

A comparison of resampling schemes for estimating model observer performance with small ensembles
- PMID: 28829044
- PMCID: PMC5944841
- DOI: 10.1088/1361-6560/aa807a
A comparison of resampling schemes for estimating model observer performance with small ensembles
Abstract
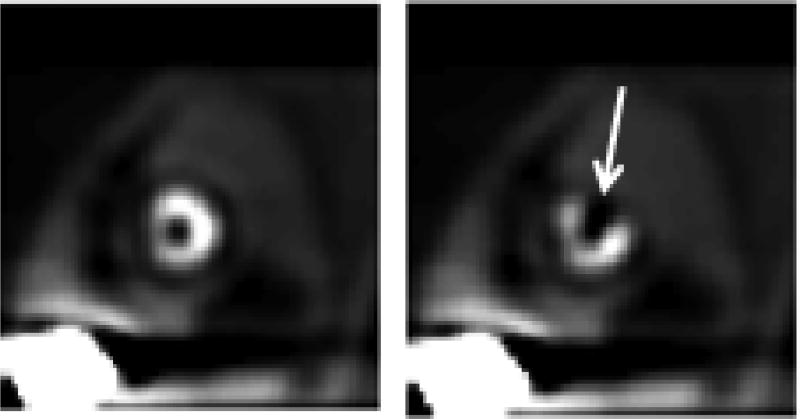
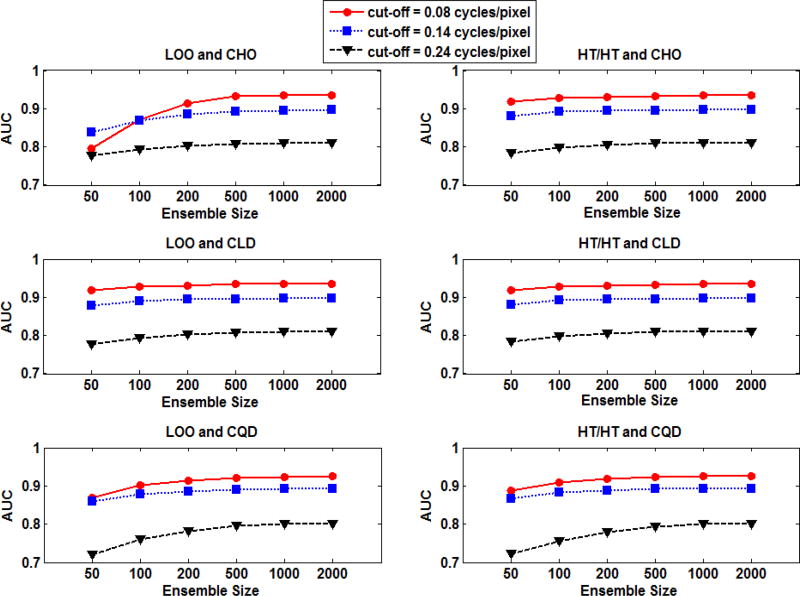
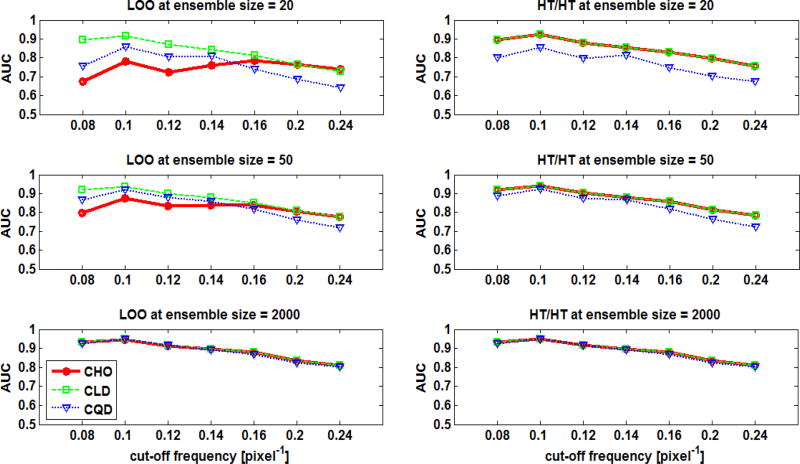
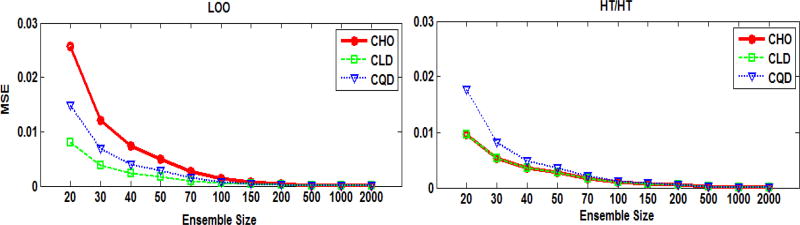
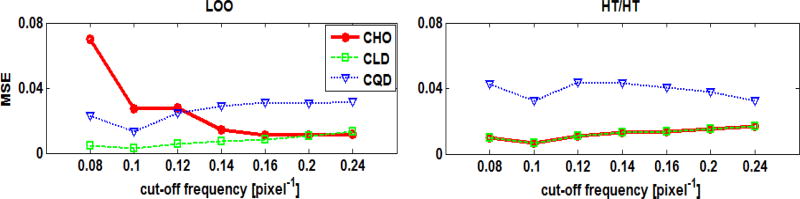
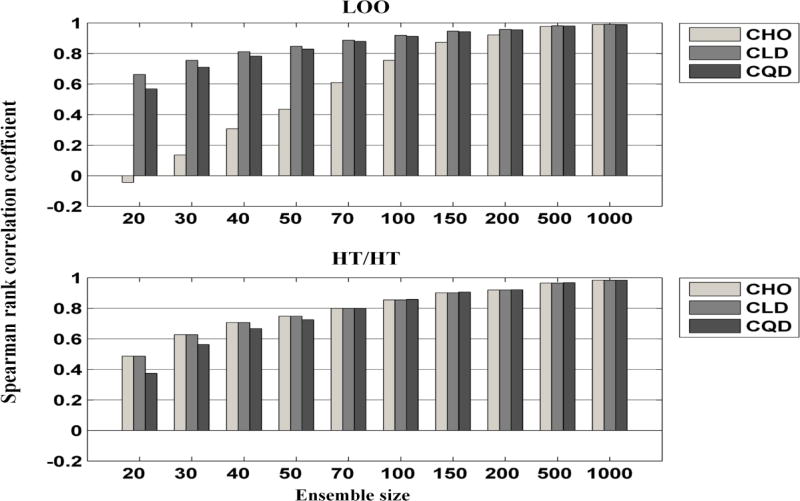
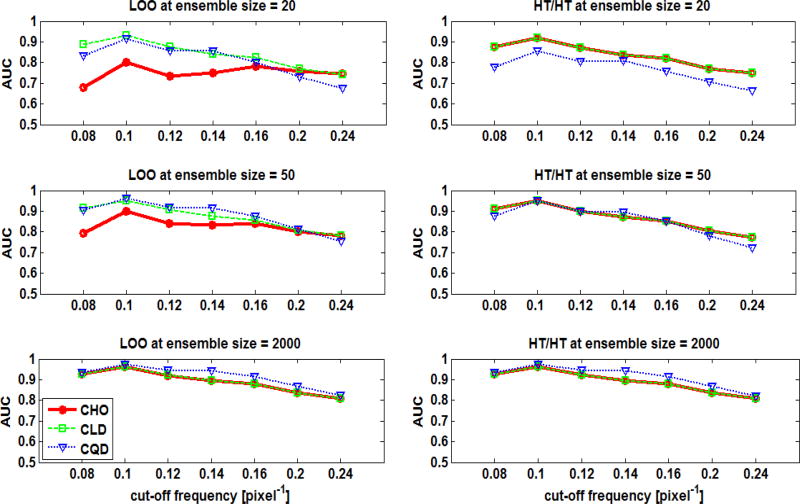
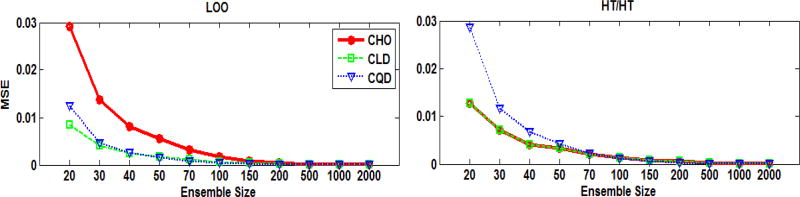
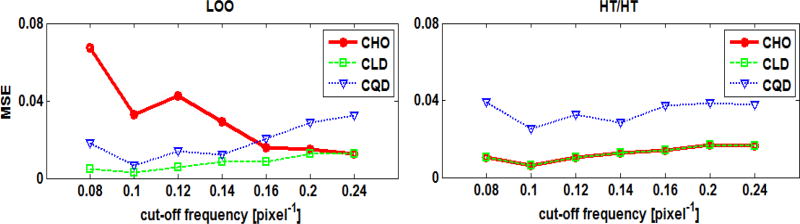
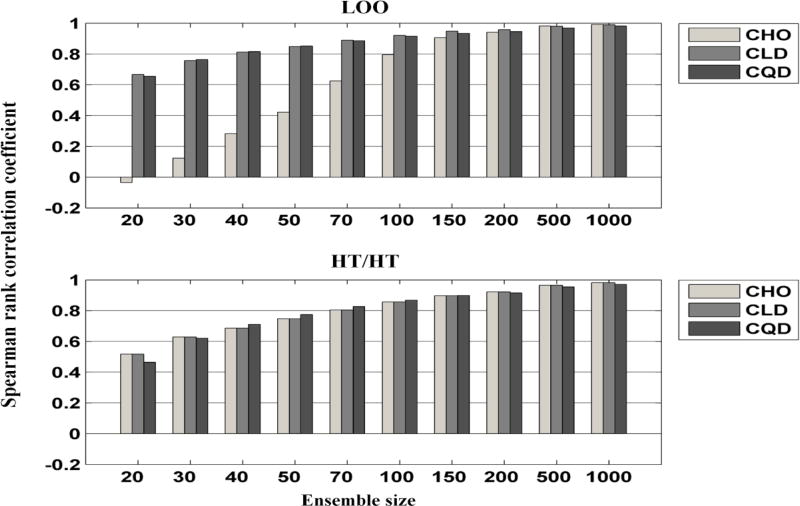
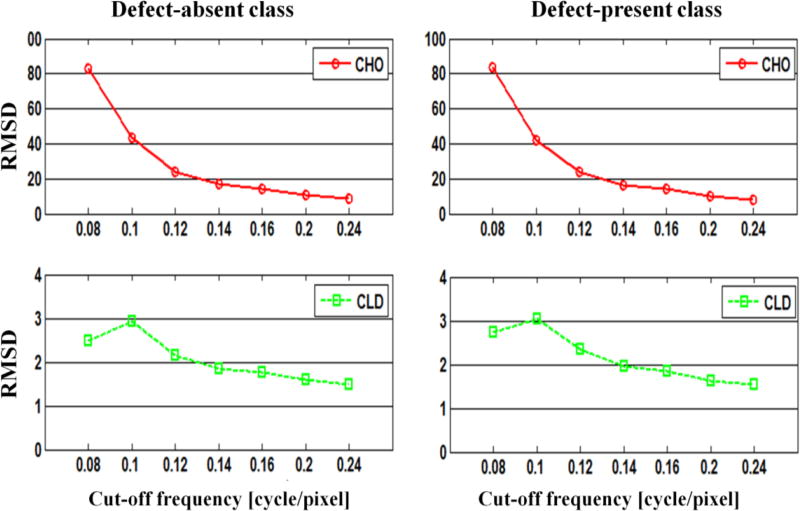
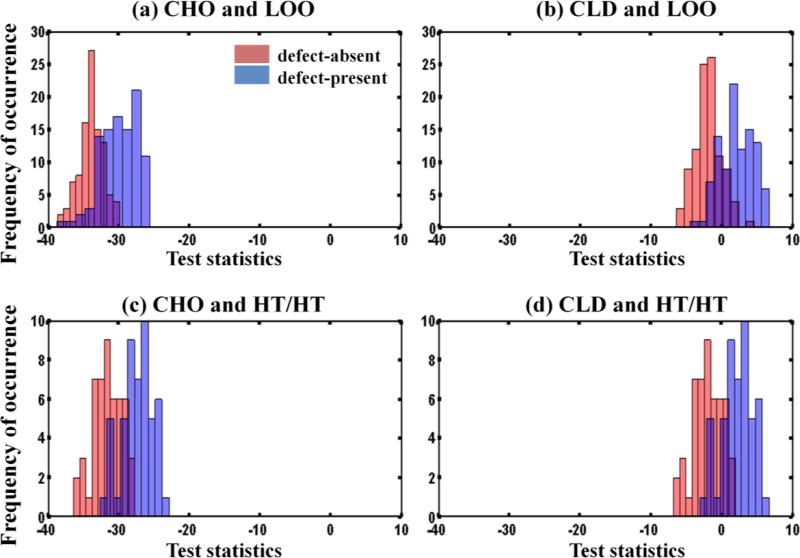
In objective assessment of image quality, an ensemble of images is used to compute the 1st and 2nd order statistics of the data. Often, only a finite