

Detecting representative data and generating synthetic samples to improve learning accuracy with imbalanced data sets
- PMID: 28771522
- PMCID: PMC5542532
- DOI: 10.1371/journal.pone.0181853
Detecting representative data and generating synthetic samples to improve learning accuracy with imbalanced data sets
Abstract
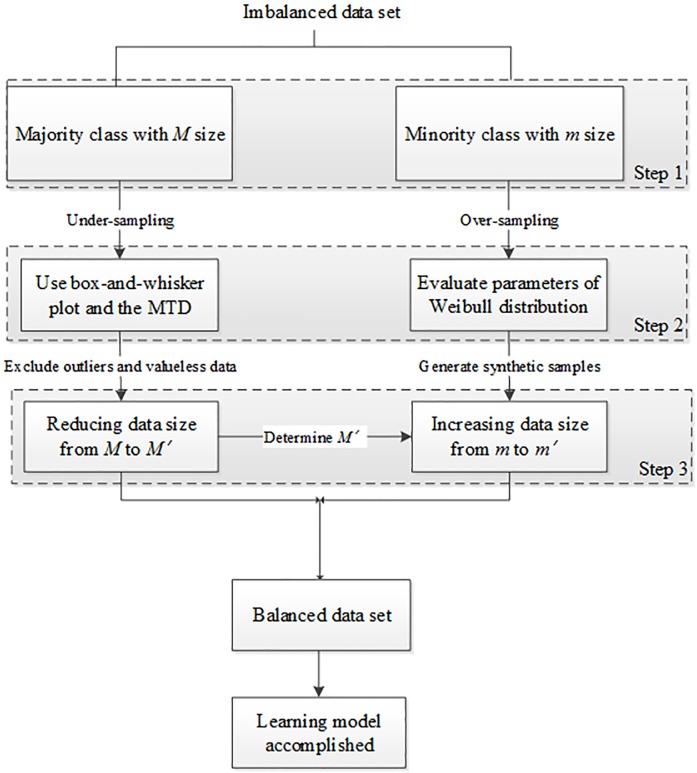
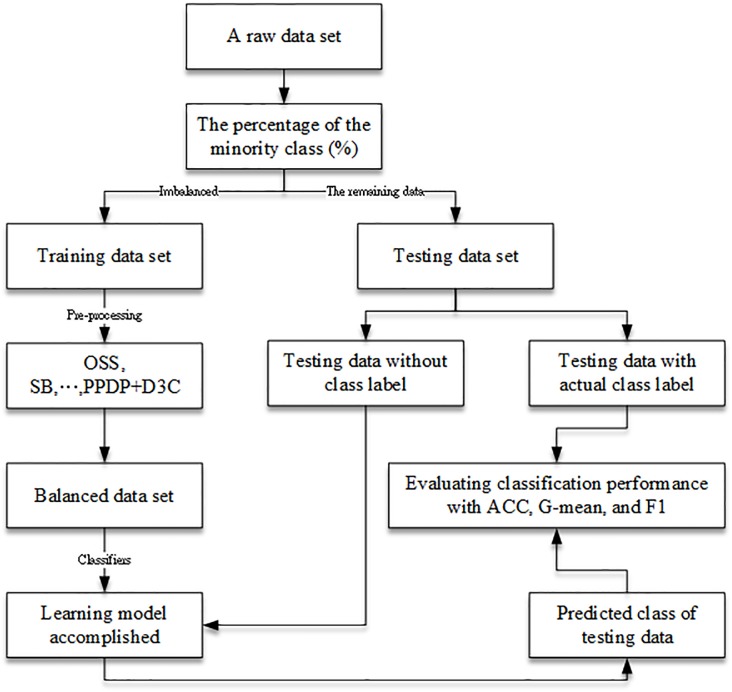
It is difficult for learning models to achieve high classification performances with imbalanced data sets, because with imbalanced data sets, when one of the classes is much larger than the others, most machine learning and data mining classifiers are overly influenced by the larger classes and ignore the smaller ones. As a result, the classification algorithms often have poor learning performances due to slow convergence in the smaller classes. To balance such data sets, this paper presents a strategy that involves reducing the sizes of the majority data and generating synthetic samples for the minority data. In the reducing operation, we use the box-and-whisker plot approach to exclude outliers and the Mega-Trend-Diffusion method to find representative data from the majority data. To generate the synthetic samples, we propose a counterintuitive hypothesis to find the distributed shape of the minority data, and then produce samples according to this distribution. Four real datasets were used to examine the performance of the proposed approach. We used paired t-tests to compare the Accuracy, G-mean, and F-measure scores of the proposed data pre-processing (PPDP) method merging in the D3C method (PPDP+D3C) with those of the one-sided selection (OSS), the well-known SMOTEBoost (SB) study, and the normal distribution-based oversampling (NDO) approach, and the proposed data pre-processing (PPDP) method. The results indicate that the classification performance of the proposed approach is better than that of above-mentioned methods.
Conflict of interest statement
Figures
Similar articles
-
RAMOBoost: Ranked Minority Oversampling in Boosting.IEEE Trans Neural Netw. 2010 Oct;21(10):1624-42. doi: 10.1109/TNN.2010.2066988. Epub 2010 Aug 30. IEEE Trans Neural Netw. 2010. PMID: 20805051
-
Interaction effect between data discretization and data resampling for class-imbalanced medical datasets.Technol Health Care. 2025 Mar;33(2):1000-1013. doi: 10.1177/09287329241295874. Epub 2024 Nov 25. Technol Health Care. 2025. PMID: 40105161
-
Affinity and class probability-based fuzzy support vector machine for imbalanced data sets.Neural Netw. 2020 Feb;122:289-307. doi: 10.1016/j.neunet.2019.10.016. Epub 2019 Nov 2. Neural Netw. 2020. PMID: 31739268
-
A comprehensive data level analysis for cancer diagnosis on imbalanced data.J Biomed Inform. 2019 Feb;90:103089. doi: 10.1016/j.jbi.2018.12.003. Epub 2019 Jan 3. J Biomed Inform. 2019. PMID: 30611011 Review.
-
Handling the Imbalanced Problem in Agri-Food Data Analysis.Foods. 2024 Oct 17;13(20):3300. doi: 10.3390/foods13203300. Foods. 2024. PMID: 39456362 Free PMC article. Review.
Cited by
-
Exploring the Interplay of Dataset Size and Imbalance on CNN Performance in Healthcare: Using X-rays to Identify COVID-19 Patients.Diagnostics (Basel). 2024 Aug 8;14(16):1727. doi: 10.3390/diagnostics14161727. Diagnostics (Basel). 2024. PMID: 39202215 Free PMC article.
-
Radiologist observations of computed tomography (CT) images predict treatment outcome in TB Portals, a real-world database of tuberculosis (TB) cases.PLoS One. 2021 Mar 17;16(3):e0247906. doi: 10.1371/journal.pone.0247906. eCollection 2021. PLoS One. 2021. PMID: 33730021 Free PMC article.
-
Prediction of Neurological Outcomes in Out-of-hospital Cardiac Arrest Survivors Immediately after Return of Spontaneous Circulation: Ensemble Technique with Four Machine Learning Models.J Korean Med Sci. 2021 Jul 19;36(28):e187. doi: 10.3346/jkms.2021.36.e187. J Korean Med Sci. 2021. PMID: 34282605 Free PMC article.
-
Cardiovascular Disease Prediction by Machine Learning Algorithms Based on Cytokines in Kazakhs of China.Clin Epidemiol. 2021 Jun 9;13:417-428. doi: 10.2147/CLEP.S313343. eCollection 2021. Clin Epidemiol. 2021. PMID: 34135637 Free PMC article.
-
Cellular frustration algorithms for anomaly detection applications.PLoS One. 2019 Jul 8;14(7):e0218930. doi: 10.1371/journal.pone.0218930. eCollection 2019. PLoS One. 2019. PMID: 31283758 Free PMC article.
References
-
- Murphey YL, Guo H, Feldkamp LA. Neural learning from unbalanced data. Applied Intelligence. 2004;21(2):117–28.
-
- Cohen G, Hilario M, Sax H, Hugonnet S, Geissbuhler A. Learning from imbalanced data in surveillance of nosocomial infection. Artif Intell Med. 2006;37(1):7–18. doi: 10.1016/j.artmed.2005.03.002 . - DOI - PubMed
-
- Sun Y, Kamel MS, Wong AKC, Wang Y. Cost-sensitive boosting for classification of imbalanced data. Pattern Recognition. 2007;40(12):3358–78. doi: 10.1016/j.patcog.2007.04.009 - DOI
-
- Sun Y, Wong AK, Kamel MS. Classification of imbalanced data: A review. International Journal of Pattern Recognition and Artificial Intelligence. 2009;23(04):687–719.
-
- Li DC, Liu CW, Hu SC. A learning method for the class imbalance problem with medical data sets. Comput Biol Med. 2010;40(5):509–18. doi: 10.1016/j.compbiomed.2010.03.005 . - DOI - PubMed
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
Research Materials
