

Emotion Recognition from Chinese Speech for Smart Affective Services Using a Combination of SVM and DBN
- PMID: 28737705
- PMCID: PMC5539696
- DOI: 10.3390/s17071694
Emotion Recognition from Chinese Speech for Smart Affective Services Using a Combination of SVM and DBN
Abstract
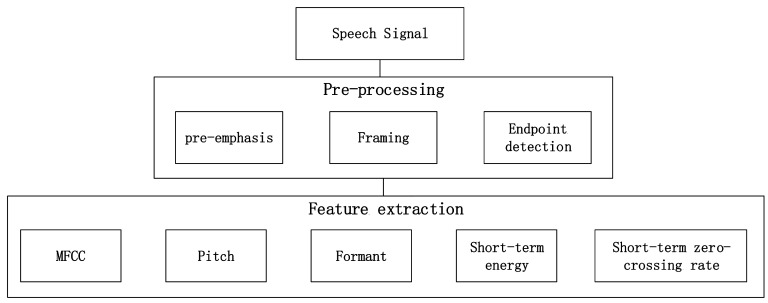
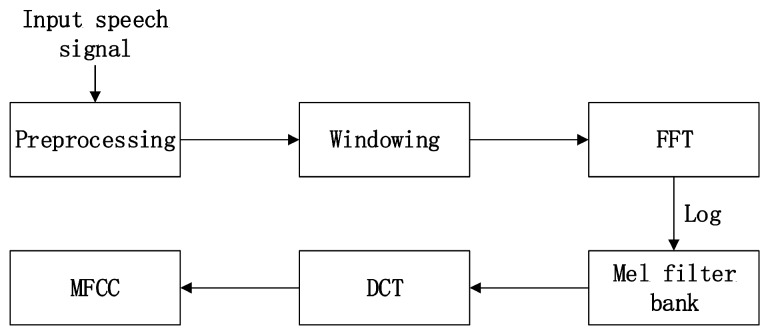
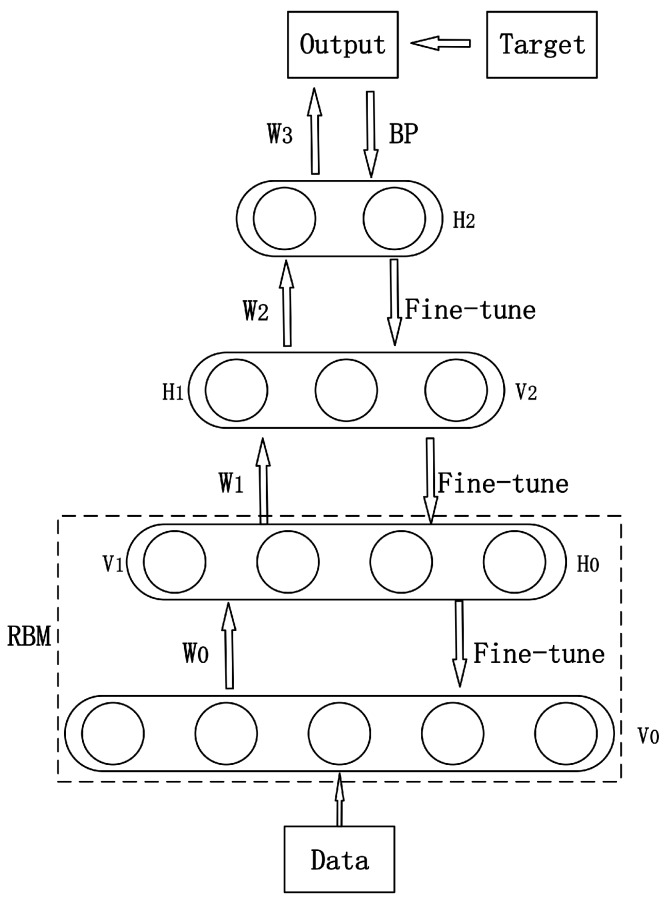
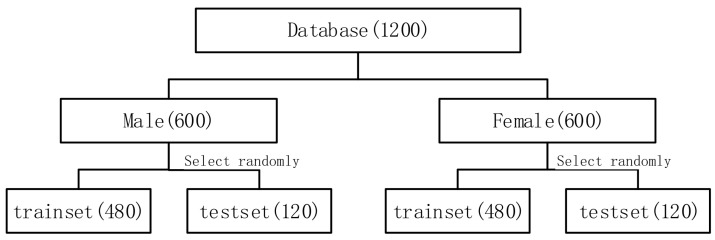
Accurate emotion recognition from speech is important for applications like smart health care, smart entertainment, and other smart services. High accuracy emotion recognition from Chinese speech is challenging due to the complexities of the Chinese language. In this paper, we explore how to improve the accuracy of speech emotion recognition, including speech signal feature extraction and emotion classification methods. Five types of features are extracted from a speech sample: mel frequency cepstrum coefficient (MFCC), pitch, formant, short-term zero-crossing rate and short-term energy. By comparing statistical features with deep features extracted by a Deep Belief Network (DBN), we attempt to find the best features to identify the emotion status for speech. We propose a novel classification method that combines DBN and SVM (support vector machine) instead of using only one of them. In addition, a conjugate gradient method is applied to train DBN in order to speed up the training process. Gender-dependent experiments are conducted using an emotional speech database created by the Chinese Academy of Sciences. The results show that DBN features can reflect emotion status better than artificial features, and our new classification approach achieves an accuracy of 95.8%, which is higher than using either DBN or SVM separately. Results also show that DBN can work very well for small training databases if it is properly designed.
Keywords: Deep Belief Networks; speech emotion recognition; speech features; support vector machine.
Conflict of interest statement
The authors declare no conflict of interest.
Figures


References
-
- Lee J., Tashev I. High-level Feature Representation using Recurrent Neural Network for Speech Emotion Recognition; Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association; Dresden, Germany. 6–10 September 2015.
-
- Jin Q., Li C., Chen S., Wu H. Speech emotion recognition with acoustic and lexical features; Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP); Brisbane, Australia. 19–24 April 2015; pp. 4749–4753.
-
- Li Y., Chao L., Liu Y., Bao W., Tao J. From simulated speech to natural speech, what are the robust features for emotion recognition?; Proceedings of the 2015 International Conference on Affective Computing and Intelligent Interaction (ACII); Xi’an, China. 21–24 September 2015; pp. 368–373.
-
- Samantaray A.K., Mahapatra K., Kabi B., Routray A. A novel approach of speech emotion recognition with prosody, quality and derived features using SVM classifier for a class of North-Eastern Languages; Proceedings of the 2015 IEEE 2nd International Conference on Recent Trends in Information Systems (ReTIS); Kolkata, India. 9–11 July 2015; pp. 372–377.
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
