

Cortical Representations of Speech in a Multitalker Auditory Scene
- PMID: 28821680
- PMCID: PMC5607465
- DOI: 10.1523/JNEUROSCI.0938-17.2017
Cortical Representations of Speech in a Multitalker Auditory Scene
Abstract
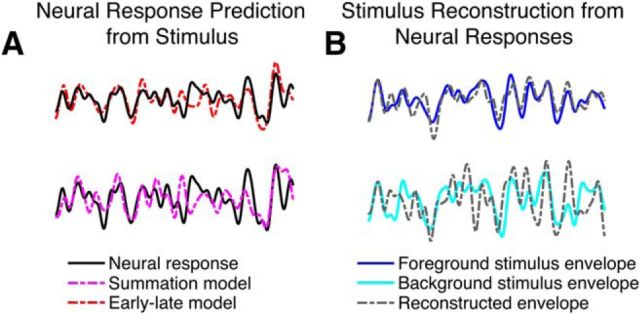
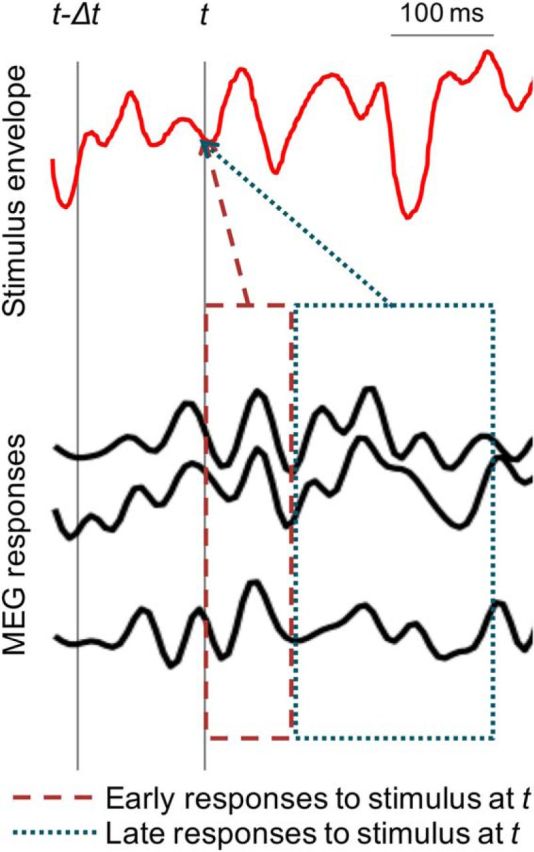
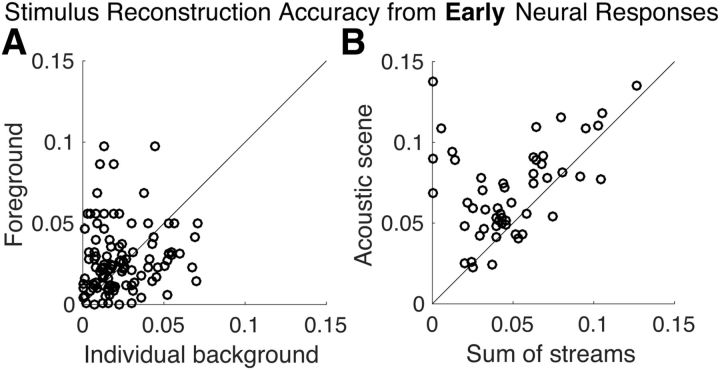
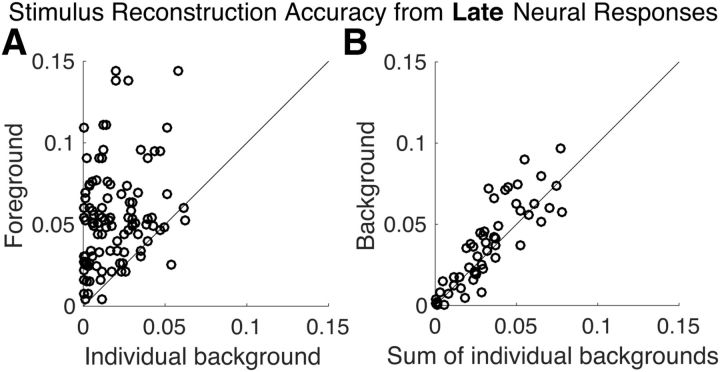
The ability to parse a complex auditory scene into perceptual objects is facilitated by a hierarchical auditory system. Successive stages in the hierarchy transform an auditory scene of multiple overlapping sources, from peripheral tonotopically based representations in the auditory nerve, into perceptually distinct auditory-object-based representations in the auditory cortex. Here, using magnetoencephalography recordings from men and women, we investigate how a complex acoustic scene consisting of multiple speech sources is represented in distinct hierarchical stages of the auditory cortex. Using systems-theoretic methods of stimulus reconstruction, we show that the primary-like areas in the auditory cortex contain dominantly spectrotemporal-based representations of the entire auditory scene. Here, both attended and ignored speech streams are represented with almost equal fidelity, and a global representation of the full auditory scene with all its streams is a better candidate neural representation than that of individual streams being represented separately. We also show that higher-order auditory cortical areas, by contrast, represent the attended stream separately and with significantly higher fidelity than unattended streams. Furthermore, the unattended background streams are more faithfully represented as a single unsegregated background object rather than as separated objects. Together, these findings demonstrate the progression of the representations and processing of a complex acoustic scene up through the hierarchy of the human auditory cortex.SIGNIFICANCE STATEMENT Using magnetoencephalography recordings from human listeners in a simulated cocktail party environment, we investigate how a complex acoustic scene consisting of multiple speech sources is represented in separate hierarchical stages of the auditory cortex. We show that the primary-like areas in the auditory cortex use a dominantly spectrotemporal-based representation of the entire auditory scene, with both attended and unattended speech streams represented with almost equal fidelity. We also show that higher-order auditory cortical areas, by contrast, represent an attended speech stream separately from, and with significantly higher fidelity than, unattended speech streams. Furthermore, the unattended background streams are represented as a single undivided background object rather than as distinct background objects.
Keywords: attention; auditory cortex; cocktail party problem; magnetoencephalography; stimulus reconstruction; temporal response function.
Copyright © 2017 the authors 0270-6474/17/379189-08$15.00/0.
Figures
References
-
- Ahveninen J, Hämäläinen M, Jääskeläinen IP, Ahlfors SP, Huang S, Lin FH, Raij T, Sams M, Vasios CE, Belliveau JW (2011) Attention-driven auditory cortex short-term plasticity helps segregate relevant sounds from noise. Proc Natl Acad Sci U S A 108:4182–4187. 10.1073/pnas.1016134108 - DOI - PMC - PubMed
-
- Bregman AS. (1994) Auditory scene analysis: the perceptual organization of sound. Cambridge, MA: MIT.
-
- Cherry EC. (1953) Some experiments on the recognition of speech, with one and with 2 ears. J Acoust Soc Am 25:975–979. 10.1121/1.1907229 - DOI
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources