algorithms for hyper-parameter optimization. in: Advances in Neural Information Processing Systems, pp. 2546–2554.
-
- Bigdely-Shamlo N, Kreutz-Delgado K, Robbins K, Miyakoshi M, Westerfield M, Bel-Bahar T, Kothe C, Hsi J, Makeig S, 2015. Hierarchical event descriptor (HED) tags for analysis of event-related EEG studies. in: Global Conference on Signal and Information Processing (GlobalSIP), IEEE, pp. 1–4.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Research Materials
Miscellaneous
