

Object segmentation controls image reconstruction from natural scenes
- PMID: 28827801
- PMCID: PMC5565198
- DOI: 10.1371/journal.pbio.1002611
Object segmentation controls image reconstruction from natural scenes
Abstract
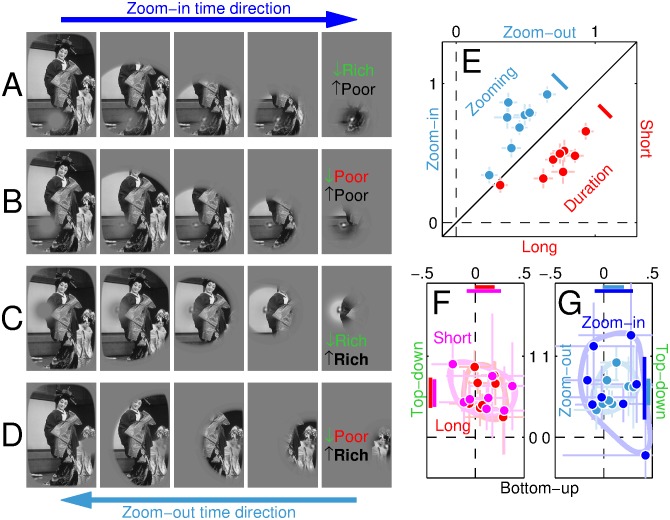
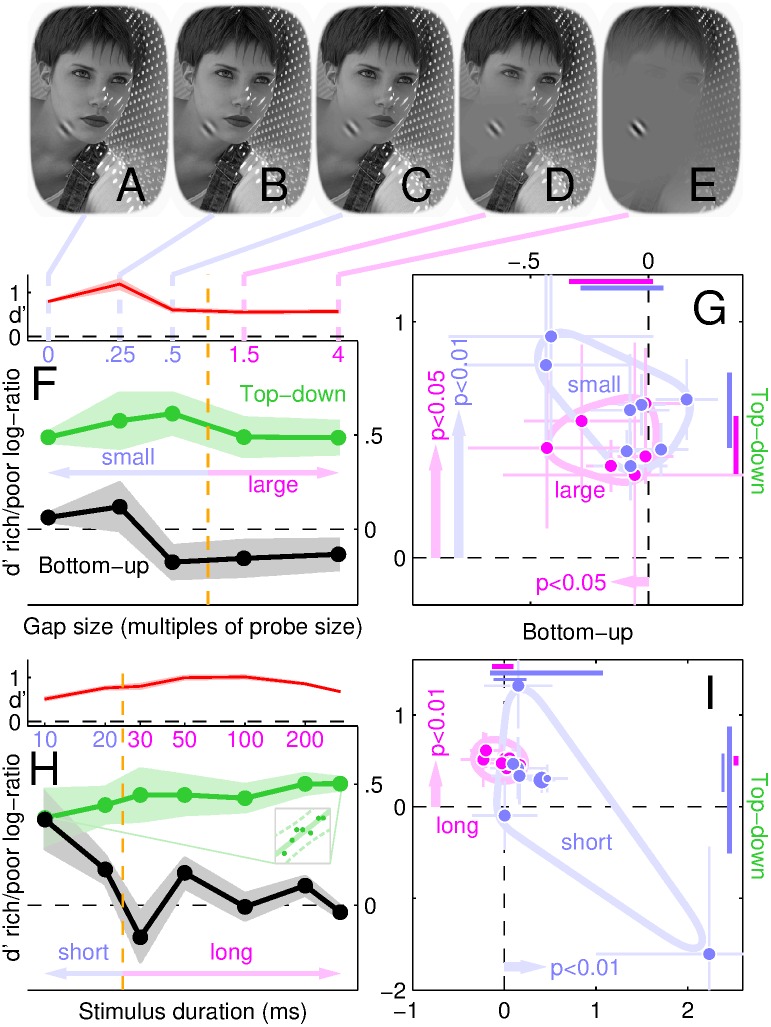
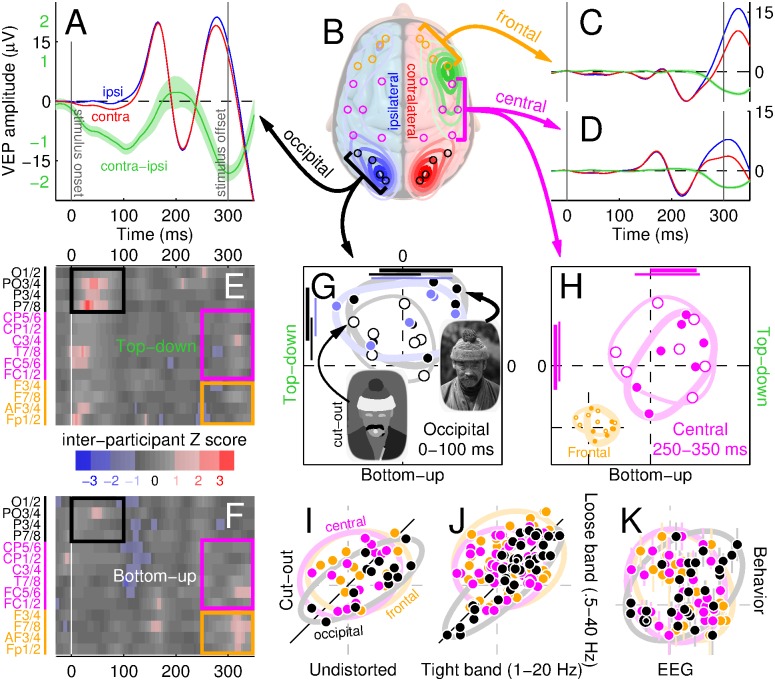
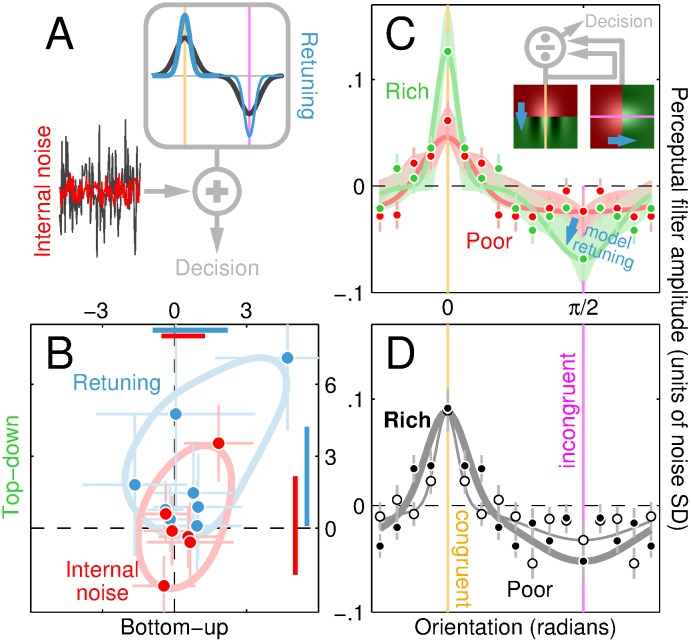
The structure of the physical world projects images onto our eyes. However, those images are often poorly representative of environmental structure: well-defined boundaries within the eye may correspond to irrelevant features of the physical world, while critical features of the physical world may be nearly invisible at the retinal projection. The challenge for the visual cortex is to sort these two types of features according to their utility in ultimately reconstructing percepts and interpreting the constituents of the scene. We describe a novel paradigm that enabled us to selectively evaluate the relative role played by these two feature classes in signal reconstruction from corrupted images. Our measurements demonstrate that this process is quickly dominated by the inferred structure of the environment, and only minimally controlled by variations of raw image content. The inferential mechanism is spatially global and its impact on early visual cortex is fast. Furthermore, it retunes local visual processing for more efficient feature extraction without altering the intrinsic transduction noise. The basic properties of this process can be partially captured by a combination of small-scale circuit models and large-scale network architectures. Taken together, our results challenge compartmentalized notions of bottom-up/top-down perception and suggest instead that these two modes are best viewed as an integrated perceptual mechanism.
Conflict of interest statement
The author has declared that no competing interests exist.
