

CRISPR-Cas encoding of a digital movie into the genomes of a population of living bacteria
- PMID: 28700573
- PMCID: PMC5842791
- DOI: 10.1038/nature23017
CRISPR-Cas encoding of a digital movie into the genomes of a population of living bacteria
Abstract
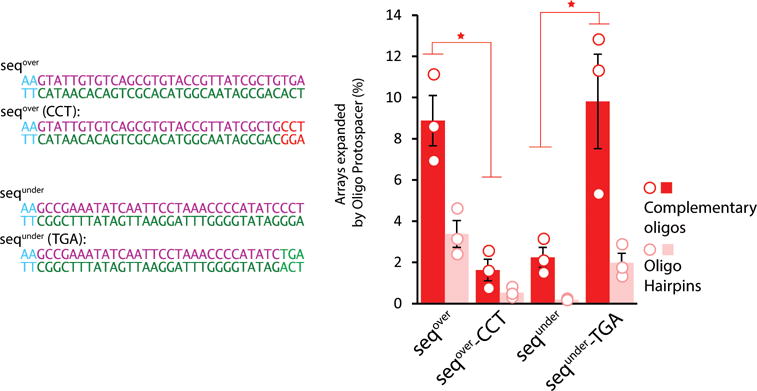
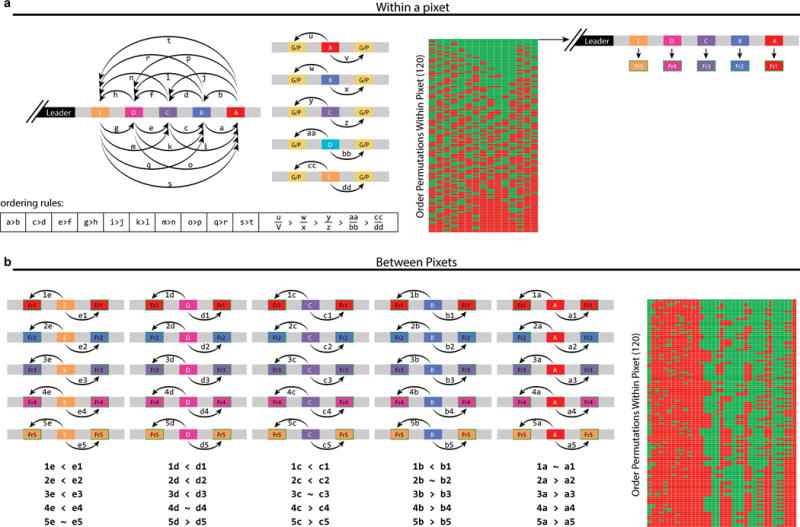
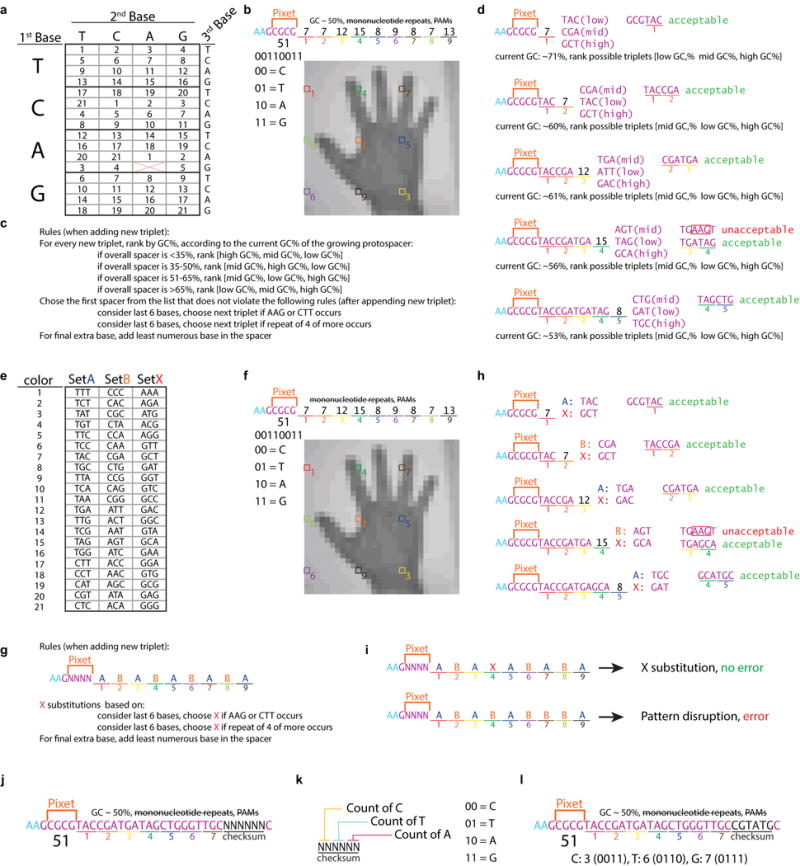
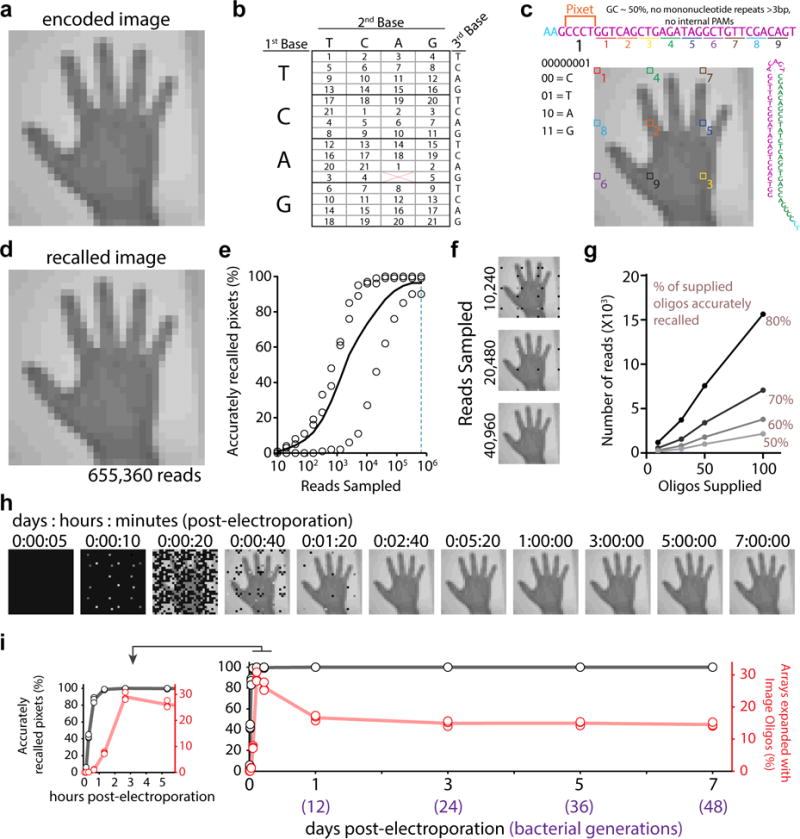
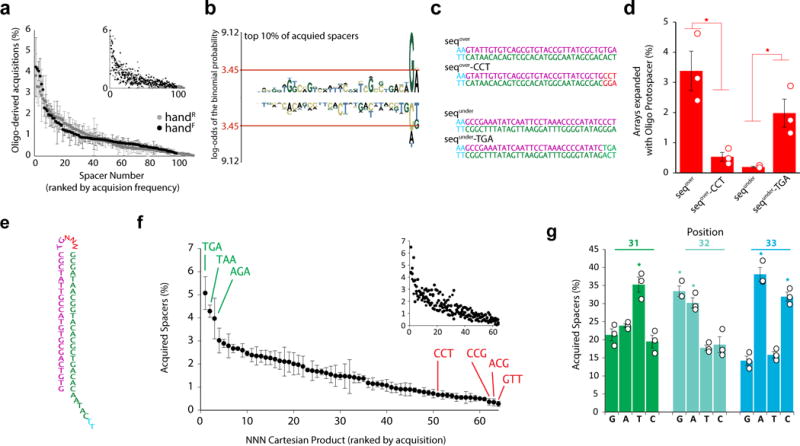
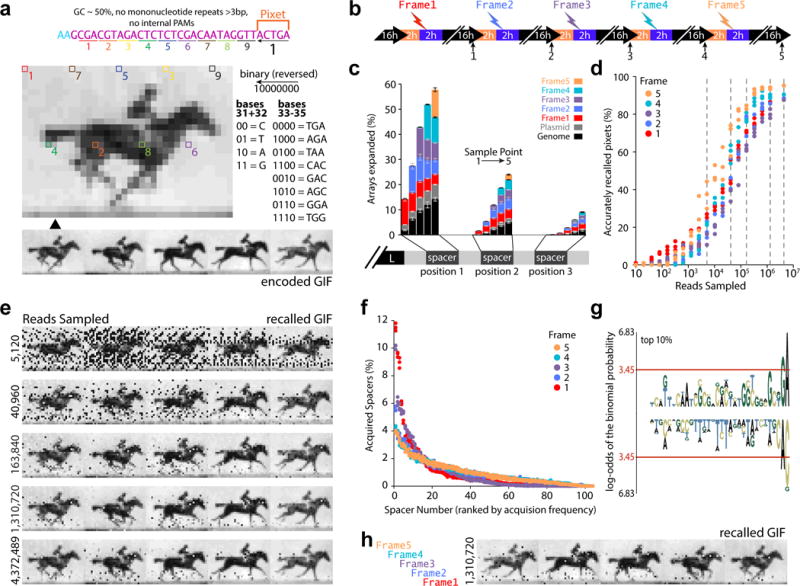
DNA is an excellent medium for archiving data. Recent efforts have illustrated the potential for information storage in DNA using synthesized oligonucleotides