

Familiarity and Voice Representation: From Acoustic-Based Representation to Voice Averages
- PMID: 28769836
- PMCID: PMC5509798
- DOI: 10.3389/fpsyg.2017.01180
Familiarity and Voice Representation: From Acoustic-Based Representation to Voice Averages
Abstract
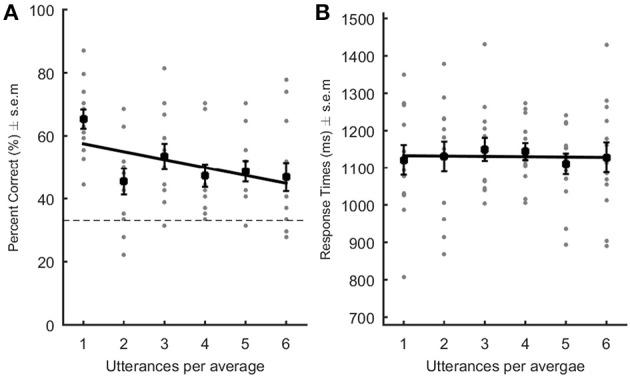
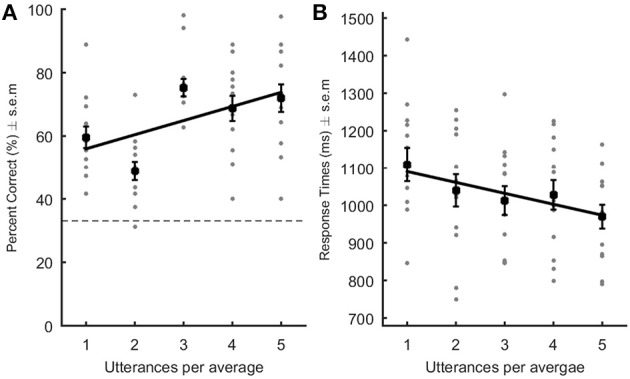
The ability to recognize an individual from their voice is a widespread ability with a long evolutionary history. Yet, the perceptual representation of familiar voices is ill-defined. In two experiments, we explored the neuropsychological processes involved in the perception of voice identity. We specifically explored the hypothesis that familiar voices (trained-to-familiar (Experiment 1), and famous voices (Experiment 2)) are represented as a whole complex pattern, well approximated by the average of multiple utterances produced by a single speaker. In experiment 1, participants learned three voices over several sessions, and performed a three-alternative forced-choice identification task on original voice samples and several "speaker averages," created by morphing across varying numbers of different vowels (e.g., [a] and [i]) produced by the same speaker. In experiment 2, the same participants performed the same task on voice samples produced by familiar speakers. The two experiments showed that for famous voices, but not for trained-to-familiar voices, identification performance increased and response times decreased as a function of the number of utterances in the averages. This study sheds light on the perceptual representation of familiar voices, and demonstrates the power of average in recognizing familiar voices. The speaker average captures the unique characteristics of a speaker, and thus retains the information essential for recognition; it acts as a prototype of the speaker.
Keywords: average; familiarity; identity; prototypes; recognition; speech; voice; vowels.
Figures
References
-
- Andics A., Mcqueen J. M., Van Turennout M. (2007). Phonetic content influences voice discriminability, in Proceedings of the 16th International Congress of Phonetic Sciences (ICPhS 2007), eds Trouvain J., Barry W. J. (Dudweiler: Pirrot; ), 1829–1832.
LinkOut - more resources
Full Text Sources
Other Literature Sources