

Instance Search Retrospective with Focus on TRECVID
- PMID: 28758054
- PMCID: PMC5531298
- DOI: 10.1007/s13735-017-0121-3
Instance Search Retrospective with Focus on TRECVID
Abstract
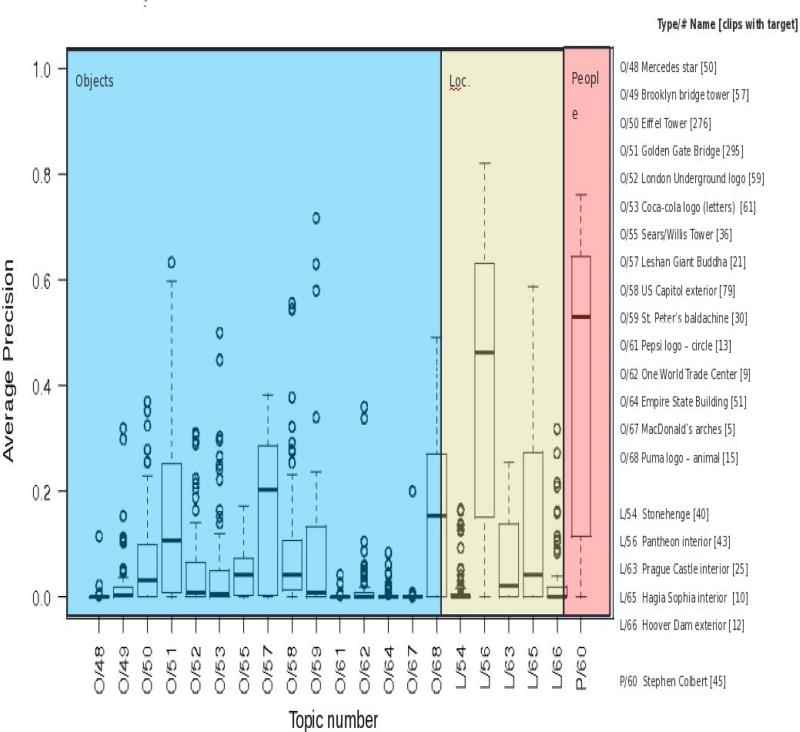
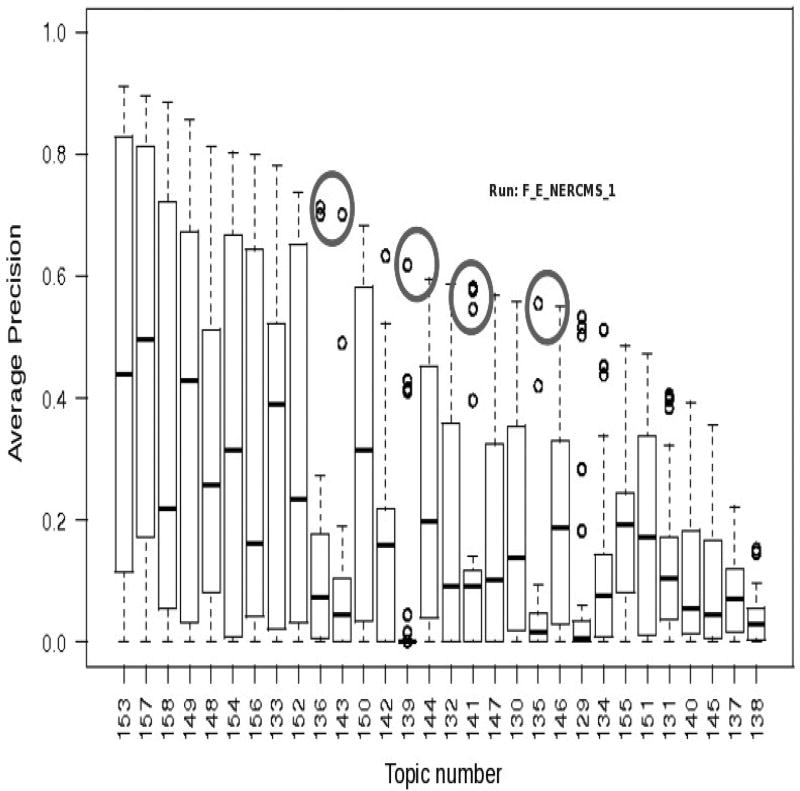
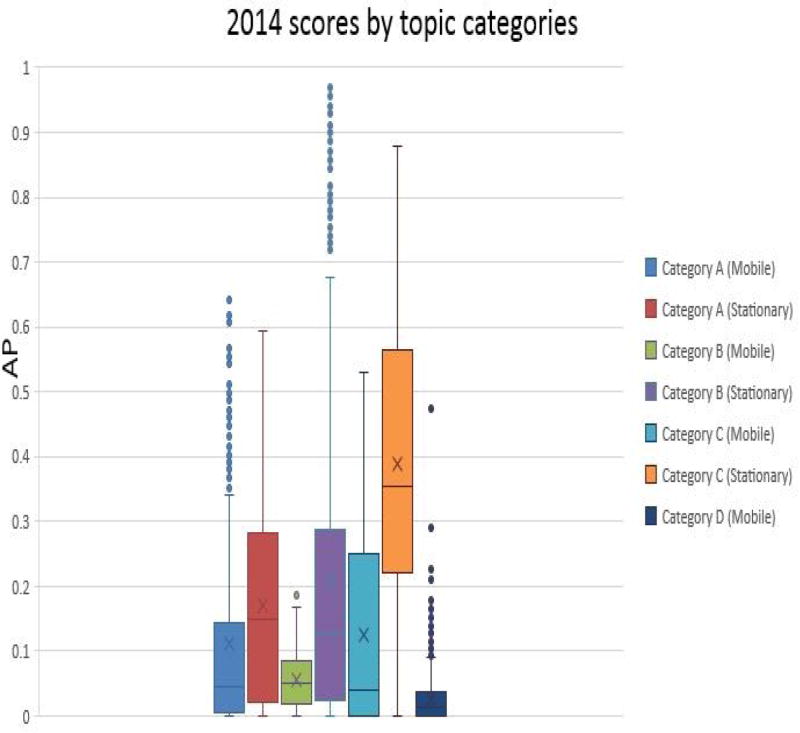
This paper presents an overview of the Video Instance Search benchmark which was run over a period of 6 years (2010-2015) as part of the TREC Video Retrieval (TRECVID) workshop series. The main contributions of the paper include i) an examination of the evolving design of the evaluation framework and its components (system tasks, data, measures); ii) an analysis of the influence of topic characteristics (such as rigid/non rigid, planar/non-planar, stationary/mobile on performance; iii) a high-level overview of results and best-performing approaches. The Instance Search (INS) benchmark worked with a variety of large collections of data including Sound & Vision, Flickr, BBC (British Broadcasting Corporation) Rushes for the first 3 pilot years and with the small world of the BBC Eastenders series for the last 3 years.
Keywords: TRECVID; evaluation; instance search; multimedia.