number of images is available, leading to the issue of statistical variability in numerical observer performance. Resampling-based strategies can help overcome this issue. In this paper, we compared different combinations of resampling schemes (the leave-one-out (LOO) and the half-train/half-test (HT/HT)) and model observers (the conventional channelized Hotelling observer (CHO), channelized linear discriminant (CLD) and channelized quadratic discriminant). Observer performance was quantified by the area under the ROC curve (AUC). For a binary classification task and for each observer, the AUC value for an ensemble size of 2000 samples per class served as a gold standard for that observer. Results indicated that each observer yielded a different performance depending on the ensemble size and the resampling scheme. For a small ensemble size, the combination [CHO, HT/HT] had more accurate rankings than the combination [CHO, LOO]. Using the LOO scheme, the CLD and CHO had similar performance for large ensembles. However, the CLD outperformed the CHO and gave more accurate rankings for smaller ensembles. As the ensemble size decreased, the performance of the [CHO, LOO] combination seriously deteriorated as opposed to the [CLD, LOO] combination. Thus, it might be desirable to use the CLD with the LOO scheme when smaller ensemble size is available.
Figures


References
-
- Barrett HH, Myers KJ. Foudations of Image Science. New York: Wiley; 2004.
-
- Chan HP, Sahiner B, Wagner RF, Petrick N. Classifier design for computer-aided diagnosis: effects of finite sample size on the mean performance of classical and neural network classifiers. Med Phys. 1999;26:2654–68. - PubMed
-
- Daniel WW. Applied nonparametric statistics. Cengage Learning; 1990.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Research Materials