

Inclusion of Population-specific Reference Panel from India to the 1000 Genomes Phase 3 Panel Improves Imputation Accuracy
- PMID: 28751670
- PMCID: PMC5532257
- DOI: 10.1038/s41598-017-06905-6
Inclusion of Population-specific Reference Panel from India to the 1000 Genomes Phase 3 Panel Improves Imputation Accuracy
Abstract
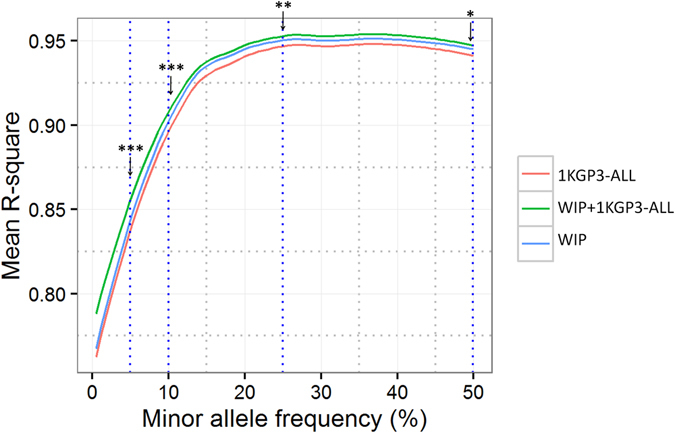
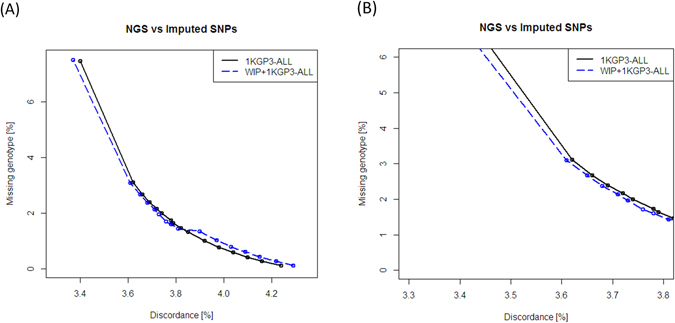
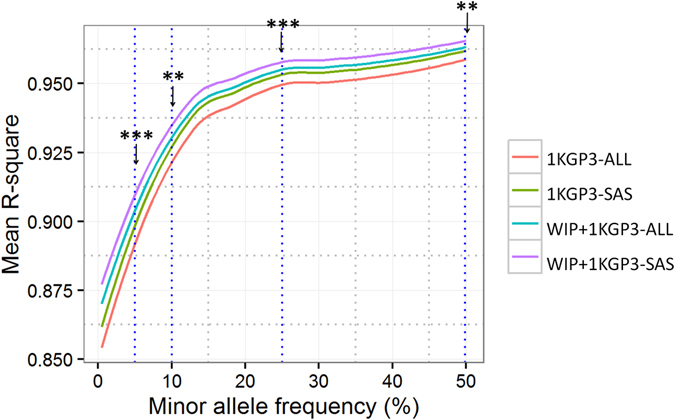
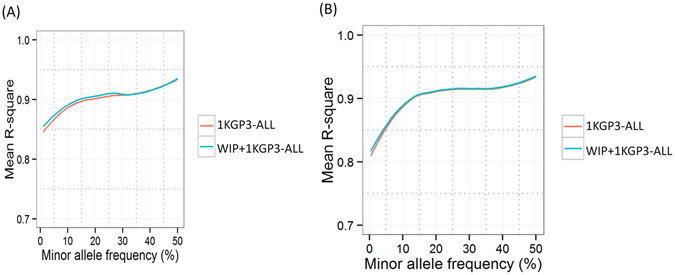
Imputation is a computational method based on the principle of haplotype sharing allowing enrichment of genome-wide association study datasets. It depends on the haplotype structure of the population and density of the genotype data. The 1000 Genomes Project led to the generation of imputation reference panels which have been used globally. However, recent studies have shown that population-specific panels provide better enrichment of genome-wide variants. We compared the imputation accuracy using 1000 Genomes phase 3 reference panel and a panel generated from genome-wide data on 407 individuals from Western India (WIP). The concordance of imputed variants was cross-checked with next-generation re-sequencing data on a subset of genomic regions. Further, using the genome-wide data from 1880 individuals, we demonstrate that WIP works better than the 1000 Genomes phase 3 panel and when merged with it, significantly improves the imputation accuracy throughout the minor allele frequency range. We also show that imputation using only South Asian component of the 1000 Genomes phase 3 panel works as good as the merged panel, making it computationally less intensive job. Thus, our study stresses that imputation accuracy using 1000 Genomes phase 3 panel can be further improved by including population-specific reference panels from South Asia.
Conflict of interest statement
The authors declare that they have no competing interests.
Figures

References
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
