

Functional annotation of chemical libraries across diverse biological processes
- PMID: 28759014
- PMCID: PMC6056180
- DOI: 10.1038/nchembio.2436
Functional annotation of chemical libraries across diverse biological processes
Erratum in
-
Errata: Functional annotation of chemical libraries across diverse biological processes.Nat Chem Biol. 2017 Nov 21;13(12):1286. doi: 10.1038/nchembio1217-1286b. Nat Chem Biol. 2017. PMID: 29161244
-
Errata: Functional annotation of chemical libraries across diverse biological processes.Nat Chem Biol. 2017 Nov 21;13(12):1286. doi: 10.1038/nchembio1217-1286a. Nat Chem Biol. 2017. PMID: 29161247
Abstract
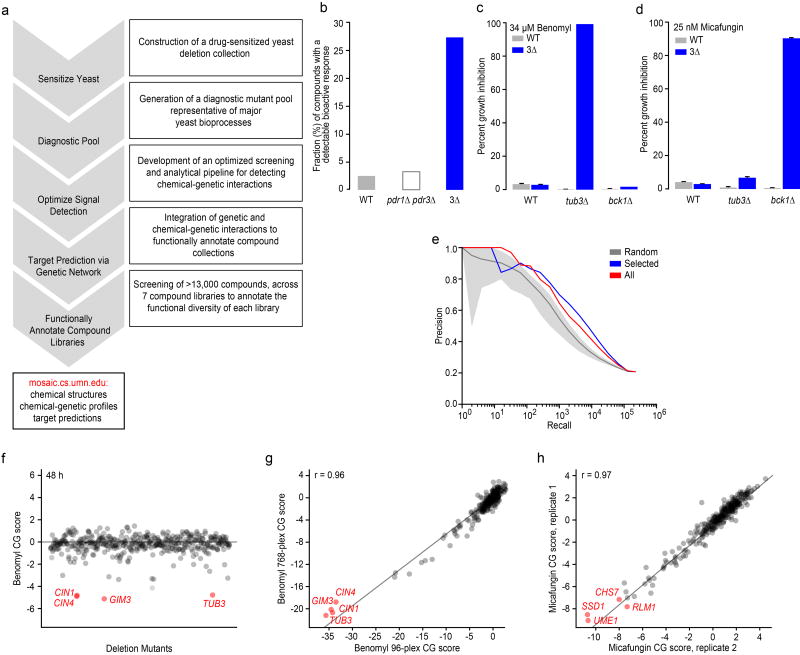
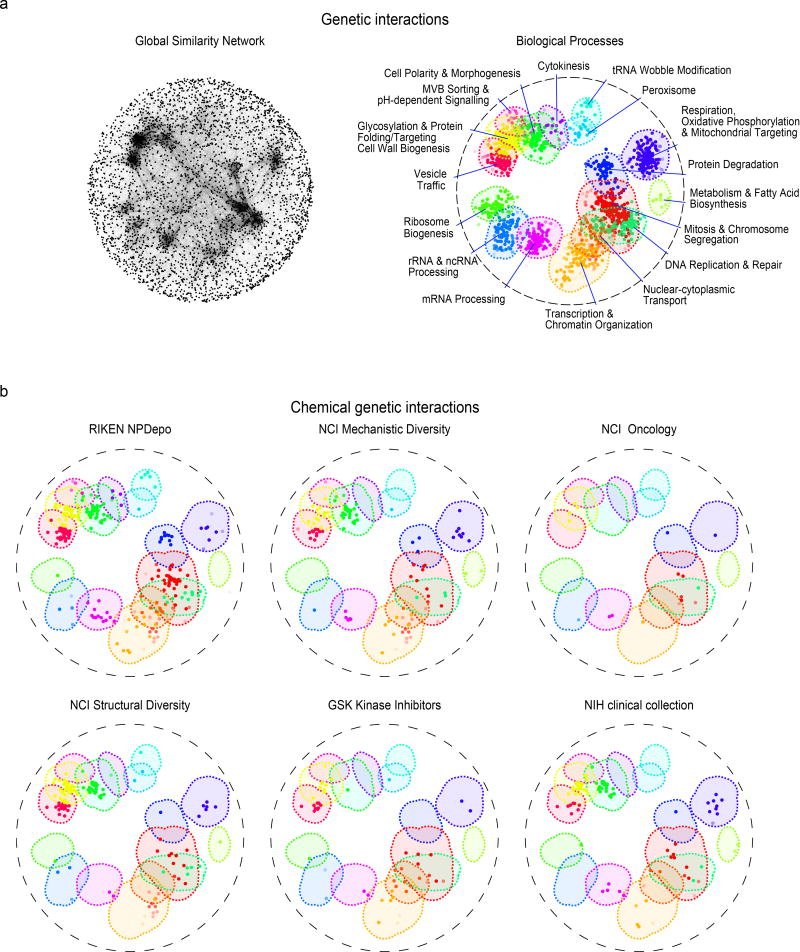
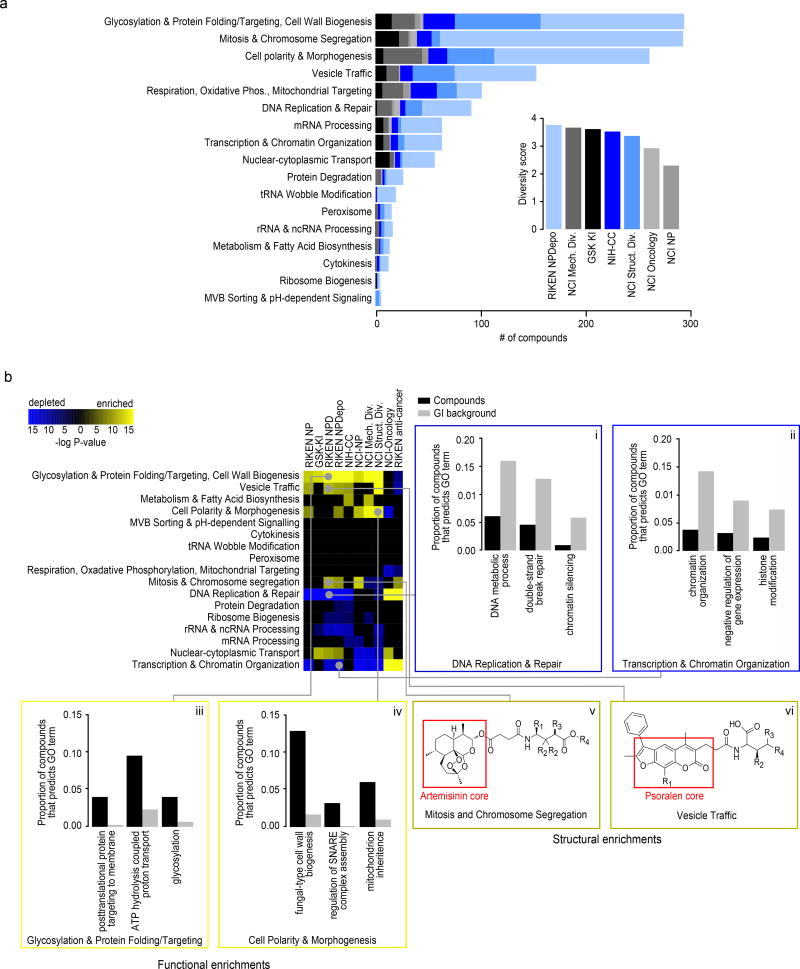
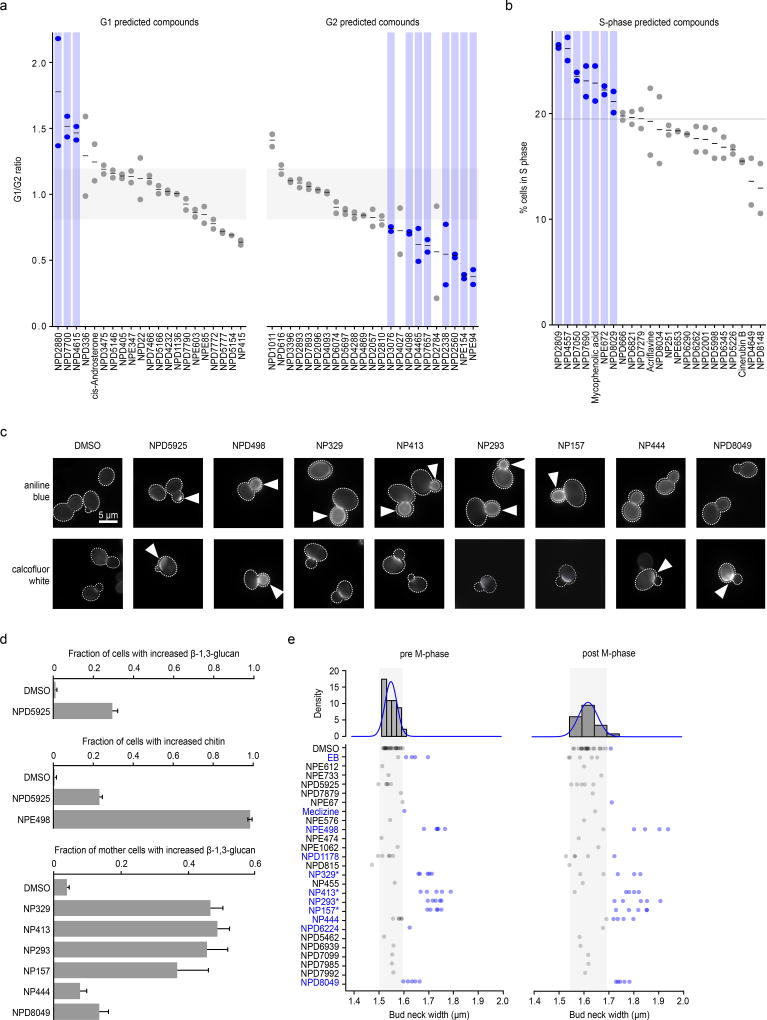
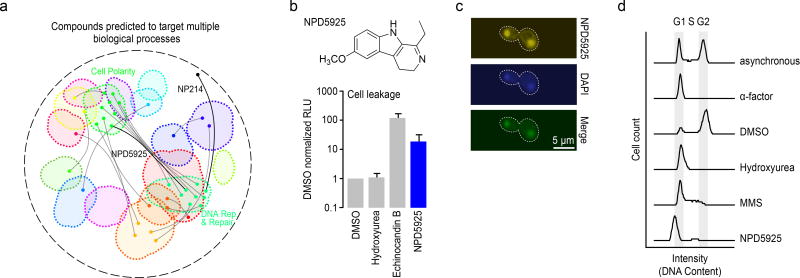