Figures
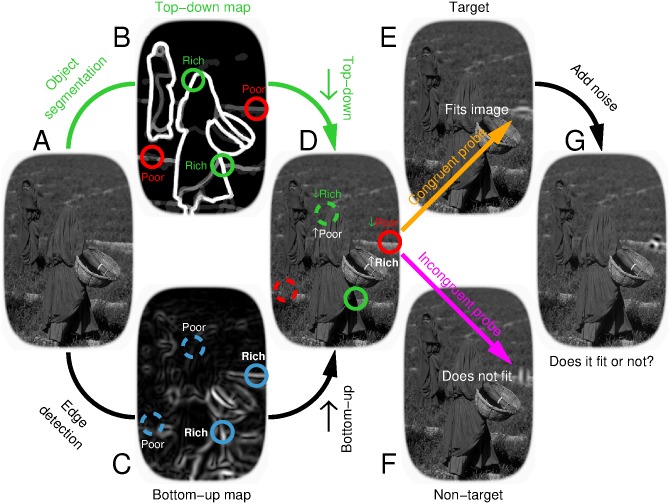
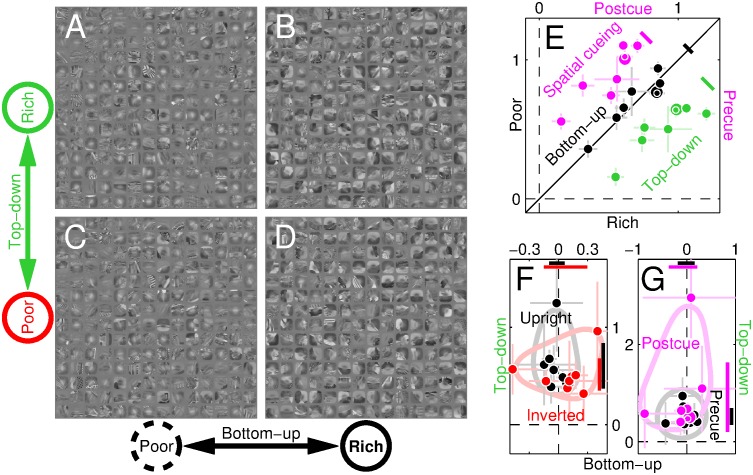
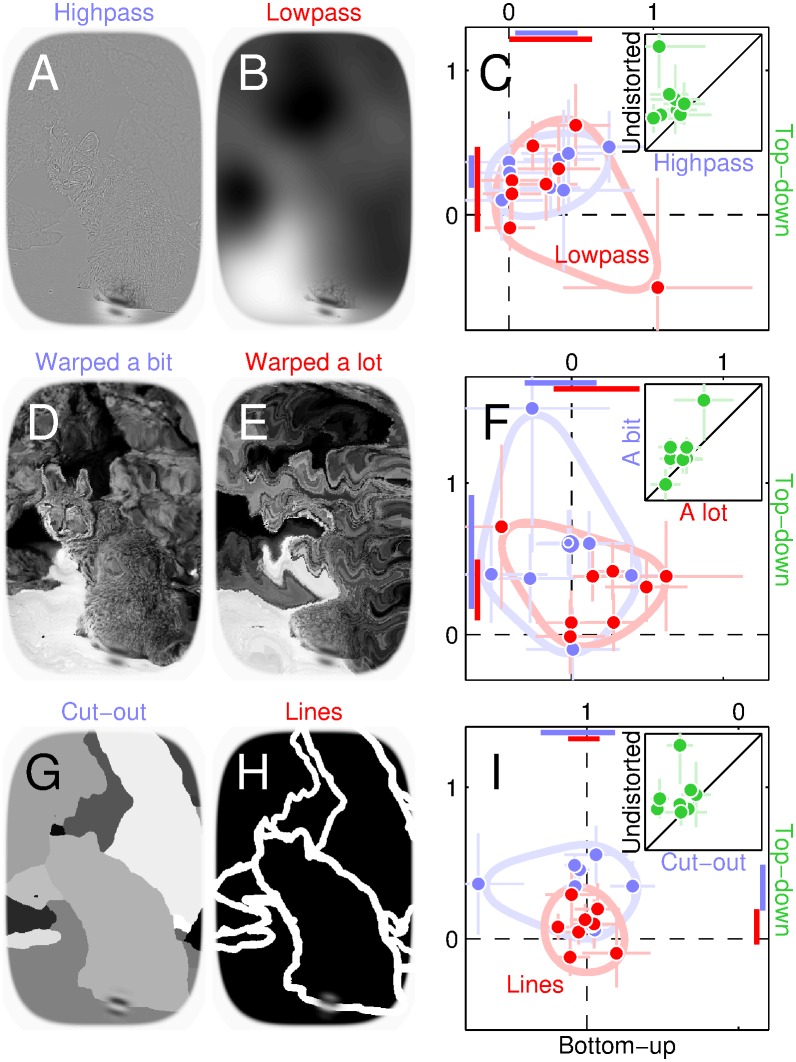
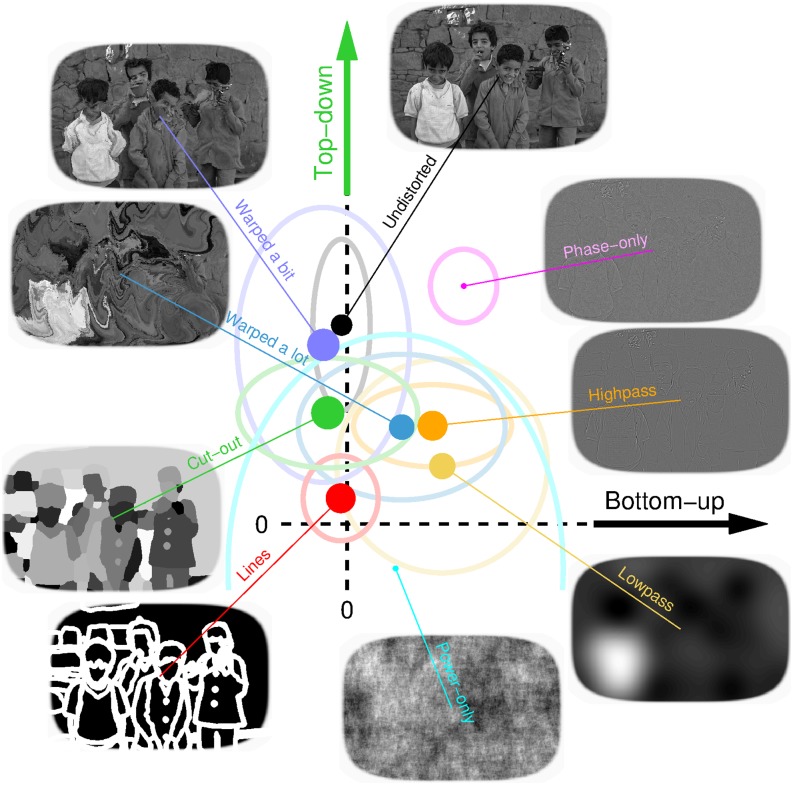
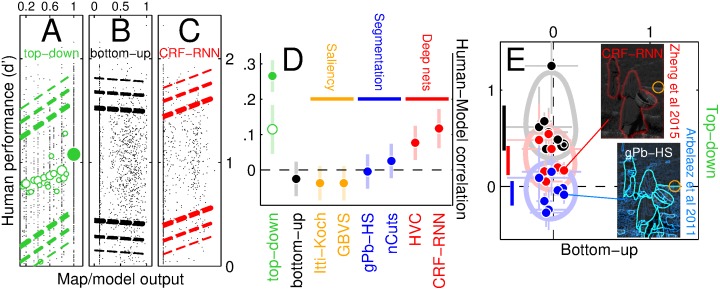
References
-
- Hubel DH. The visual cortex of the brain. Sci Am. 1963;209:54–62. - PubMed
-
- Marr DC. Vision: A Computational Investigation into the Human Representation and Processing of Visual Information. New York: Freeman; 1982.
-
- Itti L, Koch C. Computational modelling of visual attention. Nat Rev Neurosci. 2001;2(3):194–203. doi: 10.1038/35058500 - DOI - PubMed
-
- Morgan MJ. Features and the 'primal sketch'. Vision Res. 2011;51:738–753. doi: 10.1016/j.visres.2010.08.002 - DOI - PMC - PubMed
-
- Arbelaez P, Maire M, Fowlkes C, Malik J. Contour Detection and Hierarchical Image Segmentation. IEEE Trans Patt Anal Mach Intell. 2011;33(5):898–916. doi: 10.1109/TPAMI.2010.161 - DOI - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
