

Quicksilver: Fast predictive image registration - A deep learning approach
- PMID: 28705497
- PMCID: PMC6036629
- DOI: 10.1016/j.neuroimage.2017.07.008
Quicksilver: Fast predictive image registration - A deep learning approach
Abstract
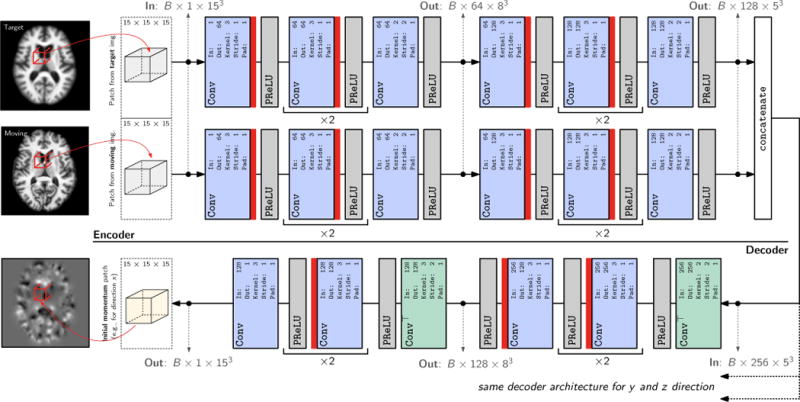
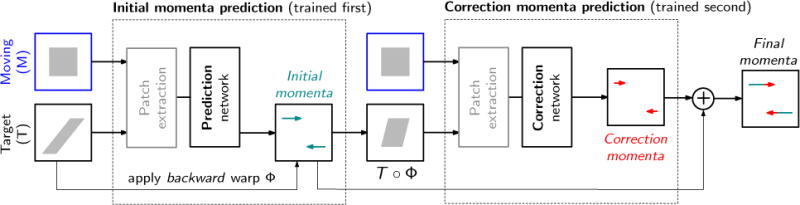
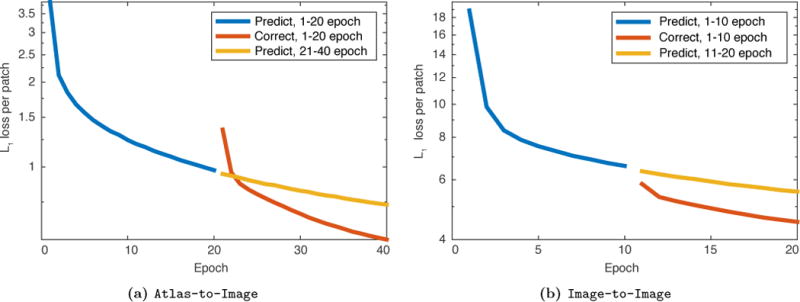
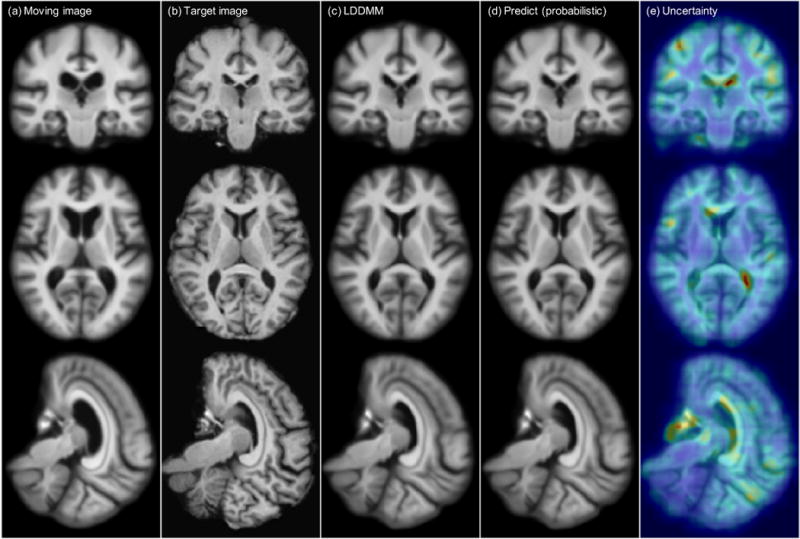
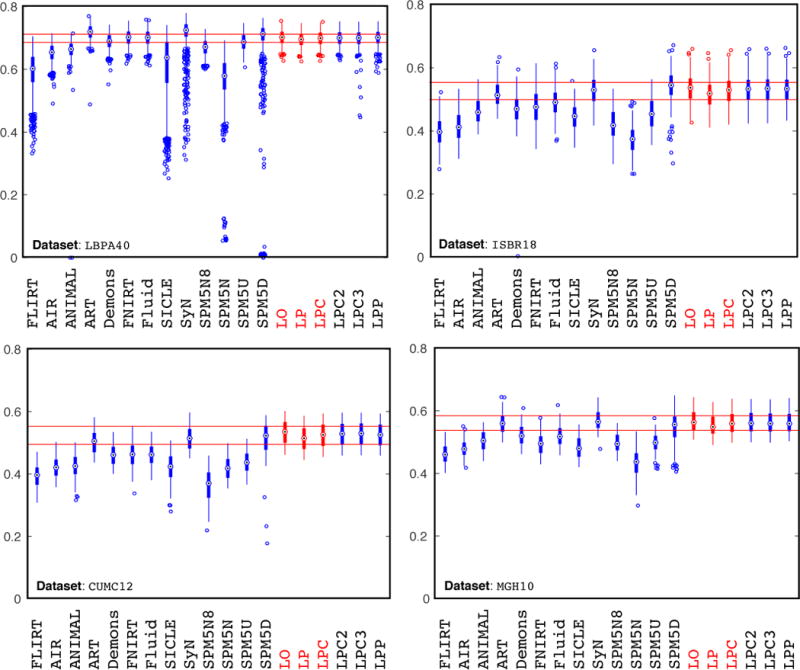
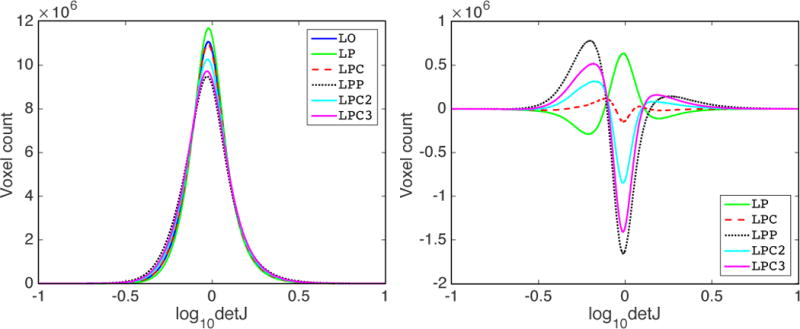
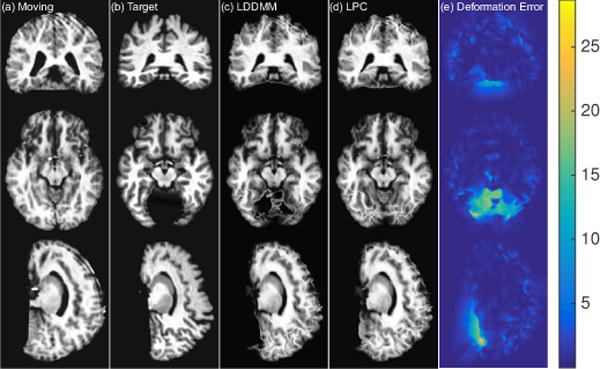
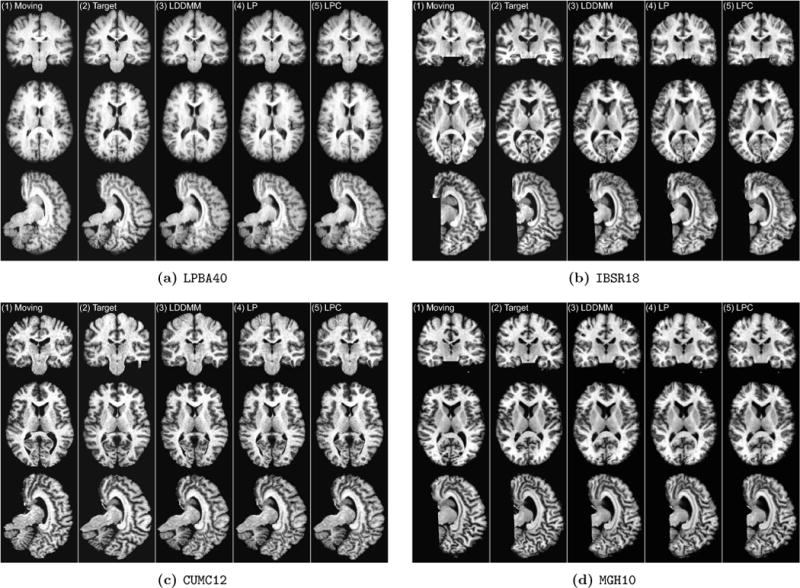
This paper introduces Quicksilver, a fast deformable image registration method. Quicksilver registration for image-pairs works by patch-wise prediction of a deformation model based directly on image appearance. A deep encoder-decoder network is used as the prediction model. While the prediction strategy is general, we focus on predictions for the Large Deformation Diffeomorphic Metric Mapping (LDDMM) model. Specifically, we predict the momentum-parameterization of LDDMM, which facilitates a patch-wise prediction strategy while maintaining the theoretical properties of LDDMM, such as guaranteed diffeomorphic mappings for sufficiently strong regularization. We also provide a probabilistic version of our prediction network which can be sampled during the testing time to calculate uncertainties in the predicted deformations. Finally, we introduce a new correction network which greatly increases the prediction accuracy of an already existing prediction network. We show experimental results for uni-modal atlas-to-image as well as uni-/multi-modal image-to-image registrations. These experiments demonstrate that our method accurately predicts registrations obtained by numerical optimization, is very fast, achieves state-of-the-art registration results on four standard validation datasets, and can jointly learn an image similarity measure. Quicksilver is freely available as an open-source software.
Keywords: Brain imaging; Deep learning; Image registration.
Copyright © 2017 Elsevier Inc. All rights reserved.
Figures
 , are removed.
, are removed.


References
-
- Modersitzki J. Numerical methods for image registration. Oxford University Press on Demand. 2004
-
- Biobank. website: www.ukbiobank.ac.uk.
-
- Chung K, Deisseroth K. CLARITY for mapping the nervous system. Nature methods. 2013;10(6):508–513. - PubMed
-
- Shams R, Sadeghi P, Kennedy RA, Hartley RI. A survey of medical image registration on multicore and the GPU. IEEE Signal Processing Magazine. 2010;27(2):50–60.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