Chemical-genetic approaches offer the potential for unbiased functional annotation of chemical libraries. Mutations can alter the response of cells in the presence of a compound, revealing chemical-genetic interactions that can elucidate a compound's mode of action. We developed a highly parallel, unbiased yeast chemical-genetic screening system involving three key components. First, in a drug-sensitive genetic background, we constructed an optimized diagnostic mutant collection that is predictive for all major yeast biological processes. Second, we implemented a multiplexed (768-plex) barcode-sequencing protocol, enabling the assembly of thousands of chemical-genetic profiles. Finally, based on comparison of the chemical-genetic profiles with a compendium of genome-wide genetic interaction profiles, we predicted compound functionality. Applying this high-throughput approach, we screened seven different compound libraries and annotated their functional diversity. We further validated biological process predictions, prioritized a diverse set of compounds, and identified compounds that appear to have dual modes of action.
Figures

References
-
- Mario Geysen H, Schoenen F, Wagner D, Wagner R. Combinatorial compound libraries for drug discovery: an ongoing challenge. Nat. Rev. Drug Discov. 2003;2:222–230. - PubMed
-
- Roemer T, Boone C. Systems-level antimicrobial drug and drug synergy discovery. Nat. Chem. Biol. 2013;9:222–231. - PubMed
-
- Kepp O, Galluzzi L, Lipinski M, Yuan J, Kroemer G. Cell death assays for drug discovery. Nat. Rev. Drug Discov. 2011;10:221–237. - PubMed
-
- Clemons PA. Complex phenotypic assays in high-throughput screening. Curr. Opin. Chem. Biol. 2004;8:334–338. - PubMed
-
- Sundberg SA. High-throughput and ultra-high-throughput screening: solution- and cell-based approaches. Curr. Opin. Biotechnol. 2000;11:47–53. - PubMed
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
