

When Null Hypothesis Significance Testing Is Unsuitable for Research: A Reassessment
- PMID: 28824397
- PMCID: PMC5540883
- DOI: 10.3389/fnhum.2017.00390
When Null Hypothesis Significance Testing Is Unsuitable for Research: A Reassessment
Abstract
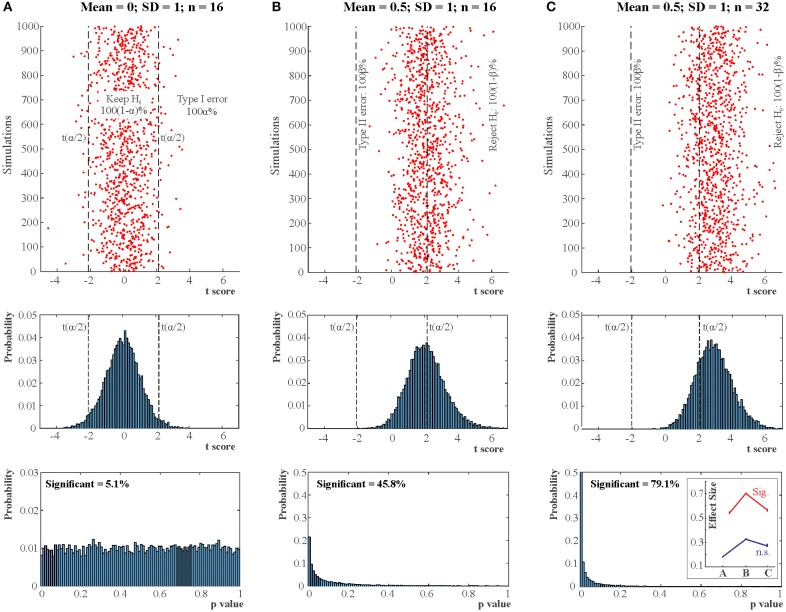
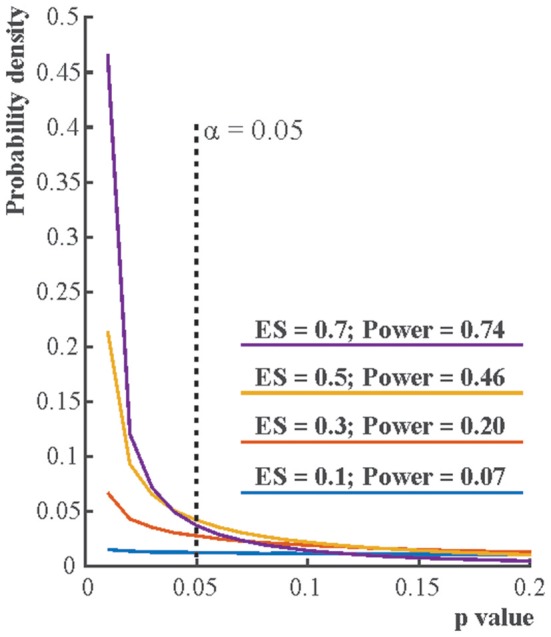
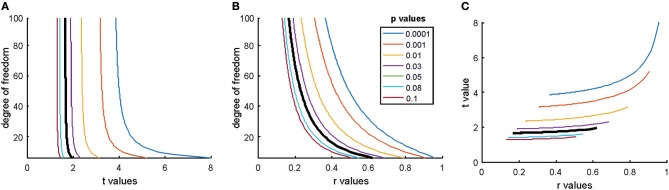
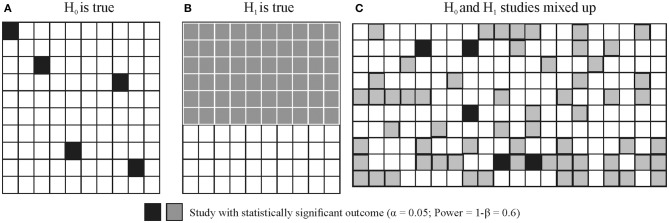
Null hypothesis significance testing (NHST) has several shortcomings that are likely contributing factors behind the widely debated replication crisis of (cognitive) neuroscience, psychology, and biomedical science in general. We review these shortcomings and suggest that, after sustained negative experience, NHST should no longer be the default, dominant statistical practice of all biomedical and psychological research. If theoretical predictions are weak we should not rely on all or nothing hypothesis tests. Different inferential methods may be most suitable for different types of research questions. Whenever researchers use NHST they should justify its use, and publish pre-study power calculations and effect sizes, including negative findings. Hypothesis-testing studies should be pre-registered and optimally raw data published. The current statistics lite educational approach for students that has sustained the widespread, spurious use of NHST should be phased out.
Keywords: Bayesian methods; false positive findings; null hypothesis significance testing; replication crisis; research methodology.
Figures
References
Publication types
LinkOut - more resources
Full Text Sources
Other Literature Sources