

Auto-Context Convolutional Neural Network (Auto-Net) for Brain Extraction in Magnetic Resonance Imaging
- PMID: 28678704
- PMCID: PMC5715475
- DOI: 10.1109/TMI.2017.2721362
Auto-Context Convolutional Neural Network (Auto-Net) for Brain Extraction in Magnetic Resonance Imaging
Abstract
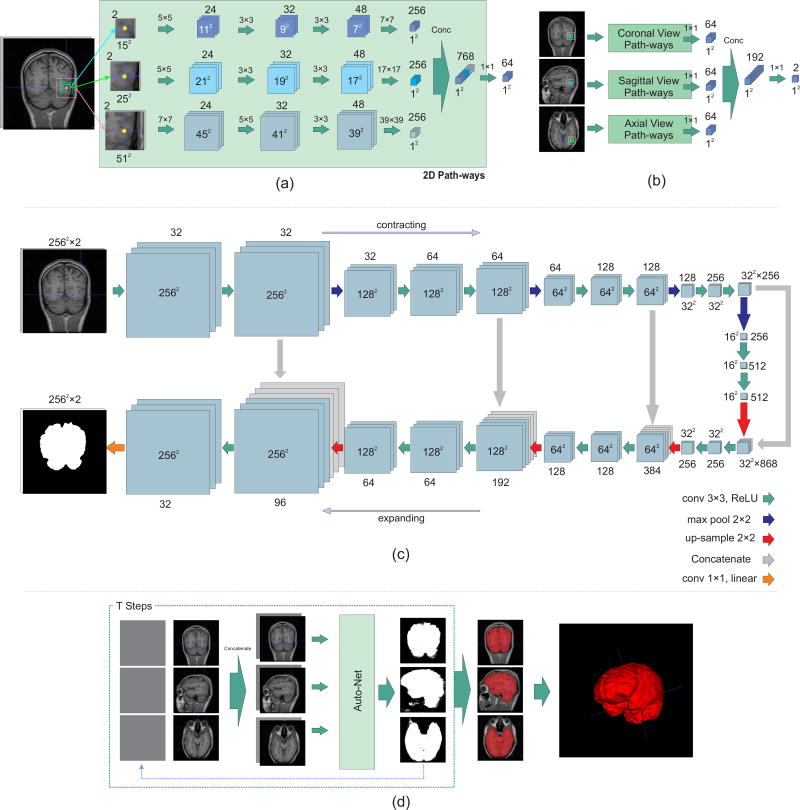
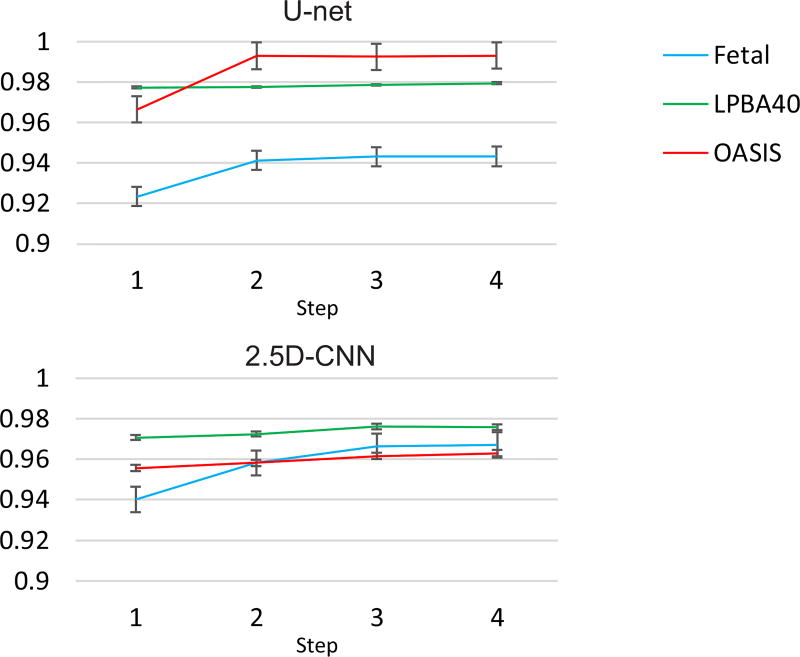
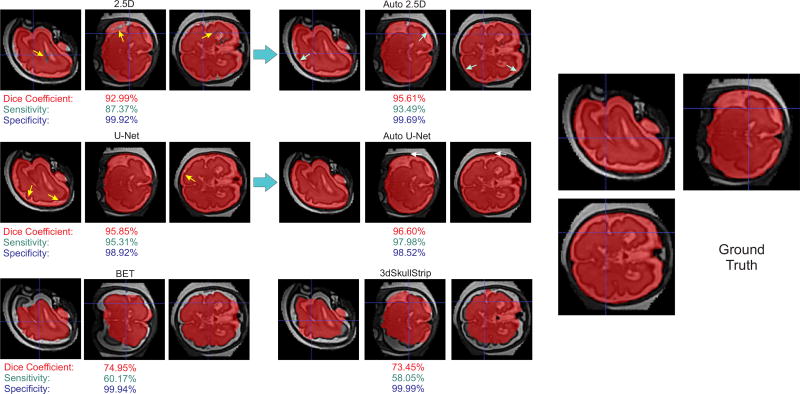
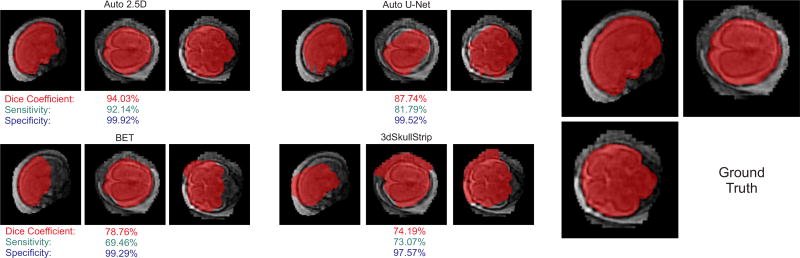
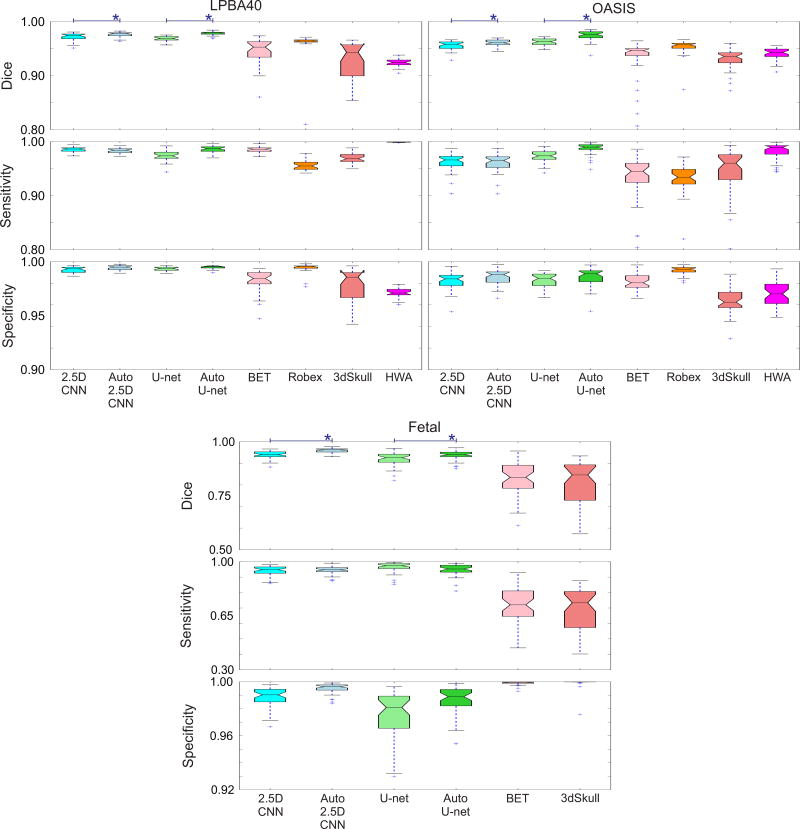
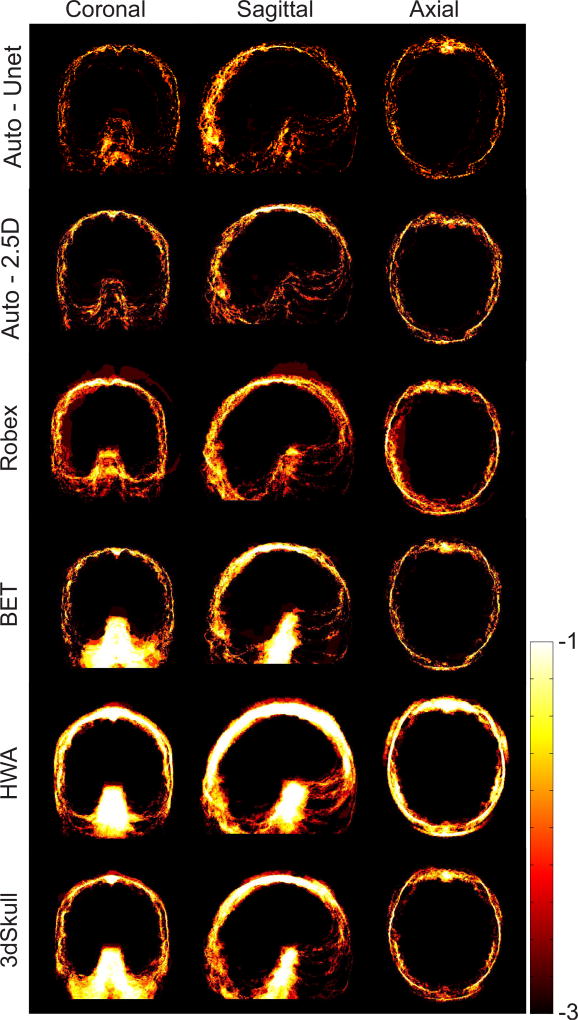
Brain extraction or whole brain segmentation is an important first step in many of the neuroimage analysis pipelines. The accuracy and the robustness of brain extraction, therefore, are crucial for the accuracy of the entire brain analysis process. The state-of-the-art brain extraction techniques rely heavily on the accuracy of alignment or registration between brain atlases and query brain anatomy, and/or make assumptions about the image geometry, and therefore have limited success when these assumptions do not hold or image registration fails. With the aim of designing an accurate, learning-based, geometry-independent, and registration-free brain extraction tool, in this paper, we present a technique based on an auto-context convolutional neural network (CNN), in which intrinsic local and global image features are learned through 2-D patches of different window sizes. We consider two different architectures: 1) a voxelwise approach based on three parallel 2-D convolutional pathways for three different directions (axial, coronal, and sagittal) that implicitly learn 3-D image information without the need for computationally expensive 3-D convolutions and 2) a fully convolutional network based on the U-net architecture. Posterior probability maps generated by the networks are used iteratively as context information along with the original image patches to learn the local shape and connectedness of the brain to extract it from non-brain tissue. The brain extraction results we have obtained from our CNNs are superior to the recently reported results in the literature on two publicly available benchmark data sets, namely, LPBA40 and OASIS, in which we obtained the Dice overlap coefficients of 97.73% and 97.62%, respectively. Significant improvement was achieved via our auto-context algorithm. Furthermore, we evaluated the performance of our algorithm in the challenging problem of extracting arbitrarily oriented fetal brains in reconstructed fetal brain magnetic resonance imaging (MRI) data sets. In this application, our voxelwise auto-context CNN performed much better than the other methods (Dice coefficient: 95.97%), where the other methods performed poorly due to the non-standard orientation and geometry of the fetal brain in MRI. Through training, our method can provide accurate brain extraction in challenging applications. This, in turn, may reduce the problems associated with image registration in segmentation tasks.
Figures
References
-
- Makropoulos A, Gousias IS, Ledig C, Aljabar P, Serag A, Hajnal JV, Edwards AD, Counsell SJ, Rueckert D. Automatic whole brain MRI segmentation of the developing neonatal brain. IEEE transactions on medical imaging. 2014;33(9):1818–1831. - PubMed
-
- MacDonald D, Kabani N, Avis D, Evans AC. Automated 3D extraction of inner and outer surfaces of cerebral cortex from MRI. NeuroImage. 2000;12(3):340–356. - PubMed
-
- Clouchoux C, Kudelski D, Gholipour A, Warfield SK, Viseur S, Bouyssi-Kobar M, Mari J-L, Evans AC, Du Plessis AJ, Limperopoulos C. Quantitative in vivo MRI measurement of cortical development in the fetus. Brain Structure and Function. 2012;217(1):127–139. - PubMed
-
- de Brebisson A, Montana G. Deep neural networks for anatomical brain segmentation; Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops; 2015. pp. 20–28.
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