assembled in vitro. A relatively unexplored avenue of information storage in DNA is the ability to write information into the genome of a living cell by the addition of nucleotides over time. Using the Cas1-Cas2 integrase, the CRISPR-Cas microbial immune system stores the nucleotide content of invading viruses to confer adaptive immunity. When harnessed, this system has the potential to write arbitrary information into the genome. Here we use the CRISPR-Cas system to encode the pixel values of black and white images and a short movie into the genomes of a population of living bacteria. In doing so, we push the technical limits of this information storage system and optimize strategies to minimize those limitations. We also uncover underlying principles of the CRISPR-Cas adaptation system, including sequence determinants of spacer acquisition that are relevant for understanding both the basic biology of bacterial adaptation and its technological applications. This work demonstrates that this system can capture and stably store practical amounts of real data within the genomes of populations of living cells.
Conflict of interest statement
S.L.S. J.N, J.D.M., and G.M.C. are inventors on a provisional patent (62/296,812) filed by the President and Fellows of Harvard College that covers the work in this manuscript. A complete accounting of the financial interests of G.M.C. is listed at:
Figures
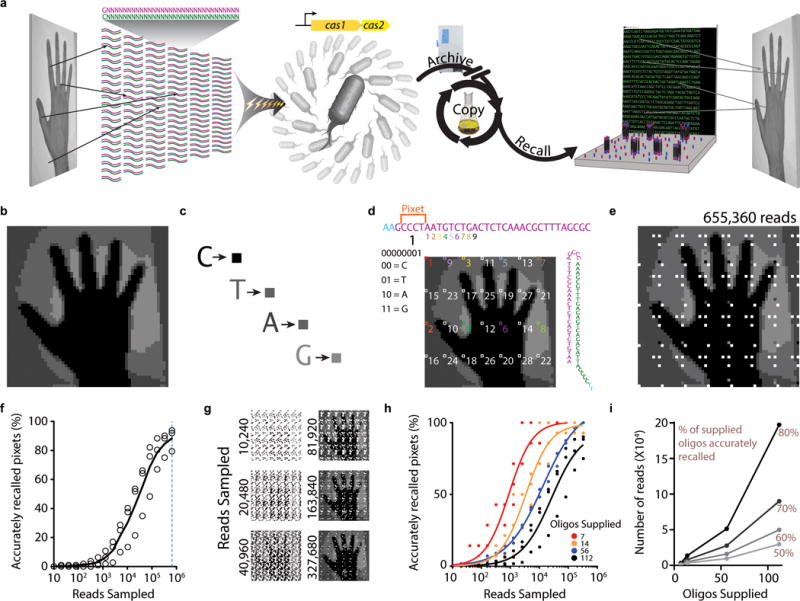
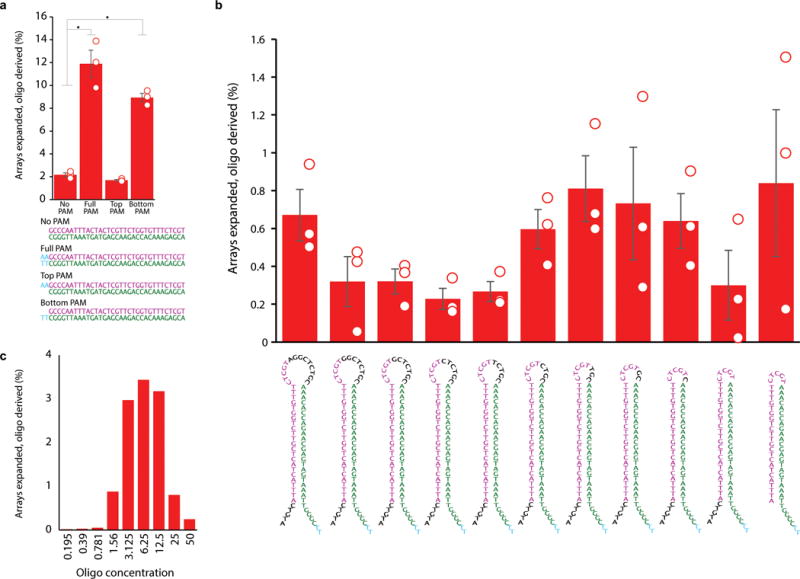
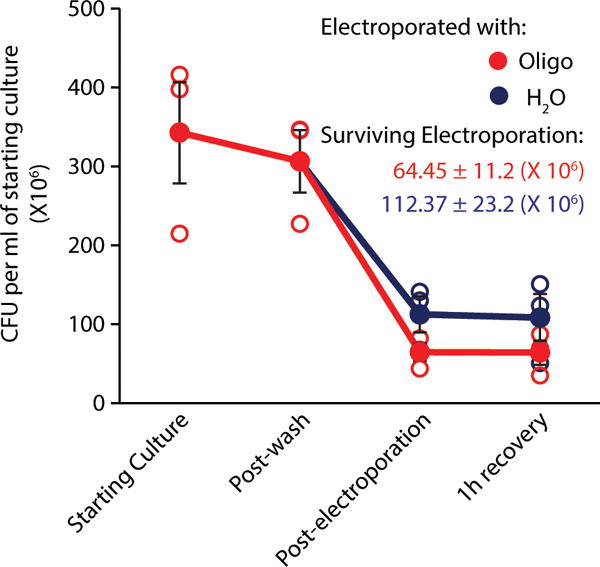
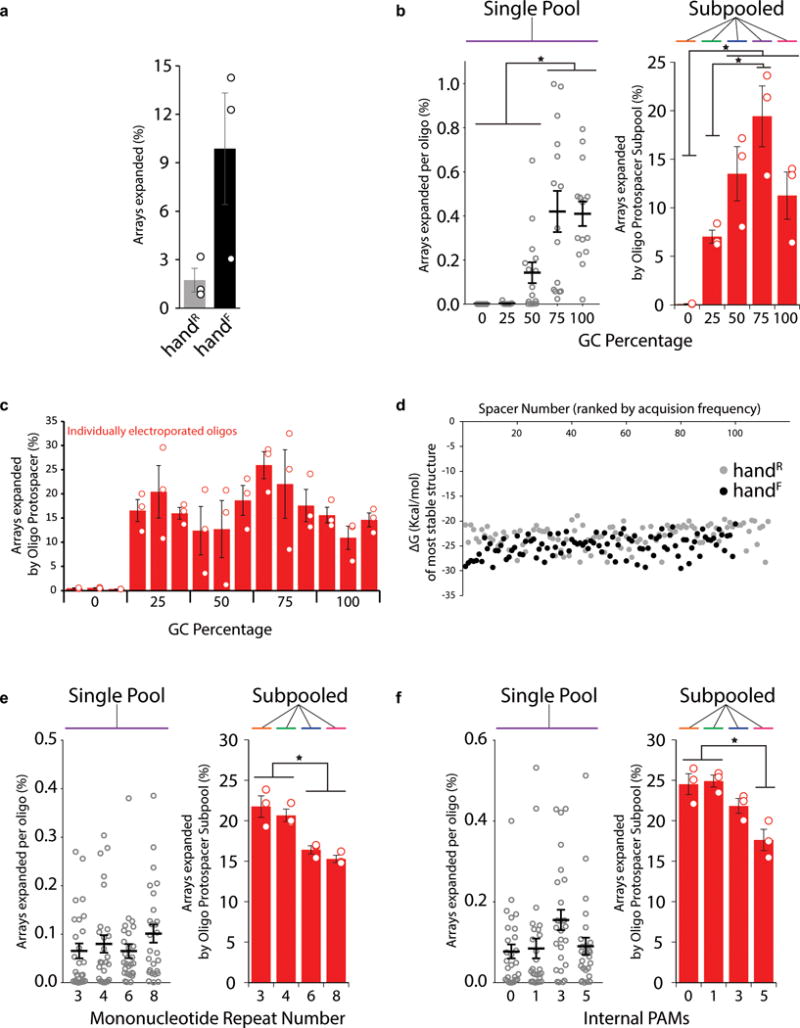

Comment in
-
Commentary: CRISPR-Cas Encoding of a Digital Movie into the Genomes of a Population of Living Bacteria.Front Bioeng Biotechnol. 2017 Sep 27;5:57. doi: 10.3389/fbioe.2017.00057. eCollection 2017. Front Bioeng Biotechnol. 2017. PMID: 29021981 Free PMC article. No abstract available.
References
-
- Adleman LM. Molecular computation of solutions to combinatorial problems. Science. 1994;266:1021–1024. - PubMed