Figures










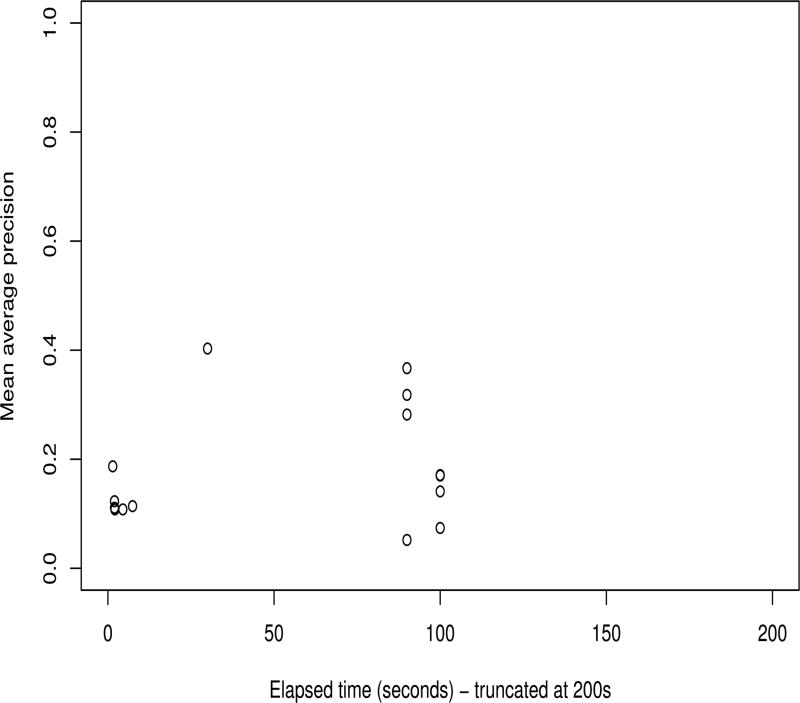


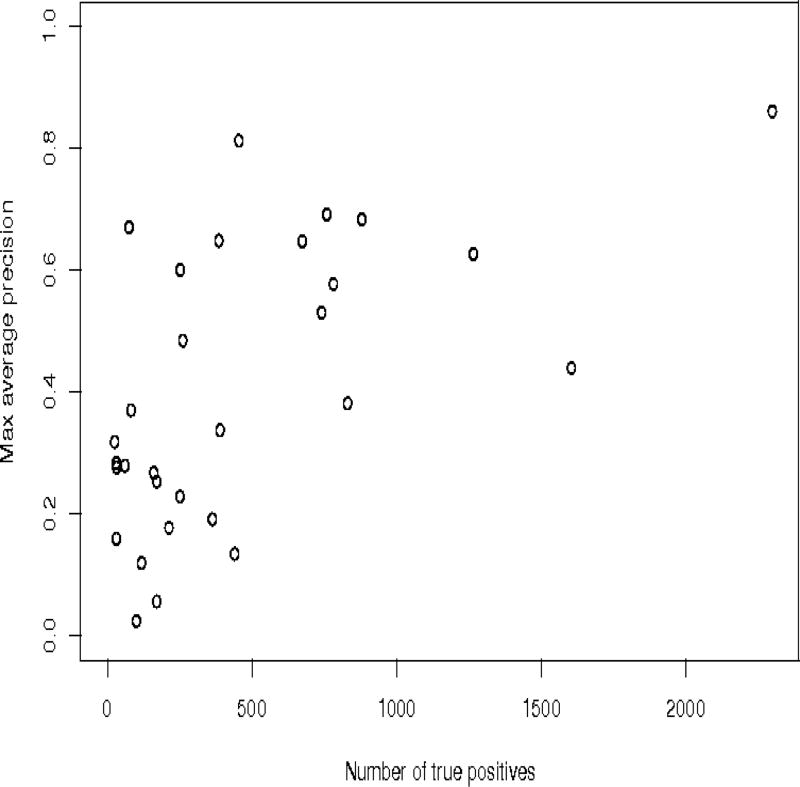
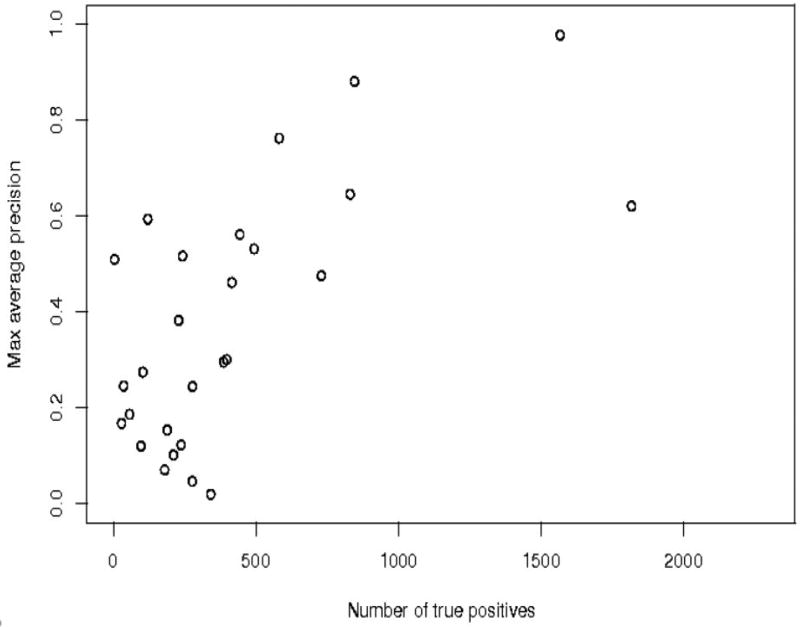
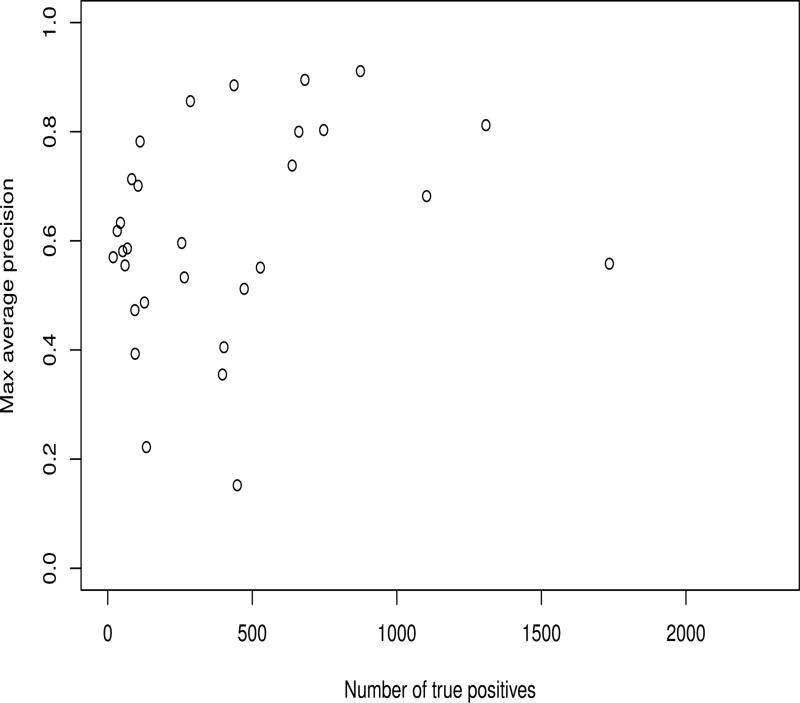

















References
-
- Arandjelovic O, Zisserman A. Automatic face recognition for film character retrieval in feature-length films. Computer Vision and Pattern Recognition, 2005. CVPR 2005. IEEE Computer Society Conference on; 2005. pp. 860–867. - DOI
-
- Arandjelovic R, Zisserman A. In: Bowden R, Collomosse JP, Mikolajczyk K, editors. Multiple queries for large scale specific object retrieval; British Machine Vision Conference, BMVC 2012, Surrey, UK; September 3–7, 2012; BMVA Press; 2012. pp. 1–11. URL http://dx.doi.org/10.5244/C.26.92. - DOI - DOI
-
- Arandjelovic R, Zisserman A. Three things everyone should know to improve object retrieval; 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA; June 16–21, 2012; IEEE Computer Society; 2012. pp. 2911–2918. URL http://dx.doi.org/10.1109/CVPR.2012.6248018. - DOI - DOI
-
- Babenko A, Lempitsky VS. Aggregating local deep features for image retrieval; 2015 IEEE International Conference on Computer Vision, ICCV 2015, Santiago, Chile; December 7–13, 2015; IEEE Computer Society; 2015. pp. 1269–1277. URL http://dx.doi.org/10.1109/ICCV.2015.150. - DOI - DOI
-
- Babenko A, Slesarev A, Chigorin A, Lempitsky VS. In: Fleet DJ, Pajdla T, Schiele B, Tuytelaars T, editors. Neural codes for image retrieval; Computer Vision - ECCV 2014 - 13th European Conference, Zurich, Switzerland, September 6–12, 2014, Proceedings, Part I, Lecture Notes in Computer Science; Springer; 2014. pp. 584–599. URL http://dx.doi.org/10.1007/978-3-319-10590-1_38. - DOI - DOI
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources